万级TPS亿级流水-中台账户系统架构设计
标签:高并发 万级TPS 亿级流水 账户系统
- 背景
- 业务模型
- 应用层设计
- 数据层设计
- 日切对账
背景
我们需要给所有前台业务提供统一的账户系统,用来支撑所有前台产品线的用户资产管理,统一提供支持大并发万级TPS、亿级流水、数据强一致、风控安全、日切对账、财务核算、审计等能力,在万级TPS下保证绝对的数据准确性和数据溯源能力。
注:资金类系统只有合格和不合格,哪怕数据出现只有0.01分的差错也是不合格的,局部数据不准也就意味着全局数据都不可信。
本文只分享系统的核心模型部分的设计,其他常规类的(如压测验收、系统保护策略-限流、降级、熔断等)设计就不做多介绍,如果对其他方面有兴趣欢迎进一步交流。
业务模型
基本账户管理: 根据交易的不同主体,可以分为个人账户、机构账户。
账户余额在使用上没有任何限制,很纯粹的账户存储、转账管理,可以满足90%业务场景。
子账户功能: 一个用户可以开通多个子账户,根据余额属性不同可以分为基本账户、过期账户,根据币种不同可以分为人民币账户、虚拟币账户,根据业务形态不同可以自定义。
(不同账户的特定功能是通过账户上的账户属性来区分实现。)
过期账户管理: 该账户中的余额是会随着进账流水到期自动过期。
如:在某平台充值1000元送300元,其中300元是有过期时间的,但是1000元是没有时间限制的。这里的1000元存在你的基本账户中,300元存在你的过期账户中。
注:过期账户的每一笔入账流水都会有一个到期时间。系统根据交易流水的到期时间,自动核销用户过期账户中的余额,记为平台的确认收入。
账户组合使用:支持多账户组合使用,根据配置的优先扣减顺序进行扣减余额。比如:在 基本账户 和 过期账户 (充值账户)中扣钱一般的顺序是优先扣减过期账户的余额。
应用层设计
根据上述业务模型,账户系统是一个典型的 数据密集型系统 ,业务层的逻辑不复杂。整个系统的设计关键点在于如何平衡大并发TPS和数据一致性。
热点账户:前台直播类业务存在热点账户问题,每到各种活动赛事的时候会存在 90%DAU 给少数几个头部主播打赏的场景。
DB就会有热点行问题,由于 行锁 关系并发一大肯定大量超时、RT突增 、 DB活跃线程 增加等一系列问题,最终DB会被拖挂。
账户类系统有一个特点,原账户的扣减可以实时处理,目标账户可以异步处理,我们可以将转账动作拆解为两个阶段进行异步化。(可以参考银行转账业务。)
比如:A给B转账100元,原账户A的100元余额扣减可以同步处理,B账户的100增加可以异步处理。这样哪怕10w人给主播打赏,这10w人的账户都是分散的,而主播的余额增加则是异步处理的。
账户转账扣减A账户余额,记录A账户出账流水,记录B账户入账流水,这三个动作可以在一个DBTransaction中处理,可以保证源账户进出帐一致性。目标账户B的入账可以异步处理,为了保证万无一失且满足一定的实时性,需要两步结合,程序里通过MQ走异步入账,同时增加DB的兜底JOB定时扫描 入账流水记录 为未到账的流水进行入账。
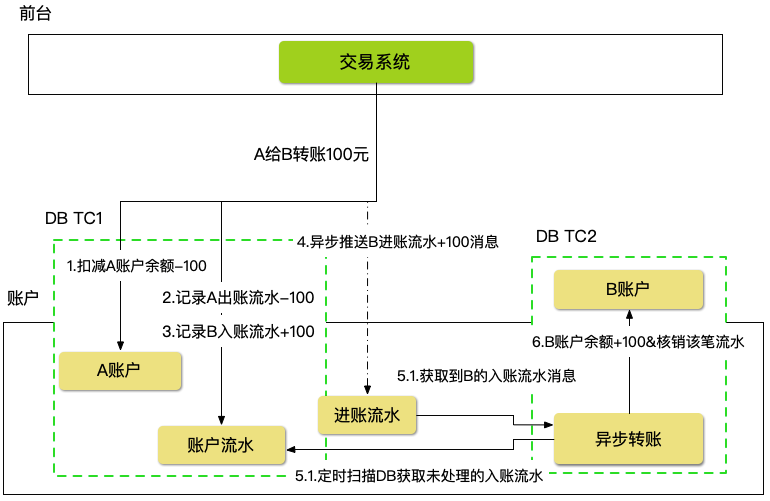
我们通过异步化缓解热点行处理,但是如果 收款方 强烈要求收款必须在一定的时间内完成,我们还是需要进一步处理,后面会讲到。
过期账户: 通常过期账户用来管理赠送类账户,这类账户有一定的时效性,用户在使用上也是优先扣减此类账户余额。
这类使用需求其实覆盖面不大,真正用户账户余额不使用等着被系统过期的很少,毕竟这是一个很傻的行为。
过期账户的两种核销情况:第一种是用户使用过期账户时的核销。第二种是某个过期流水到了过期时间,系统自动核销记为平台的确认收入。
