1.redis简介
redis是一款开源免费的高性能key-value数据库,redis特点:
- 支持更多的数据类型:字符串(String)、列表(List)、哈希(Map)、数字(Int)、集合(Set)、有序集合(sorted sets)。
- 为了保证效率,将数据保存在内存中。
- 周期性的将数据保存到磁盘。
- 支持数据备份,master-slave模式数据备份。
2.redis优势
- 性能高
- 原子性
- 丰富的数据类型
- 丰富的特性
3.API使用
- 连接方式
- 连接池方式
- 丰富的数据类型操作
- 管道
- 发布订阅
4.操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis #创建一个redis实例,获取一个新的连接 r = redis.Redis("127.0.0.1","6379") #以key-value的形式设置redis字符串数据 r.set("k1","v1") r.set("k2","v2") #获取存储的数据并输出 print(r.get("k1")) print(r.get("k2"))
5. 通过连接池 使用 redis
import redis #首先获取一个redis连接池 , 注意端口号不能使用字符串的方式 redisPool = redis.ConnectionPool(host="127.0.0.1",port=6379) #实例化一个redis实例,通过连接池 r = redis.Redis(connection_pool=redisPool) r.set("k1","v1") print(r.get("k1"))
6.字符串操作(String)
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数: ex,过期时间(秒) px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,岗前set操作才执行#set(name, value, ex=None, px=None, nx=False, xx=False) # r.set(name="k1",value="v1",ex=5) # print(r.get("k1")) 5秒后,get("k1") 为None r.set("k1","v1") r.set("k1","v1v1",nx=True) #如果redis中存在看,当前set操作无效 print(r.get("k1")) #v1
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs) 批量设置值
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) #一种是关键字的方式 r.mset(k1="v1",k2="v2") #另一种是打散字典 r.mset(**{"k3":"v3","k4":"v4","k5":"v5"}) print(r.get("k1")) print(r.get("k3"))
mget(keys, *args) : 批量获取值
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) #一种是关键字的方式 r.mset(k1="v1",k2="v2") #另一种是打散字典 r.mset(**{"k3":"v3","k4":"v4","k5":"v5"}) print(r.get("k1")) print(r.get("k3")) #批量获取就是 放一个容器包含需要获取的所有key print(r.mget("k1","k2","k3")) print(r.mget(["k1","k2","k3"])) print(r.mget(*["k1","k2","k3"])) print(r.mget(*("k1","k2","k3")))
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end):获取子序列
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.set("k1","Hello World") #从0开始到索引为2的位置,和python切片不同,它包含尾部元素 print(r.getrange("k1", 0, 2)) # Hel #0 -1 获取整个值的长度 print(r.getrange("k1", 0, -1))
setrange(name, offset, value)
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.set("k1","Hello World") #表示从0开始替换 123替换 Held的位置 r.setrange("k1",0,"123") print(r.get("k1"))#b'123lo World'
strlen(name) : 返回值的长度
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.set("k1","Hello World") print(r.strlen("k1")) #11
incr(self, name, amount=1)
# 自增 name对应的值
# 当name不存在时,则创建name=amount
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
# 注:同incrby
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.set("k1","1") # r.set("k1",1) 相同 print(r.get("k1")) #1 r.incr("k1",amount=1) print(r.get("k1")) #2
incrbyfloat(self, name, amount=1.0):同上,只是自增数是浮点数
decr(self, name, amount=1) : 自减对应的值,自增数是整数
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.set("k1","HelloWorld") print(r.get("k1")) #b'HelloWorld' r.append("k1","123") print(r.get("k1")) #b'HelloWorld123'
7.哈希的操作
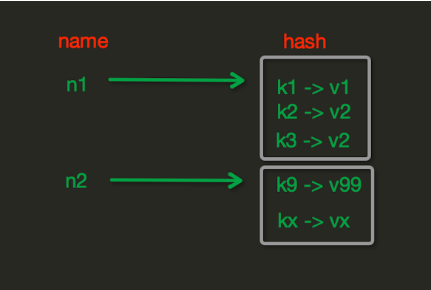
hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) """ { foo :{"k1":"v1"} } """ r.hset("foo","k1","v1") print(r.hget("foo","k1"))
