学习资源来自,一个哲学学生的计算机作业 (karenlyu21.github.io)
1、背景问题
我们可以用有向图表示一个节点对其他节点的认同,有向边i→j(A[i,j]=1)指的是,节点i认同节点j。
1.1、有向图的性质
方向性的存在意味着一系列新的性质:
| 无向图 | 有向图 | |
|---|---|---|
| n个节点的图的最大边数 | n(n−1)/2 | n(n−1) |
| 如果A到B的最短有向路径长度(距离)记为AB,A到C的最短有向路径长度记为AC,那么B到C的有向路径长度BC≤AB+AC | 对 | 错 |
- 如果一个有穷有向图中不存在有向环,则该图中既存在出度为0的节点,也存在入度为0的节点;
- 如果有一个节点,它与其他每个节点分别都有两个方向的路径,则图中所有节点对之间都有两个方向的路径(即该图为强连通图)。
强连通图指的是满足如下条件的节点子集及其节点之间的边构成的子图S:
- S中任何两个节点之间都有双向路径(长度可以大于1);
- S之外不再有任何节点,既可以经G中的有向路径到达S,也可以从S到达它。
若一个节点与任何其他节点都没有双向路径,则它自己构成一个强连通分量。
例如,下面这个有向图存在7个强连通分量:
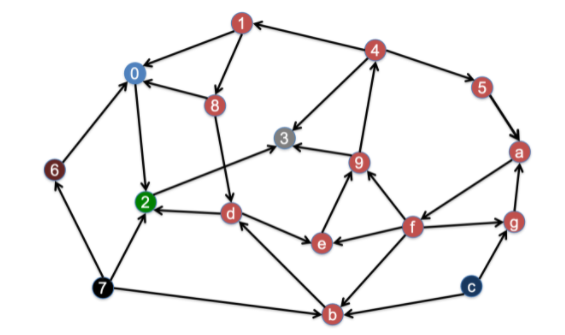
根据定义,可以通过广度优先搜索(BFS,见第三讲)找出有向图中的强连通分量:先用BFS找出节点x沿出向边所能到达的节点集合为F,再找出沿入向边能到达x的节点集合为B,则F∩B就是包含x的强连通分量。
1.2、“重要性”评估: PageRank
有向边意味着“认同”关系,入度越高的节点,观点越受社会网络中的其他人重视,重要性越高。为了进一步利用有向图来评估每一节点的重要性,我们设置如下的操作化条件:
- 考虑整个“社会网络”有一个总价值,等于所有人的价值之和。(因为人和人之间,这种价值的绝对值意义不大,有意义的是相对值。)
- 让“被认可”(或“被推荐”)体现的价值与“推荐人”的价值成正比,同时与推荐人推荐的人数成反比。
由于不同节点的价值之间相互关联和影响(“被认可”体现的价值与“推荐人”的价值成正比),我们可以解方程来求解,也可以设每一节点的初始价值为1/n(共n个节点),然后迭代进行节点价值的更新:利用前一轮里每一节点的价值、根据他们的相互推荐,计算下一轮里每一节点的价值,再重复这一操作。迭代算法被搜索引擎用来确定网页的排序,故称为PageRank,具体地,这是PageRank的基本更新算法。
基本更新算法无法合理处理某些特殊情况。例如吸血鬼节点:一个节点总是只指向自己、只把认同价值分给自己,与此同时吸收其他节点的认同价值(下方左图的节点x);或者,少数几个节点互相认同、在内部瓜分认同价值;与此同时吸收其他节点的认同价值(下方右图的节点x,y)。
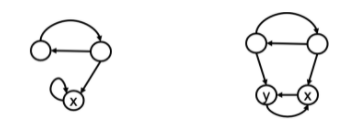
克服这种挑战的措施就是在迭代过程的每一轮,都做“同比缩减,等量补偿”——类比按收入的统一百分比交税,然后发等量救济款。每个节点得以平等地保有一些价值,避免了网络中的认同价值被少数几个吸血鬼节点吸纳。用一个占比因子s调控同比缩减的力度,0<s<1,通常选在0.85左右。
1.3、社会共识的形成: DeGroot Consensus
有向边意味着“认同”关系,如果节点i认同j,j的态度和观点可能对i有很大影响;因此,有向图中的“认同”网络还能用来模拟社会中观点之间的互相影响,这种互相影响可能导向社会共识。进一步的操作化算法如下:
- 公开每个人的当前表态(认识);
- 每个人用自己认为靠谱的人的均值更新自己的表态;
- 若稳定了就停止,否则回到 1。
2、计算实践:网络中影响力与共识的关系
2.1、作业描述与算法思路
社会共识形成的算法迭代进行观点的更新。对于已稳定下来的情况,直观上我们会认为,社会共识与每个节点的影响力或PageRank有关系,共识应当接近影响力大的人的观点。
具体地,用向量p→=(p1,p2,…,pn)表示每个节点的PageRank,用s→=(s1,s2,…,sn)表示每个节点的观点初值,用数值c表示DeGroot共识的结果。三者之间其实有如下关系:
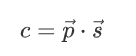
这一理论能在数学上得到证明。本次作业是在一个例子模型中编程验证这一理论:
- 输入一个合适的有向图邻接矩阵A、一个认识初值向量s→;
- 程序首先根据S,按照DeGroot模型得到共识值c,再以节点初值1/n算得采用基本更新算法下的PageRank向量p→;
- 验证c=p→⋅s→的关系是否成立。
PageRank算法中价值的更新和DeGroot算法中观点的更新,都涉及矩阵向量乘法。以如下的认同有向图A为例,

PageRank算法中更新节点价值时,由于一条认同边的价值与“推荐人”的推荐数成反比,我们要先对矩阵行做归一化,每一行总和值为1。归一化后的值意味着,每个“推荐人”的推荐数越多,单个推荐的价值就越低。
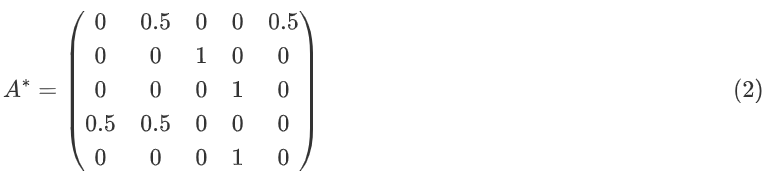
第i轮迭代中,每个节点有一当前价值,

把v→(推荐人的价值)与A∗的列i(推荐人的分量)做点乘,就可以得到节点i的新价值。这意味着我们需要转置(转换行列)v→i和A∗,再把二者做点乘就能得到新的PageRank v→i+1:
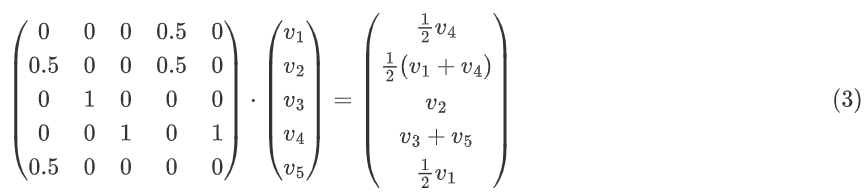
在DeGroot算法中,每个节点更新自己的观点时,要把自己认同的人的观点做加权平均,这也意味着我们需要把矩阵A标准化为A∗,这一步同(1)→(2)。标准化后的值意味着,认可k个人的节点i,其中一个被认同者j对i的影响是1/k。
把s→(被认同者的观点值)与A∗里的第i行(被认同者对节点i的影响分量)做点乘,就可以得到节点i的新观点值。具体操作矩阵向量乘法时,我们只需转置s→:
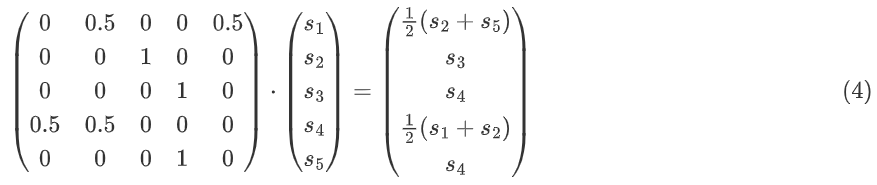
迭代进行以上两个矩阵向量乘法,直到稳定。
2.2、编程实现与要点说明
首先仍然是读取有向图文件,存储在矩阵A里,读取初始观点向量,存储在向量S里。(矩阵数据在完整代码中)
# 从文件中读取矩阵
def arrayGen(filename):
f = open(filename, 'r')
r_list = f.readlines()
f.close()
array_nl = []
for line in r_list:
if line == '\n':
continue
line = line.strip('\n')
line = line.strip()
row_list = line.split()
for k in range(len(row_list)):
row_list[k] = row_list[k].strip()
row_list[k] = int(row_list[k])
array_nl.append(row_list)
nx = len(array_nl[0])
ny = len(array_nl)
array = np.array(array_nl)
return array, nx, ny
# 请求输入文件名称
while True:
filename = input('请输入有向图邻接矩阵文件名称(e.g. net1.txt, net2.txt):')
pathname = os.path.join('./input',filename)
try:
A, nx, ny = arrayGen(pathname)
except:
print('输入错误!', end = '')
continue
break
print('有向图:')
print(A)
# 请求输入文件名称
while True:
filename = input('请输入认识初值向量文件名称(e.g. s1.txt, s2.txt):')
pathname = os.path.join('./input', filename)
try:
S, n = vecGen(pathname)
except:
print('输入错误!', end='')
continue
break
print('初始观点向量:', end='')
print(S)
接着,我们来标准化矩阵,存储为A_sd。
# 标准化矩阵
A_sd = np.zeros((ny,nx))
for i in range(ny):
row = A[i]
recognition_sum = np.sum(row)
A_sd[i] = row / recognition_sum