过期账户核销逻辑:用户充值1000元到基本账户,平台赠送300元到赠送账户。此时,基本账户记录进账流水+1000元,赠送账户记录进账流水+300元并且该笔流水的过期时间为 2020-12-29 23:59:59 (过期时间由前台业务方设置) 。
系统自动核销:如果用户不在此时间之前用完就会被系统自动划进平台的收入,
赠送账户余额扣减-300元。
用户使用核销:如果用户在
过期时间前陆续在使用赠送账户,比如使用100元,那么我们需要核销原本进账的300元的那笔流水,减少-150元。
也就是说,该笔过期流水已经核销掉150元,带过期核销150元,到期后只要核销150元即可,而不是300元。
过期账户每次使用均产生待核销负向流水,系统自动核销前必须保证没有任何负向流水记录才可以去扣减赠送账户余额。

考虑到极端情况下,刚好过期JOB在进行自动过期核销,用户又在此时使用过期账户,这点需要注意下。可以简单通过加DB-X锁解决,这个场景其实非常稀少。
数据层设计
在应用层设计的时候,我们通过异步化方式来绕开热点问题。
同样我们在设计数据层的时候也要考虑单次操作DB的性能,比如控制事务的大小,事务跨网络的次数等问题。当然还包括金额存储的精度问题,精度问题处理不好也会影响性能。
浮点数问题: 如果我们用浮点数近似值来存储金额,那么就一定会有偏差,随着金额越大时间越长偏差就会越大。比较好的方式是通过整型来存储,通过放大金额比例来达到不同的业务场景下对金额比率的要求。
正常的1.12元,存储比率是1=100元,那么表里的存储值就是112,不同的货币比例都可以自由缩放,永远都可以保持最准确的精度。
分库分表+读写分离: 根据业务特点和未来增量规划,将DB分为16个逻辑库,前期使用2个物理库承载。16个逻辑库,按照每次2倍扩容,最大扩容上限是16个物理库。单实例的配置 8c 32g 2t 8000conn 9000iops 。
按照单次TPS-rt 1ms计算,TPS 1w 需求,每台承载5k TPS,单库的活跃线程大概在8-10个(考虑网络延迟)。
最后到达瓶颈的都是iops,因为只要rt足够短,最终压力都会在IO上。
分库按照uid分为16个库,账户表不分表默认16张。每张表按照 1kw*16=1.6 亿个账户。
单表能存储多少要综合考虑,比如查询类型,单次查询的RT,冷热数据占比( innodb_buffer_pool 利用率)、是否充分发挥了索引,索引是否达到3星级别,
索引片中没有经常变更的字段等。
账户流水表按照日期分表365张,流水数据会随着时间推移逐渐变成冷数据,定期归档冷数据。(这里约定了,流水查询只能按照uid+日期查询。如果运营类的需求,要横跨分片key获取,走OLAP方案 clickhouse、hive等)
分库分表采用阿里云分布式数据库产品DRDS,1个主库集群+2个读库集群(读库做了读负载均衡,可以按需扩容)。
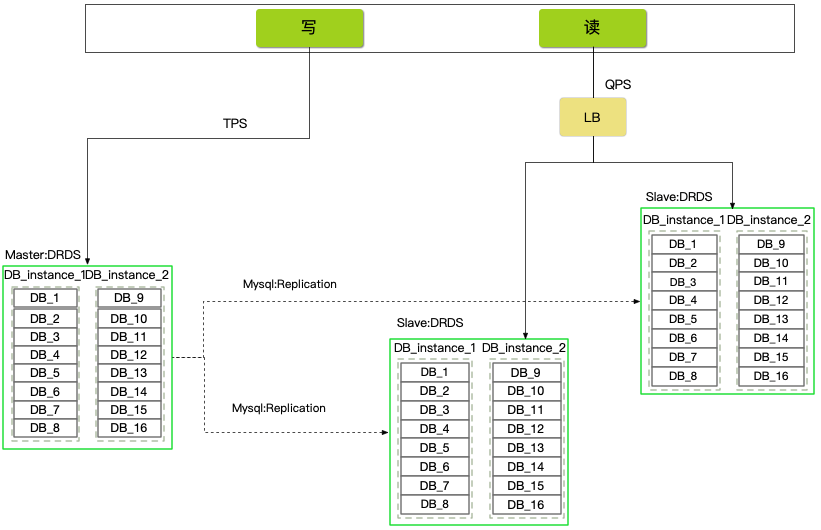
既然用了DRDS分布式数据库产品,那么在查询上需要充分考虑分片键的限制,如果存储和查询出现分片键冲突问题就需要我们手动计算分片路由,直接访问物理节点。
访问物理节点需要借助DRDS专用SQL注释子句来完成。
先通过 show node 查看物理DB ID、show topology from logic_table_name 查看物理表ID,然后在SQL带上特定的注释子句。
SELECT /*+TDDL:scan('logic_table_name', real_table=("real_table_name"),node='real_db_node_id')*/
count(1) FROM logic_table_name ;
账户更新: 对账户更新都有一个前提就是账户已经开通,但是我们为了最大化账户系统在使用上的便利性,让前台业务方不需要做初始化动作,由账户系统惰性初始化,比如发现账户不存在就自动初始化账户数据。