hmset(name, mapping)
# 在name对应的hash中批量设置键值对 # 参数: # name,redis的name # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如: # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.hmset("foo",{"k1":"v1","k2":"v2","k3":"v3"}) print(r.hget("foo", "k1")) print(r.hget("foo", "k2")) print(r.hget("foo", "k3"))
hget和hmget : 获取的单个值,获取多个key对应的值
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) """ { foo:{ k1:v1, k2:v2, k3:v3 } } """ #批量添加多个值 r.hmset("foo",{"k1":"v1","k2":"v2","k3":"v3"}) #print(r.hget("foo", "k1")) #print(r.hget("foo", "k2")) #print(r.hget("foo", "k3")) print(r.hmget("foo", ["k1", "k2", "k3"])) #[b'v1', b'v2', b'v3']
hgetall(name)
获取name对应hash的所有键值
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.hmset("foo",{"k1":"v1","k2":"v2"}) print(r.hgetall("foo")) #{b'k1': b'v1', b'k2': b'v2', b'k3': b'v3'}
hlen(name):获取name对应的hash中键值对的个数
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.hmset("foo",{"k1":"v1","k2":"v2"}) print(r.hlen("foo")) #3
hkeys(name) 、 hvals(name)
hkeys(name) : # 获取name对应的hash中所有的key的值 hvals(name) : # 获取name对应的hash中所有的value的值
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) print(r.hkeys("foo")) #[b'k1', b'k2', b'k3'] print(r.hvals("foo")) #[b'v1', b'v2', b'v3']
hexists(name, key) : 检查name对应的hash是否存在当前传入的key
r.hmset("foo",{"k1":"v1","k2":"v2","k3":"v3"}) print(r.hmget("foo", ["k1", "k2", "k3"])) #[b'v1', b'v2', b'v3'] # 检查name中key是否存在 print(r.hexists("foo","k1")) #True
hdel(name,*keys) : 将name对应的hash中指定key的键值对删除
r.hmset("foo",{"k1":"v1","k2":"v2","k3":"v3"}) print(r.hmget("foo", ["k1", "k2", "k3"])) #[b'v1', b'v2', b'v3'] print(r.hexists("foo","k1")) # True r.hdel("foo","k1") print(r.hexists("foo","k1")) # False
hscan(name, cursor=0, match=None, count=None)
hscan可以实现分片的获取数据,并非一次性将数据全部获取完 # name,redis中name # cursor,游标(基于游标分批取获取数据) # match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如: # 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None) # 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None) # ... # 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name, match=None, count=None) 利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
# match,匹配指定key,默认None 表示所有的key # count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数data = r.hscan_iter(name="foo") # <generator object StrictRedis.hscan_iter at 0x0000018F93516620> for i in data: print(i)
8.List操作
list操作,在redis中List在内存中按照一个name对应一个List来存储
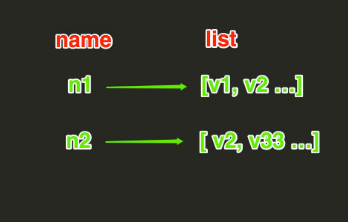
lpush(name,values):每个新的元素都添加到列表的最左边
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) r.lpush('oo',11,22,33) print(r.lrange("oo",0,-1)) # 33 22 11
# rpush(name, values) 表示从右向左操作
lpushx(name,value) : 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
llen(name): name对应的list元素的个数
import redis pool = redis.ConnectionPool(host="127.0.0.1",port=6379) r = redis.Redis(connection_pool=pool) # r.lpush('oo',11,22,33) print(r.lrange("oo",0,-1)) # 33 22 11 print(r.llen("oo")) # 3
linsert(name, where, refvalue, value))