事务与并发控制
事务:是用户定义的一组数据库操作序列的集合,是数据恢复和并发控制的基本单位。数据库在执行这些操作时,要么执行事务中的全部操作,要么一个操作都不执行,是一个不可分割的工作单位。
例如,在银行业务中,有一条记帐原则,即有借有贷,借贷相等。那么为了保证这种原则,就得有确保借和贷的登记要么同时成功,要么同时失败。如果出现只记录了借,或者只记录了贷,那么就违反了记帐原则,就会出现记错帐的情况。
- 原子性(Atomicity):一个事务是不可分割的数据库的逻辑工作单位,它所做的对数据修改操作要么全部执行,要么完全不执行,也就是说事务的操纵序列或者完全应用到数据库或者完全不影响数据库。
- 一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。当数据库只包含成功事务提交的结果时,就说数据库处于一致性状态。
- 隔离性(Isolation):一个事务的执行不能其他事务干扰。即一个事务内部的操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持续性:也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的,接下来的其他操作或故障不应该对其执行结果有任何影响。
★ DBMS中事务处理必须保证其ACID特性,这样才能保证数据库中数据的安全和正确。
事务是DBMS必备的机制
- 恢复机制与并发控制机制的提出
- 事务在运行过程中因某种故障被强行终止,数据库一致性被破坏,需进行恢复。
- 多个事务并行运行时,不同事务的各种操作交叉进行,为保证各事务的执行互不干扰,需进行并发控制。
并发控制
-
在关系数据库系统中采用并发机制的主要目的有:
- 改善系统的资源利用率,事务并发执行,可以交叉利用这些资源,有利于提高系统资源的利用率。
- 改善短事务的响应时间。设有两个事务T1和T2,其中T1是长事务,交付系统在先。T2是短事务,交付系统比T1稍后。如果串行执行,则需等T1执行完毕后才能执行T2,T2的响应时间会很长,而对于短事务的响应时间偏长,则很难得到用户的理解。如果T1和T2并发执行,则T2可以和T1重叠执行,且可以较快地结束,将明显地改善短事务的响应时间,如图3-11所示。
-
当多个用户并发地存取数据库时可能出现多个事务同时存取同一数据的情况。这种数据库的不一致是由并发操作引起的。
-
并发操作带来的问题
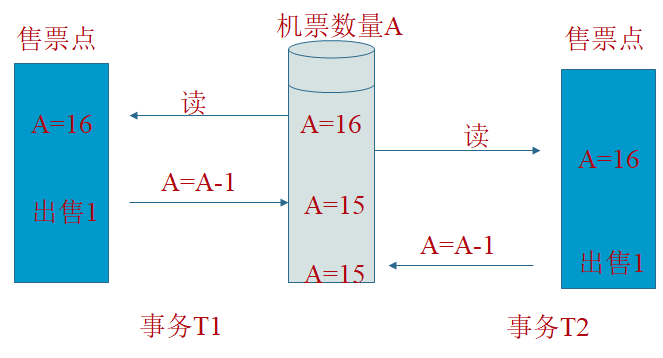
- 丢失或覆盖更新:当两个或多个事务选择同一数据,并且基于最初选定的值更新该数据时,会发生丢失更新问题。每个事务都不知道其他事务的存在。
- 不可重复读:一个事务重新读取前面读取过的数据,发现该数据已经被另一个已提交的事务修改过。即事务1读取某一数据后,事务2对其做了修改,当事务1再次读数据时,得到的与第一次不同的值。
- 脏读数据:事务读取了另一个未提交的并行事务写的数据。当第二个事务选择其他事务正在更新的行时,会发生未确认的相关性问题。换句话说,当事务1修改某一数据,并将其写回磁盘,事务2读取同一数据后,事务1由于某种原因被撤销,这时事务1已修改过的数据恢复原值,事务2读到的数据就与数据库中的数据不一致,是不正确的数据,称为脏读。
例如,在图中,事务1将C值修改为200,事务2读到C为200,而事务1由于某种原因撤销,其修改作废,C恢复原值100,这时事务2读到的就是不正确的“脏”数据了。 - 幻像读:如果一个事务在提交查询结果之前,另一个事务可以更改该结果,就会发生这种情况,即事务1按一定条件从数据库中读取某些数据记录后未提交查询结果,事务2删除了其中部分记录,事务1再次按相同条件读取数据时,发现某些记录神秘地消失了。或者事务1按一定条件从数据库中读取某些数据记录后未提交查询结果,事务2插入了一些记录,当事务1再次按相同条件读取数据时,发现多了一些记录。
