一 全文检索介绍
先建立索引,再对索引进行搜索的过程就叫全文检索
搜索引擎核心:建立倒排索引
二 数据库和 solor搜索引擎对比
1 搜索引擎的索引和 数据库索引区别
原理相通,只是索引结构不同 一个是B+树,一个是倒排索引树
2 各自定位对比
数据库核心是数据存储和事务能力,在大数据量下搜索会很慢
搜索引核心是 专职建立索引使在大数据量下快速搜索, 并根据算法和 数据结构对查询结果进行相关性排序
一个是结构化数据 ,另一个是非结构化数据
三 全文检索流程图

四 创建索引过程
第一步:一些要索引的原文档(Document)。
为了方便说明索引创建过程,这里特意用两个文件为例:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
第二步:将原文档进行词法/语法分析 拆成一堆词。
文档拆成一个个词,大小写转换,去掉标点,时态处理等等
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
第三步:将得到的词(Term)传给索引组件(Indexer)。
索引 组件(Indexer)主要做以下几件事情:
1. 利用得到的词(Term)创建一个字典。
在我们的例子中字典如下:
| Term | Document ID |
| student | 1 |
| allow | 1 |
| go | 1 |
| their | 1 |
| friend | 1 |
| allow | 1 |
| drink | 1 |
| beer | 1 |
| my | 2 |
| friend | 2 |
| jerry | 2 |
| go | 2 |
| school | 2 |
| see | 2 |
| his | 2 |
| student | 2 |
| find | 2 |
| them | 2 |
| drink | 2 |
| allow | 2 |
2. 对字典按字母顺序进行排序。
| Term | Document ID |
| allow | 1 |
| allow | 1 |
| allow | 2 |
| beer | 1 |
| drink | 1 |
| drink | 2 |
| find | 2 |
| friend | 1 |
| friend | 2 |
| go | 1 |
| go | 2 |
| his | 2 |
| jerry | 2 |
| my | 2 |
| school | 2 |
| see | 2 |
| student | 1 |
| student | 2 |
| their | 1 |
| them | 2 |
3. 合并相同的词(Term) 成为文档倒排(Posting List) 链表。

在此表中,有几个定义:
- Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)。
至此索引创建完毕,下一步搜索过程
五 搜索过程
第一步:用户输入查询语句。
查询语句同我们普通的语言一样,也是有一定语法的。
不同的查询语句有不同的语法,如SQL语句就有一定的语法。
查询语句的语法根据全文检索系统的实现而不同。最基本的有比如:AND, OR, NOT等。
举个例子,用户输入语句:lucene AND learned NOT hadoop。
说明用户想找一个包含lucene和learned然而不包括hadoop的文档。
第二步:对查询语句进行词法分析,语法分析,及语言处理。
由于查询语句有语法,因而也要进行语法分析,语法分析及语言处理。
1. 词法分析主要用来识别单词和关键字。
比如关键字有AND, NOT等。
2. 语法分析主要是根据查询语句的语法规则来进行 或/与/非等逻辑判断。
3. 语言处理同索引过程中的语言处理几乎相同。
如learned变成learn等。
经过第二步,我们得到一棵经过语言处理的语法树。

第三步:搜索索引,得到符合语法树的文档。
此步骤有分几小步:
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
- 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
- 此文档链表就是我们要找的文档。
第四步:根据得到的文档和查询语句的相关性,对结果进行排序。
1. 计算权重(Term weight)的过程。
影响一个词(Term)在一篇文档中的重要性主要有两个因素:
- Term Frequency (tf):即此Term在此文档中出现了多少次。tf 越大说明越重要。
- Document Frequency (df):即有多少文档包含次Term。df 越大说明越不重要。
权重公式:
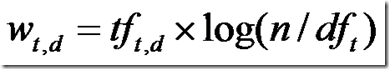

2. 判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
我们把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。
于是我们把所有此文档中词(term)的权重(term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
我们把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。
如图:

我们认为两个向量之间的夹角越小,相关性越大。
相关性打分公式如下:

举个例子,查询语句有11个Term,共有三篇文档搜索出来。其中各自的权重(Term weight),如下表格。
|
|
t1 |
t2 |
t3 |
t4 |
t5 |
t6 |
t7 |
t8 |
t9 |
t10 |
t11 |
|
D1 |
0 |
0 |
.477 |
0 |
.477 |
.176 |
0 |
0 |
0 |
.176 |
0 |
|
D2 |
0 |
.176 |
0 |
.477 |
0 |
0 |
0 |
0 |
.954 |
0 |
.176 |
|
D3 |
0 |
.176 |
0 |
0 |
0 |
.176 |
0 |
0 |
0 |
.176 |
.176 |
|
Q |
0 |
0 |
0 |
0 |
0 |
.176 |
0 |
0 |
.477 |
0 |
.176 |
于是计算,三篇文档同查询语句的相关性打分分别为:
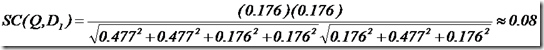

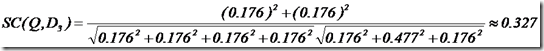
于是文档二相关性最高,先返回,其次是文档一,最后是文档三。
到此为止,我们可以找到我们最想要的文档了。