python金融风控评分卡模型和数据分析微专业课(博主亲自录制视频):http://dwz.date/b9vv

1. 项目背景介绍
1.1 信用风险和评分卡模型的基本概念
信用风险指的是交易对手未能履行约定合同中的义务造成经济损失的风险,即受信人不能履行还本付息的责任而使授信人的预期收益与实际收益发生偏离的可能性,它是金融风险的主要类型。
借贷场景中的评分卡是一种以分数的形式来衡量风险几率的一种手段,也是对未来一段时间内违约、逾期、失联概率的预测。一般来说,分数越高,风险越小。
信用风险计量体系包括主体评级模型和债项评级两部分。其中主体评级模型包含以下四个方面内容:
- 申请者评级模型:主要应用于相关融资类业务中新用户的主体评级,适用于个人及机构融资主体。位于贷前准入环节。
- 行为评级模型:主要用于相关融资类业务中存量客户在续存期内的管理,如对客户可能出现的逾期、延期等行为进行预测,仅适用于个人融资主体。
- 催收评级模型:主要应用于相关融资类业务中存量客户是否需要催收的预测管理,仅适用于个人融资主体。
- 欺诈评级模型:主要应用于相关融资类业务中新客户可能存在的欺诈行为的预测管理,适用于个人和机构融资主体。 在贷前准入环节里面。
本项目主要针对申请者评分模型。
1.2 数据来源
本项目数据来源于kaggle竞赛Give Me Some Credit。
2. 信用卡评分模型开发
模型的构建主要包含以下几大部分内容:数据准备及数据预处理、变量选择、模型构建、模型验证、模型评估、模型部署、模型监控几大部分。下面一一讲述。
2.1 数据准备及数据预处理
2.1.1 获取数据
数据获取包括存量客户包括获取存量客户及潜在客户的数据。存量客户是指已经在证券公司开展相关融资类业务的客户,包括个人客户和机构客户;潜在客户是指未来拟在证券公司开展相关融资类业务的客户,主要包括机构客户,这也是解决证券业样本较少的常用方法,这些潜在机构客户包括上市公司、公开发行债券的发债主体、新三板上市公司、区域股权交易中心挂牌公司、非标融资机构等。
首先我们来观察现有的数据及指标。
本项目数据来源于kaggle竞赛Give Me Some Credit。其中训练数据共计15万条。
|
变量名 |
描述 |
类型 |
标号 |
|
|
SeriousDlqin2yrs |
超过90天或更糟的逾期拖欠 |
Y/N |
Y |
|
|
RevolvingUtilizationOfUnsecuredLines |
贷款以及信用卡可用额度与总额度比例 |
百分比 |
x0 |
|
|
age |
借款人当时的年龄 |
整型 |
x1 |
|
|
NumberOfTime30-59DaysPastDueNotWorse |
35-59天逾期但不糟糕次数 |
整型 |
x2 |
|
|
DebtRatio |
负债比率 |
百分比 |
x3 |
|
|
MonthlyIncome |
|
real |
x4 |
|
|
NumberOfOpenCreditLinesAndLoans |
开放式信贷和贷款数量,开放式贷款(分期付款如汽车贷款或抵押贷款)和信贷(如信用卡)的数量 |
整型 |
x5 |
|
|
NumberOfTimes90DaysLate |
|
整型 |
x6 |
|
|
NumberRealEstateLoansOrLines |
不动产贷款或额度数量:抵押贷款和不动产放款包括房屋净值信贷额度 |
整型 |
x7 |
|
|
NumberOfTime60-89DaysPastDueNotWorse |
60-89天逾期但不糟糕次数:借款人在在过去两年内有60-89天逾期还款但不糟糕的次数 |
整型 |
x8 |
|
|
NumberOfDependents |
家属数量:不包括本人在内的家属数量 |
整型 |
x9 |
2.1.2 数据预处理
通过python里的describe()函数可以浏览整份数据的大致情况:
如下图:
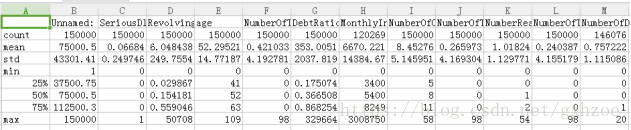
图 2.1
A. 缺失值处理
变量中如果有缺失值,针对缺失值有四种情况:
- 缺省值极多:若缺省值样本占总数比例极高,直接舍弃,因为作为特征加入反而会引入噪声值。
- 非连续特征缺省值适中:如果缺值的样本适中,而该属性非连续值特征属性,就把NaN作为一个新类别,加入到类别特征中。
- 连续特征缺省值适中:如果缺值的样本适中,考虑给定一个step,然后离散化,将NaN作为一个type加入到属性类目中。
- 缺省值较少:考虑利用填充的办法进行处理。其中有均值、众数、中位数填充;用sklearn里的RandomForest模型去拟合数据样本训练模型,然后去填充缺失值;拉格朗日插值法。
可以看出MonthlyIncome(月收入)及NumberOfDependents(家属数量)两个变量出现了缺失值。由于MonthlyIncome缺失值达到29731条数据,比例较大,因此不能直接将缺失值删除,选择随机森林法。而NumberOfDependents的缺失较少,对数据影响不大,因此直接删除。
使用dropna()函数删除空值,使用drop_duplicates()删除重复值。

