一、训练及验证模型的方法
- 最佳模型:在测试数据集(或者相对于模型来说是全新的数据集)上表现的比较好的模型,因为这种模型的泛化能力强,放在生成环境中面对未知的环境时有更好的表现。
- 调整的参数通常就是超参数:kNN 中的 k 和 P 、多项式回归中的 degree 等;
- 通常调参时使用交叉验证的方法。
1)方案(一):将所有数据集都作为训练数据集
- 问题:如果将所有的数据集都作为训练数据集,则对于训练出的模型是否发生了过拟合会不自知,因为过拟合情况下,模型在训练数据集上的误差非常的小,使人觉得模型效果很好,但实际上可能泛化能力不足;
2)方案(二):将数据集分割为训练数据集和测试数据集
- 通过测试数据集判断模型的好坏——如果通过学习曲线发现,模型在训练数据集上效果较好,在测试数据集上效果不好,模型出现过拟合,需要调整参数来重新得到模型,然后再次进行测试;以此类推循环此过程,最终得到最佳模型。

- 方案缺陷:
- 此方案得到的最佳模型,有可能会过拟合了测试数据集(模型过拟合测试数据集后,在测试数据集上表现的准确率会升高),得到的模型的准确率不能反应模型真正的性能;
- 如果最佳模型过拟合了测试数据集,并且测试数据集上存在极端数据,该模型可能会因为拟合了某些极端数据而不准确。
- 原因:虽然使用训练数据获得模型,但每次通过测试数据集验证模型的好坏,一旦发现模型不好就重新调整参数再次训练新的模型,这个过程一定程度上是模型在围绕着测试数据集进行刷选,也就是说,我们在想办法找到一组参数,这组参数使得我们在训练数据集上获得的模型在测试数据集上效果最好,但是由于测试数据集是已知的,我们相当于在针对这组测试数据集进行调参,那么也有可能出现过拟合的现象,也就是说我们得到的模型针对这组测试数据集过拟合了,使得模型在测试数据集上的表现的准确率比其真正的准确率偏高。并且,如果测试数据集上有极端的数据,过拟合测试数据的模型会不准确。
- 方案优点:解决了 方案(一) 的问题;
3)方案(三):将数据集分割为 3 部分——训练数据集、验证数据集、测试数据集

- 最终目的:查看该算法是否适合解决此类问题;
- 判断标准:由训练数据集和验证数据集得到的最佳模型,在测试数据集上体现的泛化能力满足实际的要求。(如果泛化能力不能满足实际的要求,则认为该算法不适合解决此类问题)
- 训练数据集:训练模型;
- 验证数据集:验证模型的效果;如果模型的效果不好,则重新调整参数再次训练新的模型,直到找到了一组参数,使得模型针对验证数据集来说已经达到最优了;(调整超参数使用的数据集)
- 测试数据集:将此数据集传入由验证数据集得到的最佳模型,得到模型最终的性能;(作为衡量最终模型性能的数据集)
- 训练数据集和验证数据集参与了模型的创建:训练数据集用来训练,验证数据集用来评判,一旦评判不好则重新训练,这两种形式都叫参与了模型的创建;
- 测试数据集不参与模型的创建,其相对模型是完全不可知的,相当于是我们在模拟真正的真实环境中我们的模型完全不知道的数据;
- 方案缺点
- :分割方式是随机的,模型有可能过拟合验证数据集,导致所得的模型的性能指标不能反应模型真正的泛化能力;
- 随机分割数据集带来的问题:只有一份验证数据集,一旦验证数据集中有极端的数据就可能导致模型相应的不准确,则该模型在测试数据集上体现的泛化能力不能满足实际要求,因此该算法会被认为不适合解决此问题。
- 如果验证数据集中含有极端的数据?——在含有极端数据的数据集上通过验证得到最高准确率的模型,是不准确的。因为该模型可能也拟合了部分极端数据。
4)方案(四):交叉验证(Cross Validation)
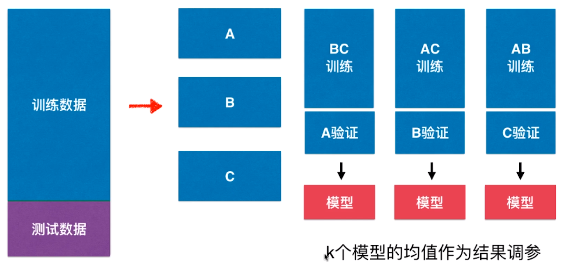
- 交叉验证相对(数据分割)是比较正规和标准的在调整模型参数时使用的查看模型性能的方式;
- 交叉验证:将原始数据集分割为训练数据集和测试数据集,再将训练数据集分割为 k 个数据集,对每一组参数,都分别让每一个数据集作为验证数据集,其余数据集一起作为训练数据集,训练出 k 个模型,每一个模型都在对应的验证数据集上求出其性能的指标,k 个模型的性能指标的平均值作为最终衡量该组参数对应的模型的性能指标。
- 一组参数训练出 k 个模型,
- 如果最终指标不理想,重新调整参数,再次得到这 k 个模型的性能指标的均值。
- 交叉验证也称为k-folds 交叉验证:通常把训练数据集分割为 k 份,每一份都可以称为一个 folds ,因此交叉验证也称为 k-folds 交叉验证;
- 方案缺点:每次调试一组参数都要训练 k 个模型,相当于整体性能慢了 k 倍;
5)在极端情况下,k-folds 交叉验证可以变为“留一法”( LOO-CV)的交叉验证方式
- 留一法( LOO-CV):X_train 有 m 个样本,将 X_train 分割成 m 份,每一个样本作为一份,也就是每次将 m - 1 份样本用于训练,让剩下的一个样本用于测试模型,将 m 次预测结果的正确的概率作为一组参数对应的模型准确率;
- 优点:将 X_train 份成 m 份,训练模型所用的数据将完全不受随机的影响,最接近模型真正的性能指标;因为即使将 X_train 分割成 k 份,不管怎么分割,k 份数据集都有若干种可能性,也会有随机带来的影响。
- 缺点:计算量巨大;
- 随机分割数据集会带来什么影响?——最佳的平均准确度对应的 k 个模型中,可能有部分模型刚好与其对应的验证数据集过拟合,导致准确度过高,进而使得此 k 个模型的平均准确度最高。如果验证数据集只是一个样本,不会出现过拟合现象。
二、交叉验证
- 调用 scikit-learn 库中的 cross_val_score() 方法