迭代计算DeGroot共识。如思路中所述,我们应该转置S,再把A_sd和它做点乘。但是,为了书写的简便(主要是便于后面计算PageRank时书写方便),我没有转置S,而是转置了A_sd、得到A_trans,并且把向量S放在了左边、矩阵A_trans放在了右边。这样计算得到的结果是一样的。不过,严格按照数学中矩阵向量乘法的规定,还是应该如上操作。
# DeGroot
# 变换横纵轴
A_trans = np.transpose(A_sd)
S_initial = np.copy(S)
在每一轮,我们点乘S_original和A_trans,得到新的观点结果S。
cnt = 0
while True:
cnt += 1
S_original = np.copy(S)
S = np.dot(S, A_trans)
比较更新前后的观点向量,如果每一维度的值前三位小数不发生变化,我们就认为观点的迭代更新达成了稳定。
# 检验是否达成稳定
flag = True
for i in range(n):
s_original = '%.3f' % S_original[i]
s = '%.3f' % S[i]
if s_original != s:
flag = False
if flag == True:
break
S_output = ['%.3f' % s for s in S]
print('*** DeGroot 共识结果:')
print(np.array(S_output))
*** DeGroot 共识结果:
['11.858' '11.858' '11.858' '11.858' '11.858' '11.858' '11.858' '11.858'
'11.858' '11.858' '11.858' '11.858' '11.858' '11.858' '11.858' '11.858'
'11.858' '11.858' '11.858' '11.858']
迭代计算PageRank。如前所述,我们应该转置A_sd和V,再把二者做点乘。但是,为了书写的简便,我没有做转置,而是把向量V放在了左边、矩阵A_sd放在了右边做点乘。
# PageRank
V = np.array([1/n for i in range(n)])
cnt = 0
while True:
cnt += 1
V_original = np.copy(V)
V = np.dot(V, A_sd)
比较更新前后的价值向量,如果每一维度的值前五位小数不发生变化,我们就认为价值的迭代更新达成了稳定。之所以两次判定稳定所取的小数位数不同,是因为,小数位数相同时,价值向量的有效位数比观点向量更少。
# 检验是否达成稳定
flag = True
for i in range(n):
v_original = '%.5f' % V_original[i]
v = '%.5f' % V[i]
if v_original != v:
flag = False
if flag == True:
break
print('*** PageRank: ')
V_output = ['%.3f' % v for v in V]
print(np.array(V_output))
*** PageRank:
['0.032' '0.038' '0.051' '0.038' '0.061' '0.062' '0.053' '0.004' '0.174'
'0.056' '0.012' '0.030' '0.021' '0.043' '0.013' '0.123' '0.078' '0.036'
'0.017' '0.059']
最后,我们使用PageRank对初始观点加权求和np.dot(V,S_initial):
# 使用PageRank对初始观点加权求和
consensus = np.dot(V,S_initial)
print('*** PageRank 加权初值求和结果:%.3f' % consensus)
*** PageRank 加权初值求和结果:11.858
基于PageRank算法得到的社会共识与DeGroot共识一致,本作业的理论假设得到了检验。
3、完整代码
网络中影响力与共识的关系
import numpy as np
import os
print('Initiating...')