B.异常值处理
缺失值处理完毕后,我们还需要进行异常值处理。异常值是指明显偏离大多数抽样数据的数值,比如个人客户的年龄大于100或小于0时,通常认为该值为异常值。找出样本总体中的异常值,通常采用离群值检测的方法。 离群值检测的方法有单变量离群值检测、局部离群值因子检测、基于聚类方法的离群值检测等方法。
在本数据集中,采用单变量离群值检测来判断异常值,采用箱线图。
对于age变量而言,我们认为大于100岁小于等于0岁的为异常值,由箱线图可知,异常值样本不多,故直接删除。
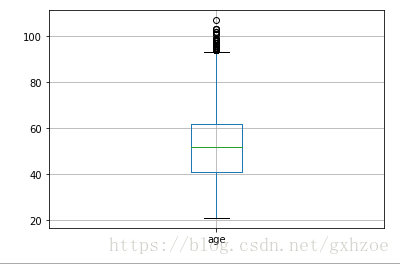
图 2.2
对于RevolvingUtilizationOfUnsecuredLines(可用额度比值)及DebtRatio(负债率)而言,箱线图如下图:
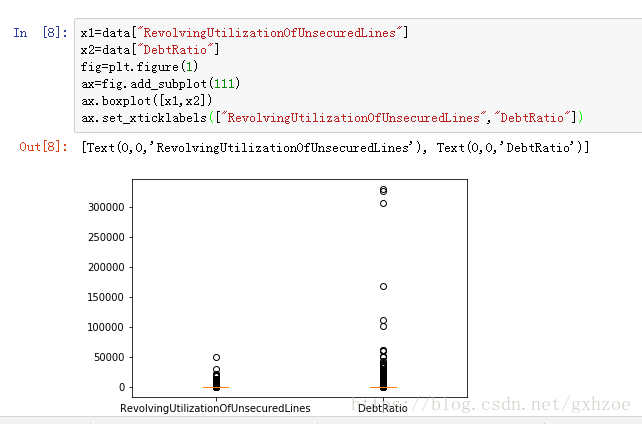
图 2.3
因为上述两变量的数值型为百分比,故大于1的值全部删除。
对于变量x2(逾期30-59天笔数)、x6(逾期90天笔数)、x8(逾期60-89天笔数做箱线图,由图可知,有两异常值点,数值为96、98,删除。
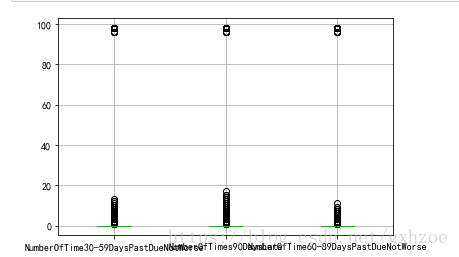
图 2.4
2.2 探索数据
探索数据主要是为了分析各变量对输出结果的影响,在本项目中,主要关注的是违约客户与各变量间的关系。
2.2.1 单变量分析
首先来观察好坏客户的整体情况。
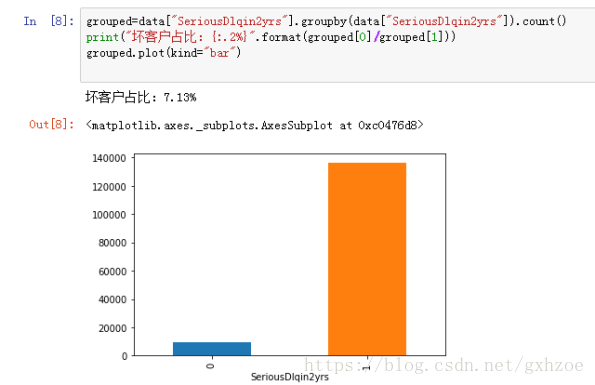
图 2.5
再看年龄对违约客户率的影响,由下图可知,违约客户率随着年龄增大而逐步下降。
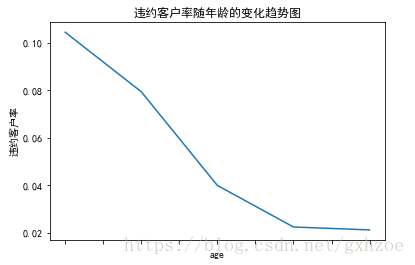
图 2.6
现在再来分析月收入对违约客户数量的影响,将月收入划分为以下几个级别:[0,5000],[5000,10000], [10000,15000],[15000,20000],[20000,100000].由下面两图可知,在20000收入之前随着收入增加,违约客户率递减,而当月收入大于20000后,违约客户率又随收入增高发生递增。
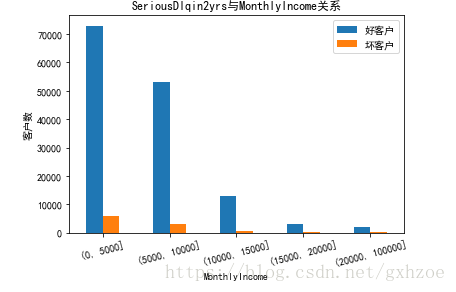
