solr中文索引倒排索引和数据存储结构
传统的方式(正排索引)是从关键点出发,然后再通过关键点找到关键点代表的信息中能够满足搜索条件的特定信息,既通过KEY寻找VALUE。而Lucene的搜索则是采用了倒排索引的方式,即通过VALUE找KEY。而在中文全文搜索中VALUE就是我们要搜索的单词,存放所有单词的地方叫词典。KEY是文档标号列表(通过文档标号列表我们可以找到出现过要搜索单词VALUE的文档)
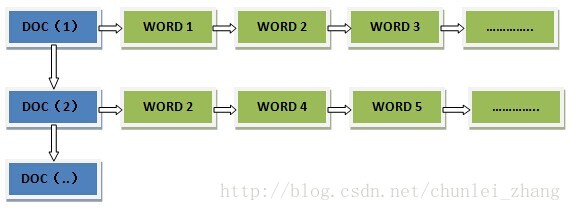
正排索引从文档编号找词:
倒排索引是从词找文档编号:
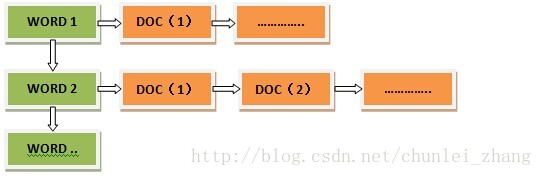
当文档数据来临时,solr会首先对文档数据进行分词,创建索引库和文档数据库。所谓的分词是指:将一段字符文索引本按照一定的规则分成若干个单词。如下面两篇文档通过solr后如何产生分词存储:

文章中的标点符号可以直接过滤掉,像and、too可以直接过滤掉。形成的分词表表示:

Lucene的倒排索引存储结构为:词项的字符串+词项的文档频率+记录词项的频率信息+记录词项的位置信息+跳跃偏移量。简单的理解可以形成以下结构:
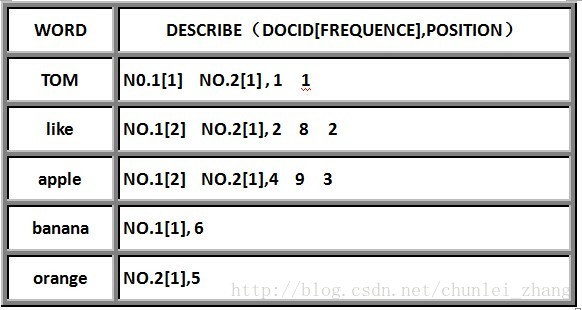
分别表示词,词出现的文档编号,文档中出现的频率和文档中出现的位置。这样当我们对词进行搜索时,会找到该词出现过的所有文档的ID,然后再通过该文档的ID寻找文档的具体内容。
当然,Lucene词典中词的顺序是按照英文字母的顺序排列的,这样就可以采用压缩存储:假设有term,termagancy,termagant,termina四个词。每个字母需要1byte的空间,常规存储一共需要35byte。而压缩存储之后为:"term4agancy8t4inal",一共需要22byte,节省大量的空间。
倒排索引结构
什么叫搜索引擎?
很多朋友认为lucene就是搜索引擎,其实这是不对的。既然是搜索引擎,那肯定是个应用。lucene是工具包,不搜索引擎。是Full-textserach library( 全文检索包),对于solr,Elastic Search(没用过这个搜索引擎,据说还是挺不错的等开源搜索引擎来说,搜索引擎就是为了lucene提供一个应用。目前为主:最为流行的基于 Java开源全文检索工具包。
一: 索引(index) 的定义
Lucene中基本的概念(fundamental concepts)是index、document、field(字段)和term(术语)
1、一个索引文件(index)包含了一连串的文档。
2、一个文档(document)是由一连串field(字段)s组成。 类似于数据库中的一条记录
3、一个字段是由一连串的term组成
4、一个term是一个字符串
备注:相同的字符串在不同的fields被认为是不同的term 。因此(thusterm被描述为(represent as一对字符串(a pair of strings,第一个string取名(naming为该field的名字,第二个string取名为包含在该field中的文本(text within the field。
二:倒排索引(索引核心)
index存储terms的统计数据,为了使得基于term的检索效率更高。相对于oracle中索引(B-TREE)结构,solr搜索引擎中采用的是一种倒排索引。 倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。
倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
下面理解倒排索引的一些术语:
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。
文档集合(Document Collection):由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
关于这些概念之间的关系,通过下图可以比较清晰的看出来。

倒排索引的原理:
假设文档集合包含五个文档,每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。

中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。在图中,“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表。比如单词“谷歌”,其单词编号为1,倒排列表为{1,2,3,4,5},说明文档集合中每个文档都包含了这个单词。
之所以说上图所示倒排索引是最简单的,是因为这个索引系统只记载了哪些文档包含某个单词,而事实上,索引系统还可以记录除此之外的更多信息。下面这张图是一个相对复杂些的倒排索引,与上图的基本索引系统比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。下图中,词“创始人”的单词编号为7,对应的倒排列表内容为:(3:1),其中的3代表文档编号为3的文档包含这个单词,数字1代表词频信息,即这个单词在3号文档中只出现过1次,其它单词对应的倒排列表所代表含义与此相同。
实用的倒排索引还可以记载更多的信息,索引系统除了记录文档编号和单词频率信息外,额外记载了两类信息,即每个单词对应的“文档频率信息”以及在倒排列表中记录单词在某个文档出现的位置信息。

“文档频率信息”代表了在文档集合中有多少个文档包含某个单词,之所以要记录这个信息,其原因与单词频率信息一样,这个信息在搜索结果排序计算中是非常重要的一个因子。而单词在某个文档中出现的位置信息并非索引系统一定要记录的,在实际的索引系统里可以包含,也可以选择不包含这个信息,之所以如此,因为这个信息对于搜索系统来说并非必需的,位置信息只有在支持“短语查询”的时候才能够派上用场。
以单词“拉斯”为例,其单词编号为8,文档频率为2,代表整个文档集合中有两个文档包含这个单词,对应的倒排列表为:{(3;1;<4>),(5;1;<4>)},其含义为在文档3和文档5出现过这个单词,单词频率都为1,单词“拉斯”在两个文档中的出现位置都是4,即文档中第四个单词是“拉斯”。
简单总结:倒排索引它记录的是词,和词所存在的文档id。的所有列表。通过这种索引结构的存储方式,其查询速率可想而知。
3:Lucene创建索引的过程是什么?
- 收集待索引的原文档
从数据库、web等获取原文档。
-
将原文档交给分词组件(Tokenizer)
此过程叫做Tokenize,得到的结果称为Token。
会做如下几件事:
1.将文档分成一个个独立的单词
2.去除标点
3.去除停词(stopword)
-
将得到的Token交给语言处理组件(LinguisticProcessor)
此过程处理的结果是Term
会做如下几件事:
1.转为小写
2.将单词缩减为词根,如cars-->car
3.将单词转变为词根,如drove-->drive
-
将得到的Term交给索引组件(Indexer)
会做如下几件事:
1.将得到的Term创建字典
2.对字典按字母排序
3.合并相同的Term为倒排索引表