原始数据:
1. 数据来源:
原始数据采用了中文通用百科知识图谱(CN-DBpedia)公开的部分数据, 包含900万+的百科实体以及6600万+的三元组关系。其中摘要信息400万+, 标签信息1980万+, infobox信息4100万+。
2. 数据格式
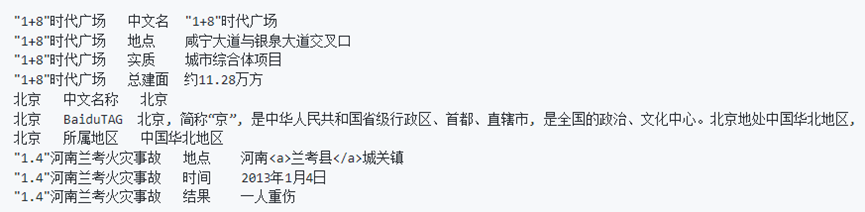
构建实体字典:
原始数据的每行第一个元素为实体, 根据正则表达式筛选全部为中文字符的实体, 转换为字典格式。
1. 将数据按行读入,并且存入data
2. 保留元素全为中文的三元组:

3. 构造实体字典

构造的数据格式如下:

将实体字典存储到 entities.pkl 文件中
将实体名称entities.keys(),去重,存入到entities.txt 文件中
获取句子集合、句子预处理:
实体的BaiduCard属性为实体的百度百科简介, 通常为多个句子。根据实体字典获取句子集合, 存为列表格式。
对所有句子进行预处理, 去除所有中文字符、中文常用标点之外的所有字符, 并对多个句子进行拆分, 存为列表格式。
1.

2.
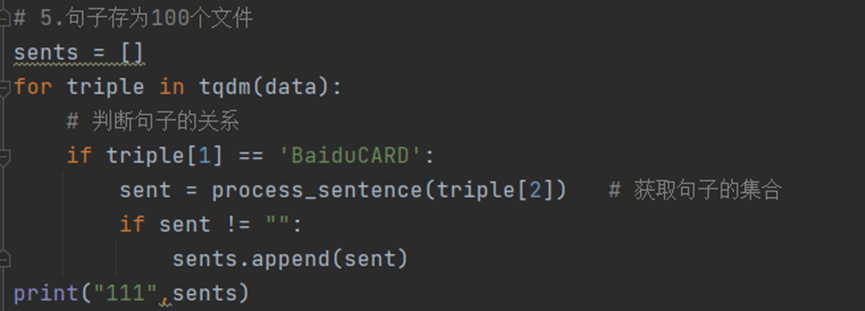
3. 处理后的数据格式如下:

4. 并且存储到sentences 文件下
句子匹配实体:
对每一个句子, 遍历实体集合, 根据字符串匹配保存所有出现在句子中的实体。过滤掉没有实体或仅有一个实体出现的句子, 数据处理为[[sentence, [entity1,...]], ...]的格式。
1. 将实体名称去重,并且存储在self.entities 中
将所有存储句子的文件名存储在 self.sentence_files 中

2. 使用进程池
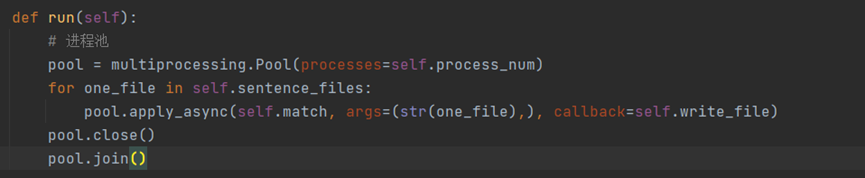
3. 进入match 函数,过滤掉没有实体或仅有一个实体出现的句子