# 从文件中读取矩阵
def arrayGen(filename):
f = open(filename, 'r')
r_list = f.readlines()
f.close()
array_nl = []
for line in r_list:
if line == '\n':
continue
line = line.strip('\n')
line = line.strip()
row_list = line.split()
for k in range(len(row_list)):
row_list[k] = row_list[k].strip()
row_list[k] = int(row_list[k])
array_nl.append(row_list)
nx = len(array_nl[0])
ny = len(array_nl)
array = np.array(array_nl)
return array, nx, ny
# 请求输入文件名称
while True:
filename = input('请输入有向图邻接矩阵文件名称(e.g. net1.txt, net2.txt):')
pathname = os.path.join('./input', filename)
try:
A, nx, ny = arrayGen(pathname)
except:
print('输入错误!', end='')
continue
break
print('有向图:')
print(A)
# 从文件中读取向量
def vecGen(filename):
f = open(filename, 'r')
value_list = f.readlines()
f.close()
for i in range(len(value_list)):
value = value_list[i]
value = value.strip()
value = int(value)
value_list[i] = value
value_array = np.array(value_list)
return value_array, len(value_array)
# 请求输入文件名称
while True:
filename = input('请输入认识初值向量文件名称(e.g. s1.txt, s2.txt):')
pathname = os.path.join('./input', filename)
try:
S, n = vecGen(pathname)
except:
print('输入错误!', end='')
continue
break
print('初始观点向量:', end='')
print(S)
# 标准化矩阵
A_sd = np.zeros((ny, nx))
for i in range(ny):
row = A[i]
recognition_sum = np.sum(row)
A_sd[i] = row / recognition_sum
# DeGroot
# 变换横纵轴
A_trans = np.transpose(A_sd)
S_initial = np.copy(S)
# print('S_initial:')
# print(S_initial)
cnt = 0
while True:
cnt += 1
S_original = np.copy(S)
S = np.dot(S, A_trans)
# if cnt == 1:
# print(A_trans, end ='')
# print(' * ', end ='')
# print(S_original, end = '')
# print('= ', end = '')
# print(S)
# 检验是否达成稳定
flag = True
for i in range(n):
s_original = '%.3f' % S_original[i]
s = '%.3f' % S[i]
if s_original != s:
flag = False
if flag == True:
break
S_output = ['%.3f' % s for s in S]
print('*** DeGroot 共识结果:')
print(np.array(S_output))
# PageRank
V = np.array([1/n for i in range(n)])
cnt = 0
while True:
cnt += 1
V_original = np.copy(V)
V = np.dot(V, A_sd)
# if cnt == 1:
# print(A_sd, end ='')
# print(' * ', end ='')
# print(V_original, end = '')
# print('= ', end = '')
# print(V)
# 检验是否达成稳定
flag = True
for i in range(n):
v_original = '%.5f' % V_original[i]
v = '%.5f' % V[i]
if v_original != v:
flag = False
if flag == True:
break
print('*** PageRank: ')
V_output = ['%.3f' % v for v in V]
print(np.array(V_output))
# 使用PageRank对初始观点加权求和
consensus = np.dot(V,S_initial)
print('*** PageRank 加权初值求和结果:%.3f' % consensus)
net1.txt
0 1 0 1 0
0 0 1 0 1
1 0 0 1 0
0 1 0 0 1
1 0 0 1 0
s1.txt
3
6
9
12
5
net2.txt
0 1 0 1 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0
0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0
1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 0 0 0
0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1
1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0
0 0 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 1 0 0
1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 0 0
0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0
0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0
0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 1 0 1 0 1
0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 1 0 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
s2.txt
5
32
2
4
5
10
21
3
2
6
8
3
1
9
23
45
2
3
9
11