但是我们怎么知道账户不存在,不可能每次都去查询一次或者根据执行返回错误判断。而且 update 语句是区分不了错误的 账户不存在 还是 余额不足 或者其他原因。
那么如何巧妙的解决这个问题,只要一次DB往返。
我们可以使用 Mysql INSERT INTO ... ON DUPLICATE KEY UPDATE ... 子句,但是该子句有一个限制就是不支持 where 子句。
-- cut_version 乐观锁、account_property 账户属性
insert into tb_account(uid,balance,cut_version,account_property) values("%s",%d,%d,%d) ON DUPLICATE KEY UPDATE balance = balance + %d,cut_version = cut_version+1
其实不完全推荐使用这个方法,因为这个方法也有弊端就是将来 where 子句无法使用,还有一个办法就是合并 账户查询 和 插入 为一条 sql 提交。
DB操作本身rt可能很短,但是如果跨网络那么事务的延迟会带来DB的串行化增加,降低并发度,整体应用 rt就会增加。所以一个原则就是尽量不要跨网络开事务,合并sql做一次事务提交,最短的事务周期,减少跨网络的事务操作,如果我们将单次事务网络交互减少2-3次,性能的提高可能会增加2-3倍,同样由于网络的不稳定抖动丢包对 999rt 线的影响也会减少2-3倍。
平衡好当前系统是
业务密集型还是数据密集型。
判断当前系统是否有很强的业务层逻辑,是否要运用DDD、RUP等强模型的工程方法。毕竟强模型和高性能在落地的时候有些方面是冲突的,需要进一步借助CRQS、GRASP等工程方法来解决。
单行热点问题: 单行的TPS都是串行的,事务rt越短TPS就越高,按照1ms计算,差不多TPS就是1000。一般只有机构账户类型才会有这个需求。
我们可以将单行变成多行,增加行的并行度,加大账户操作的并发度。(这个方案要评估好写入和查询两端需求)
| id | uid | balance | slot |
|---|---|---|---|
| 1 | 10101010 | 1000 | 1 |
| 2 | 10101010 | 2000 | 2 |
| 3 | 10101010 | 3000 | 3 |
| 4 | 10101010 | 400 | 4 |
| 5 | 10101010 | 300 | 5 |
| 6 | 10101010 | 200 | 6 |
| 7 | 10101010 | 200 | 7 |
| 8 | 10101010 | 200 | 8 |
| 9 | 10101010 | 200 | 9 |
| 10 | 10101010 | 200 | 10 |
insert into tb_account (uid,balance,slot)
values(10101010, 1000, round(rand()*9)+1)
on duplicate key update balance=balance+values(balance)
这里的 10slot*单个slot 1000TPS,理论上可以跑到1w,如果机构账户数据量很大,可以扩展slot个数。
账户的总余额通过sum()汇总,如果业务场景中有余额的频繁sum()操作,可以通过增加余额中间表,定期 insert into tb_account_total select sum(balance) total_balance from tb_account group by uid 。
通常机构账户的结算是有周期的(T+7、T+30等),而且基本是没有并发,所以在账户余额扣减方面就可以轻松处理。