由于data的数据格式如下,采用data[0] 的方式进行取值

数据格式如下

句子分词:
使用Python的jieba库进行中文分词, 对中文句子进行分词。将数据处理为[[sentence, [entity1,...], [sentence_seg]], ...]的格式。
收集所有分词后的句子, 作为语料库使用Python的word2vec库训练词向量。
1.对句子d[0]进行分词,并且将分词添加到 pkl 文件中
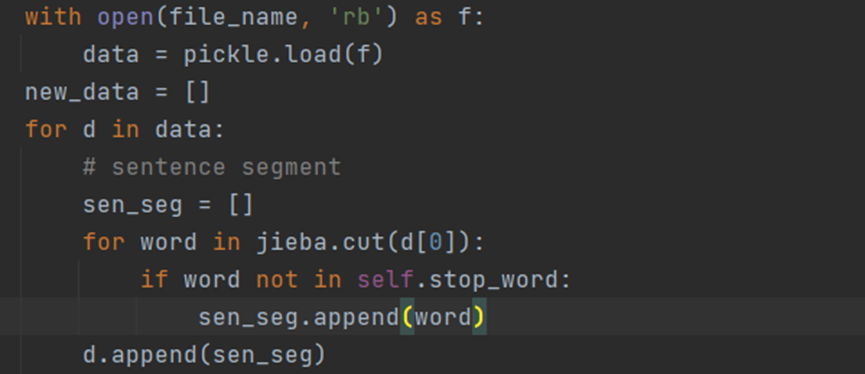
处理后的数据格式如下:

定义用户字典:
为防止实体被错误分词, 将所有实体(实体字典的键集合)写入到文件dict.txt作为用户字典
定义停用词:
定义文件stop_word.txt, 在分词过程中对句子去除中文停用词。(网上资源较多)
对分词后的句子重新对实体进行筛选, 对每一个句子的实体列表中的实体, 若其没有在分词后的句子中出现, 则去除该实体。 -- 进一步缩小实体的范围
句子、实体对筛选:
对筛选后的实体集合两两组合, 数据处理为[[sentence, entity_head, entity_tail, [sentence_seg]]]的格式。(一个句子可能被用于多个样本。)
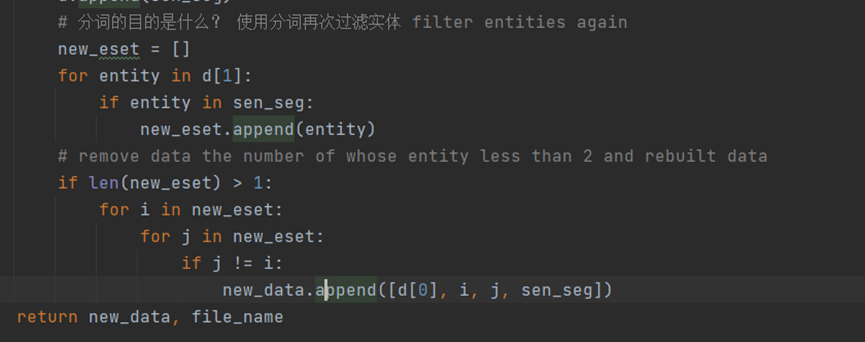
这里的匹配存在顺序反的情况,能够匹配更多的规则

数据格式如下

注:
此处先对句子匹配实体, 去除不符合条件的句子后然后分词, 再用分词后的句子匹配实体的主要原因是:
某些实体名称可能是另一实体的子集, 如“北京”和“北京大学”。在句子“北京大学是中国的著名大学。”中, 出现的实体应仅为“北京大学”。
分词时间较长, 不对句子进行初步筛选, 直接对所有句子先分词再匹配实体, 这样效率较低。
处理后数据格式如下:
添加关系标签:
根据对原始数据集的分析, 人工预定义了23种出现频率较高关系, 见附录1, 其中'NA'表示两实体没有关系或存在其他关系。同时, 原始数据中的关系/属性并没有对齐(如妻子、夫人对应同一种关系), 人工编写规则对关系对齐、聚合。
1. 数据的标注
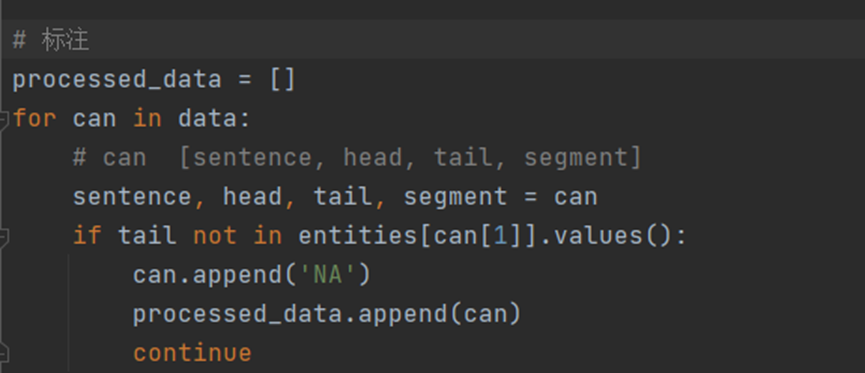
其中entities[can[1]] 为第二个大括号里面的内容
如果存在和尾实体相等的情况