图 2.7
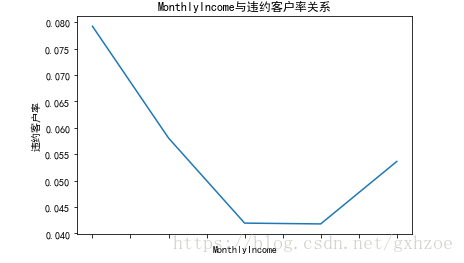
图 2.8
接下来我们再分析NumberOfDependents(家属数量)与最终输出结果之间的关系。可以看出随着家庭人口增多,违约客户率呈现递增的态势。
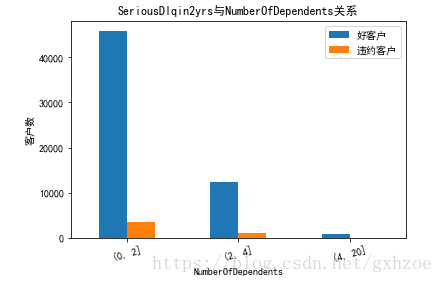
图 2.9
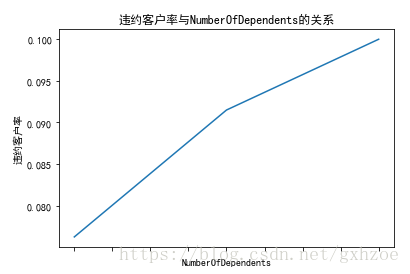
图 2.10
观察逾期30-59天次数与违约客户率之间的关系,可以看出随着违约次数增加,违约客户率呈现递增的态势。
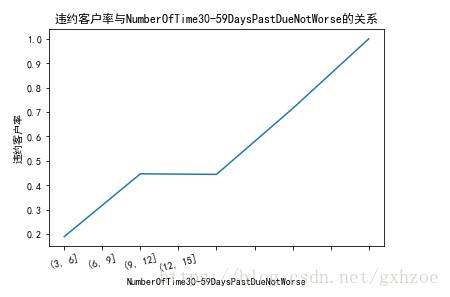
图 2.11
对数据的单变量分析就暂时处理到这里,剩余的变量也采取同样的方式进行分析。
2.2.2 多变量分析
多变量分析主要用于分析变量之间的相关的程度,python中可采用corr()函数计算各变量间的相关性。由图11知,各变量间相关性较小,不存在共线性可能。
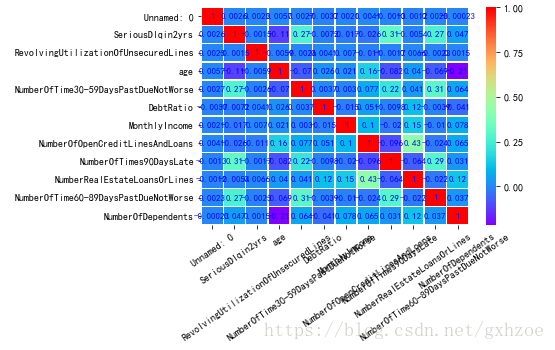
图 2.12
3. 构建模型
3.1特征选择
特征选择非常重要,好的特征能够构造出较好的模型,至于Python的变量选择代码实现可以参考结合Scikit-learn介绍几种常用的特征选择方法。在此,我们采用信用卡评分模型常用的IV值筛选。具体的IV值及WOE计算方法在下面这篇博文中有详细解释,此处就不再赘述。
3.1.1 特征分箱
特征分箱指的是将连续变量离散化或将多状态的离散变量合并成少状态。离散特征的增加和减少都很容易,易于模型的快速迭代,离散化后的特征对异常数据有很强的鲁棒性,能够减少未离散化之前异常值对模型的干扰,同时离散化后可以进行特征交叉。此外本文所选的模型算法为逻辑回归,逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入非线性,提升模型表达能力,加大拟合,同时也降低了模型过拟合的风险。
特征分箱常用的有以下几种方法:有监督的有Best-KS,ChiMerge(卡分分箱),无监督的包括等频、等距、聚类。根据数据特征,针对不同数据采用不同分箱方式。代码如下:

3.1.2 WOE值计算
定义WOE值并计算。

3.1.3 计算IV值
IV的全称是Information Value,中文意思是信息价值,或者信息量。图13为各变量的IV值。我们定义IV值低于0.2的特征为预测能力较弱或无关特征,因此将DebtRatio等五个变量删除。
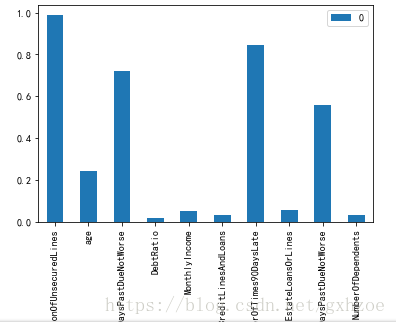
图 3.1
3.2 构造模型
3.2.1 WOE值替换
将筛选后的特征变量进行WOE转换,目的是减少逻辑回归的自变量处理量。
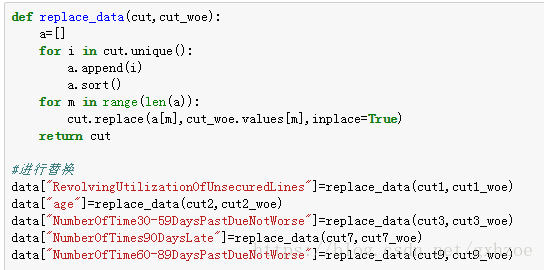
3.2.2 LR建模
采用sklearn里的linear_model 中的LogisticRegression()来构建模型。

4. 模型检验
利用测试集进行测试。看到ROC如下图:
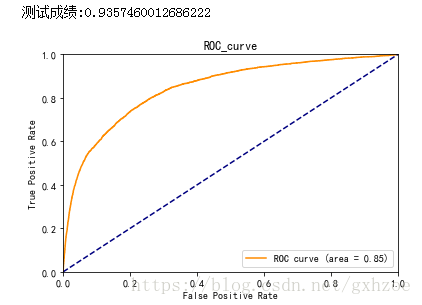
图 4.1
从上图可知,AUC值为0.85,说明该模型的预测效果还是不错的,正确率较高。
5. 信用评分
上面的模型的输出结果可以为每个客户的客户类别(好客户还是违约客户),也可以说出每个客户是好客户/违约客户对应的概率值。这种结果看起来不直观,我们需要把LR模型的结果值转化为对应的分数(0-999分)。

根据资料查得:
a=log(p_good/P_bad)
Score = offset + factor * log(odds)

得出各对应特征分组分数为:

图 5.1
在基础分数上对对应的分组分数加减,得出对应的评分,评分越高则违约风险越高。
6. 总结
本文通过对kaggle上的Give Me Some Credit数据的挖掘分析,结合信用评分卡的建立原理,从数据的预处理、变量选择、建模分析到创建信用评分,创建了一个简单的信用评分系统。本项目还有许多不足之处,比如分箱应当使用最优分箱或卡方分箱,减少人为分箱的随机性,此外模型采用的是逻辑回归算法,还可以多多尝试其他模型。
https://blog.csdn.net/gxhzoe/article/details/80428560转载
7. 参考文献
https://cloud.tencent.com/developer/article/1092230