有两种实现方案:
第一种,账户余额允许单个slot为负数,但是总的sum()是正数。通过子查询来对余额进行检查。
insert into tb_account (uid, balance, slot)
select uid,-1000 as balance,round(rand() *9+ 1)
from(
select uid, sum(balance) as ss
from tb_account
where uid= 10101010
group by uid having ss>= 1000 for update) as tmp
on duplicate key update balance= balance+ values(balance)
第二种,如果条件允许可以借助用户自定义变量来在DB上完成余额累计扫描,将可以扣减的slot的主键id返回给程序,但是只需要一次DB交互就可以获取出可以扣减的账户solt,然后分别开始对slot账户进行扣减。
set @f:=0;
select * from tb_account where id in(select id from (select id, @f:=@f+balance from tb_account where @f<1000 order by id) as t);
第二种方案在默认的mysql数据库上都是支持的,但是有些数据库云产品不支持,阿里云rds是不支持的。
日切对账
账户系统有一个基本的需求,就是每天余额镜像,简单讲就是余额在每天的快照,用来做T+1对账。
不管财务还是每季度的审计都会需要,最重要的是我们自己也需要对账户数据做摸底对账。
由于每天产生上亿的流水,这需要在大数据平台中完成。
日切对账:
昨天账户余额-前天账户余额=昨天的流水-前天的流水。
比如,昨天的账户余额是5000w,前台的账户余额是4500w,差值就是500w。同样道理,昨天的账户流水是5000w,前天的账户流水是4500w,那么差值是500w,这就是没问题的。
账户不仅有增加也有减少,可能昨天账户余额比前天账户余额差值是-500w,但是流水也要是-500w才行。
由于每天会产生亿级的流水,用传统的全量抽取不现实,这类数据抽取的速度都会有延迟,而且对账最重要的是时间点必须非常精准,才能保证余额和流水是对得上的。
要不然会出现HDFS的分区是2020-06-10号,但是该分区里有2020-06-11的数据,就是因为拉取的时候会延迟到第二天。这个问题也可以通过增加拉取sql的条件限制来解决这个问题,但是无法做到0点瞬间镜像全部账户。
解决方案: 全量余额+binlog增量更新
1.账户表,先做一次全量同步。
2.DB的所有变更通过binlog(默认row复制)进到数仓。(因为 binlog 是基于发生时间的,所以无所谓我们是不是在0点去计算镜像)
3.T+1跑JOB的时候,获取前一天的账户余额,然后通过 binlog 来覆盖前天与昨天的交集部分。
由于数仓的 binlog 数据都是增量的,所以要想取到正确的全量数据需要用到一定的技巧。
select app_id,sub_type,sum(amount) records_amount from (
select *,row_number()over(partition by id order by updated_at) as rn
from hive_db_table
where dt='${YESTERDAY}'
) t where t.rn=1
group by t.sub_type,t.app_id
使用 hive 开窗函数 row_number()over() 对同样的id进行分组,然后获取最新的一条数据就是账户在T的最后的值。
作者:王清培(趣头条 Tech Leader)