如果尾实体存在于config当中,则对其key值进行拆分,使用tgs[tp[0]] 的方式判断tag 是否在句子当中,如果tgs[tp[1]]在句子当中,将name 的关系添加进来;如果tgs[tp[1]]不在句子当中,将name 的other关系添加进来
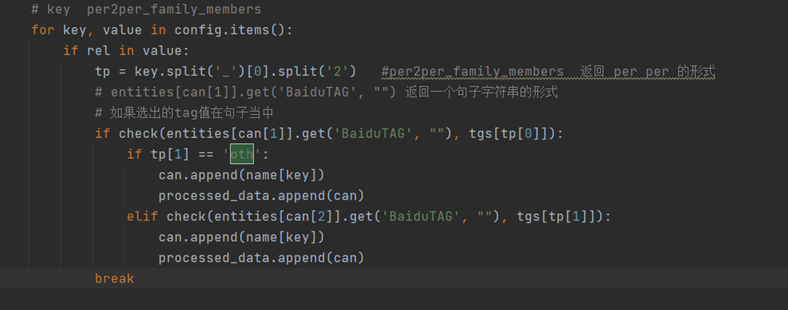
Name 属性值 如下
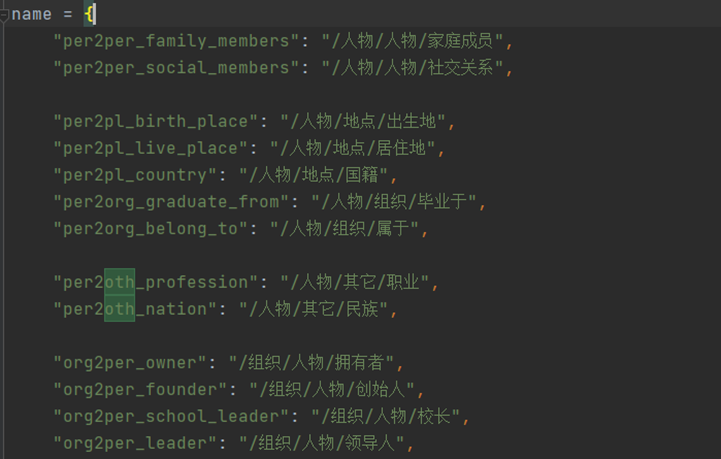
Config 的数据内容如下

数据格式如下:

数据集格式转换:
对数据进行格式转化, 并添加'id'、'type'或其它等等属性。数据处理为:
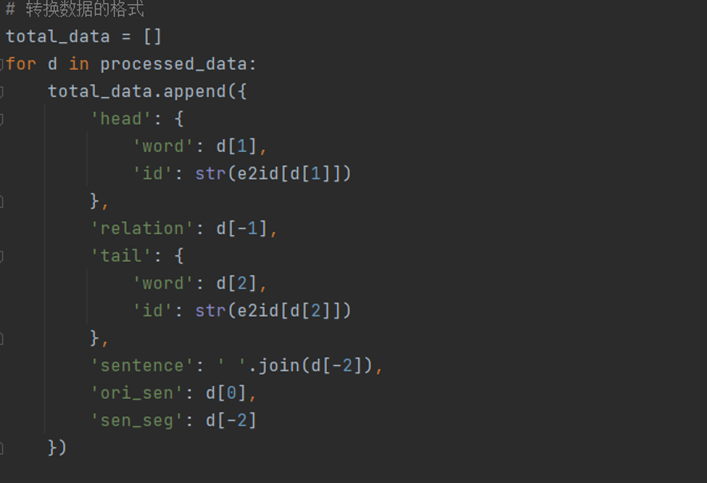
数据的格式如下:

划分训练集、测试集:
每种标签按照3:1的比例划分训练集、测试集。
一些问题:
1.句子较多, 匹配实体、分词、训练词向量时间较长(400W句子匹配8W实体, 使用8个线程约需1~2小时?), 建议先使用较少数据预测下运行时间, 使用多线程或者数据子集进行操作。
2. 部分数据清洗工作较为简单粗暴, 存在改进空间。
3. 关系种类较少, 关系对齐规则较为简单, 且原始数据中存在部分噪声(如BaiduTAG被错误分类), 数据集中存在噪声。