-
产生上述数据不一致性的主要原因是:并发操作破坏了事务的隔离性,事务间相互干扰。并发控制的主要技术:封锁
锁
- 封锁:事务T在对某个数据对象(如表、记录等)操作之前,先向系统发出请求,对其加锁,加锁后事务T就对数据库对象有了一定的控制,在事务T释放它的锁之前,其他事务不能更新此数据对象。DBMS通常提供了多种数据类型的封锁。一个事务对某个数据对象加锁后究竟拥有什么控制是由封锁类型决定的。
- 基本的封锁类型有两种:
- 排它锁(eXclusive lock,X锁):写锁
若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。 - 共享锁(Share lock,S锁):读锁
若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。 - 封锁协议的概念
- 何时申请加锁、持锁时间、何时释放等规则。
- 不同的封锁协议所达到的系统一致性不同。
- 排它锁(eXclusive lock,X锁):写锁
- 三个级别封锁协议
- 一级封锁协议::事务T在修改数据R之前必须先对其加X 锁,直至事务结束。
- 二级封锁协议
- 读数据前加S锁,读完即释放
- 写数据前加X 锁直至事务结束
- 三级封锁协议
- 读数据前加S锁直至事务结束
- 写数据前加X 锁直至事务结束
| 一级 | 二级 | 三级 | |
|---|---|---|---|
| 丢失修改 | 1 | 1 | 1 |
| 可重复读 | 不能保证 | 不能保证 | 1 |
| 读脏数据 | 不能防止 | 1 | 1 |
-
死锁与死锁解决方案
-
采用封锁的方法固然可以有效地防止数据的不一致性,但封锁本身会引起一些麻烦,即死锁和活锁的问题,其中最主要的就是死锁问题。
-
活锁:如果事务T1封锁了数据对象R后,事务T2页请求封锁R,于是T2等待。接着T3也请求封锁R。当T1释放了加在R上的锁后,系统首先批准了T3的请求,T2只得继续等待。接着T4也请求封锁R,T3释放R上的锁后,系统又批准了T4的请求,…,因此,事务T2就有可能这样永远地等待下去,以上这种情况就称为活锁。
-
避免活锁的简单办法是采用先来先服务的策略。当多个事务请求封锁同一数据对象时,封锁子系统按封锁请求的先后次序对这些事务排队,该数据对象上的锁一旦释放,首先批准申请队列中的第一个事务获得锁。
-
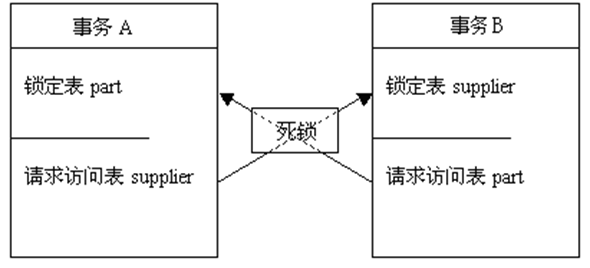
死锁:在事务和锁的使用过程中,死锁是一个不可避免的现象。如当两个事务分别锁定了两个单独的对象,这时每一个事务都要求在另外一个事务锁定的对象上获得一个锁,因此每一个事务都必须等待另外一个事务释放占有的锁,这时,就发生了死锁。这种死锁是最典型的死锁形式。如下图所示。
-
死锁的诊断与解除
- 数据库系统中诊断死锁的方法与操作系统类似,一般是用超时法或事务等待图法。
- 超时法:指如果一个事务的等待时间超过了规定的时限,就认为发生了死锁。超时法实现简单,但其不足也很明显。一是有可能误判死锁,事务因为其他原因使等待时机超过时限,系统会误认为发生了死锁。二是时限若设置得太长,死锁发生后不能及时发现。
- 等待图法:用事务等待图动态反映所有事务的等待情况。事务等待图是一个有向图,其中T为结点的集合,每个结点表示正运行的事务。U为边的集合,每条边表示事务等待的情况。 若T1等待T2,则T1,T2之间划一条有向边,从T1指向T2。事务等待图动态地反映了所有事务的等待情况。并发控制子系统周期性地(比如每隔1 min)检测事务等待图,如果发现图中存在回路,则表示系统中出现了死锁。
- DBMS的并发控制子系统一旦检测到系统中存在死锁,就要设法解除。通常采用的方法是选择一个处理死锁代价最小的事务,将其撤销,释放此事务持有的所有的锁,使其他事务能继续运行下去。当然,对撤销的事务所执行的数据修改操作必须加以恢复。