以下内容为参考慕课中厦门大学林子雨“大数据技术原理与应用”课程中提供的教程(链接:http://dblab.xmu.edu.cn/blog/install-hadoop/),以及自己在安装配置过程中遇到的一些问题百度到的方法,自行整理。
64位Ubuntu LTS 14.04的下载地址:http://www.ubuntukylin.com/downloads/download.php?id=38
在虚拟机中装好Ubuntu系统后,登录进去
创建Hadoop用户
如果安装Ubuntu的时候不是用的“hadoop”用户,那么需要增加一个名为hadoop的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :

这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:

可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:

最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:

过程中若出现unable to lock the administration directory(/var/lib/dpkg)错误,参看https://linux.cn/article-8040-1.html 此篇文章解决。
后续需要更改一些配置文件,我此处用的vim,

安装软件时若需要确认,在提示处输入 y 即可。
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:

安装后,可以使用如下命令登陆本机:

若出现connect to host localhost port 22:connection refused错误,参看https://www.xuebuyuan.com/733655.html 此篇文章。
处理完成后,此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
安装Java环境
Java环境可选择 Oracle 的 JDK,或是 OpenJDK,这边直接通过命令安装 OpenJDK 。

上述安装过程需要访问网络下载相关文件,请保持联网状态。安装结束以后,需要配置JAVA_HOME环境变量,请在Linux终端中输入下面命令打开当前登录用户的环境变量配置文件.bashrc:

在文件最前面添加如下单独一行(注意,等号“=”前后不能有空格),然后保存退出:
export JAVA_HOME=/usr/lib/jvm/default-javavim简单操作指南
vim的常用模式有分为命令模式,插入模式,可视模式,正常模式。本教程中,只需要用到正常模式和插入模式。二者间的切换即可以帮助你完成本指南的学习。
- 正常模式
正常模式主要用来浏览文本内容。一开始打开vim都是正常模式。在任何模式下按下Esc键就可以返回正常模式 - 插入编辑模式
插入编辑模式则用来向文本中添加内容的。在正常模式下,输入i键即可进入插入编辑模式 - 退出vim
如果有利用vim修改任何的文本,一定要记得保存。Esc键退回到正常模式中,然后输入:wq即可保存文本并退出vim
接下来,要让环境变量立即生效,请执行如下代码:

执行上述命令后,可以检验一下是否设置正确:
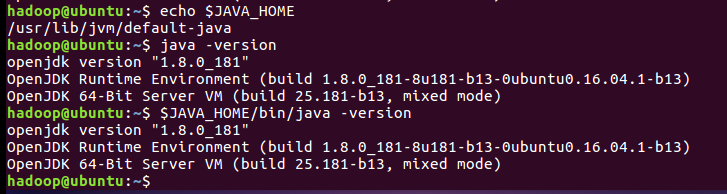
至此,就成功安装了Java环境。
安装hadoop
Hadoop 2 可以通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者 http://mirrors.cnnic.cn/apache/hadoop/common/ 下载,一般选择下载最新的稳定版本,即下载 “stable” 下的 hadoop-2.x.y.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
使用虚拟机方式安装Ubuntu系统的用户,请用虚拟机中的Ubuntu自带firefox浏览器访问本指南,再点击下面的地址,才能把hadoop文件下载虚拟机ubuntu中。请不要使用Windows系统下的浏览器下载,文件会被下载到Windows系统中,虚拟机中的Ubuntu无法访问外部Windows系统的文件,造成不必要的麻烦。
下载完 Hadoop 文件后一般就可以直接使用。但是如果网络不好,可能会导致下载的文件缺失,可以使用 md5 等检测工具可以校验文件是否完整。
我们选择将 Hadoop 安装至 /usr/local/ 中:




Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
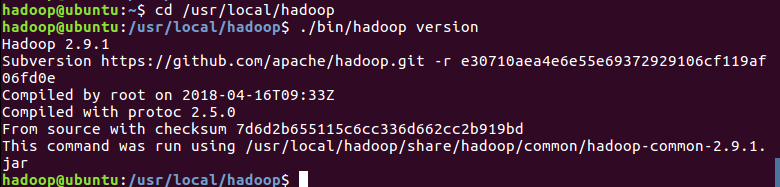
Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
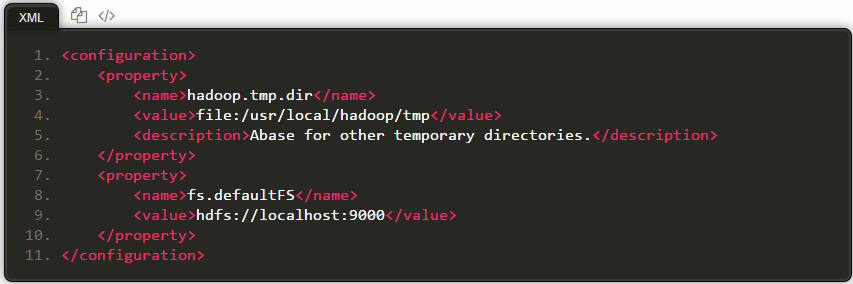
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
修改为下面配置:
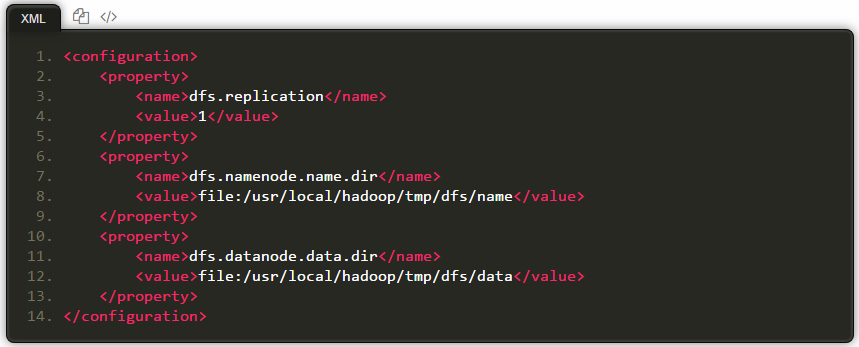
同样的,修改配置文件 hdfs-site.xml:
我用vim修改:
Hadoop配置文件说明
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:

成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
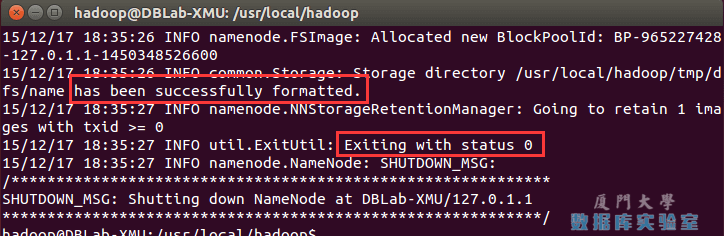
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。如果已经按照前面教程在.bashrc文件中设置了JAVA_HOME,还是出现 Error: JAVA_HOME is not set and could not be found. 的错误,那么,请到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,然后,再次启动Hadoop。
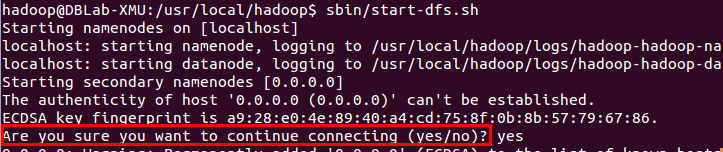
接着开启 NameNode 和 DataNode 守护进程。

若出现如下SSH提示,输入yes即可。
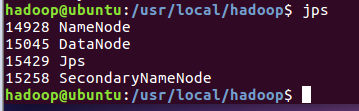
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
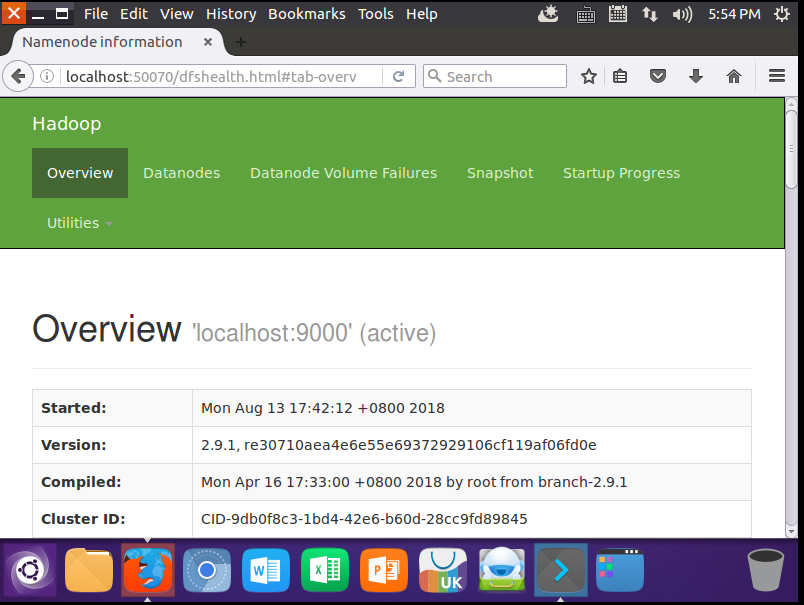
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
若要关闭 Hadoop,则运行
下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以!
附加教程: 配置PATH环境变量
在这里额外讲一下 PATH 这个环境变量(可执行 echo $PATH 查看,当中包含了多个目录)。例如我们在主文件夹 ~ 中执行 ls 这个命令时,实际执行的是 /bin/ls 这个程序,而不是 ~/ls 这个程序。系统是根据 PATH 这个环境变量中包含的目录位置,逐一进行查找,直至在这些目录位置下找到匹配的程序(若没有匹配的则提示该命令不存在)。
上面的教程中,我们都是先进入到 /usr/local/hadoop 目录中,再执行 sbin/hadoop,实际上等同于运行 /usr/local/hadoop/sbin/hadoop。我们可以将 Hadoop 命令的相关目录加入到 PATH 环境变量中,这样就可以直接通过 start-dfs.sh 开启 Hadoop,也可以直接通过 hdfs 访问 HDFS 的内容,方便平时的操作。
同样我们选择在 ~/.bashrc 中进行设置(vim ~/.bashrc,与 JAVA_HOME 的设置相似),在文件最前面加入如下单独一行:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin添加后执行 source ~/.bashrc 使设置生效,生效后,在任意目录中,都可以直接使用 hdfs 等命令了,读者不妨现在就执行 hdfs dfs -ls input 查看 HDFS 文件试试看。