1)使用手写识别数据集
-
import numpy as np from sklearn import datasets digits = datasets.load_digits() X = digits.data y = digits.target
2)使用 train_test_split 并调参
-
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=666) %%time from sklearn.neighbors import KNeighborsClassifier best_score, best_p, best_k = 0, 0, 0 for k in range(2, 10): for p in range(1, 6): knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=k, p=p) knn_clf.fit(X_train, y_train) score = knn_clf.score(X_test, y_test) if score > best_score: best_score, best_p, best_k = score, p, k print("Best K =", best_k) print("Best P =", best_p) print("Best score =", best_score) # 输出: Best K = 3 Best P = 4 Best score = 0.9860917941585535 Wall time: 32.2 s
3)使用交叉验证调参
-
%%time best_score, best_p, best_k = 0, 0, 0 for k in range(2, 10): for p in range(1, 6): knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=k, p=p) scores = cross_val_score(knn_clf, X_train, y_train) score = np.mean(scores) if score > best_score: best_score, best_p, best_k = score, p, k print("Best K =", best_k) print("Best P =", best_p) print("Best score =", best_score) # 输出: Best K = 2 Best P = 2 Best score = 0.9823599874006478 Wall time: 35.9 s
- cross_val_score(算法的实例对象, X_train, y_train, cv=k):交叉验证方法的使用格式;
4)分析
-
与 train_test_split 调参法的区别
- 拟合方式:cross_val_score(knn_clf, X_train, y_train),默认将 X_train 分割成 3 份,并得到 3 个模型的准确率;如果想将 X_train 分割成 k 份cross_val_score(knn_clf, X_train, y_train, cv=k);
- 判定条件:score = np.mean(scores),交叉验证中取 3 个模型的准确率的平均值最高时对应的一组参数作为最终的最优超参数;
- 与 train_test_split 方法相比,交叉验证过程中得到的最高准确率 score 较小;
- 原因:在交叉验证中,通常不会过拟合某一组的测试数据,所以平均来讲所得准确率稍微低一些;
5)其它
- 交叉验证得到的最好的准确率(Best score = 0.9823599874006478),并不是最优模型相对于数据集的准确率;
- 交叉验证的直接目的是获取最优的模型对应的超参数,而不是得到最优模型,当拿到最优的超参数后,就可以根据参数获取最佳的 kNN 模型;
-
kNN 算法的拟合内容:将训练数据集赋值给算法的私有变量
def fit(self, X_train, y_train): """根据训练数据集X_train和y_train训练kNN分类器""" assert X_train.shape[0] == y_train.shape[0], "the size of X_train must be equal to the size of y_train" assert self.k <= X_train.shape[0], "the size of X_train must be at least k." self._X_train = X_train self._y_train = y_train return self
- 赋值给算法的私有变量的好处,拟合后的实例模型对象不会随 X_train、和y_train 数据集的改变而改变
三、网格搜索
- 其实整个交叉验证的过程在网格搜索过程中已经被使用过;
- 网格搜索过程,其中 CV 就是指 Cross Validation(交叉验证);
- 网格搜索返回了一个 GridSearchCV 的对象,这个对象并不是最佳的算法模型,只是包含了搜索的结果,
1)kNN 算法的网格搜索过程
-
代码
from sklearn.model_selection import GridSearchCV param_grid = [ { 'weights': ['distance'], 'n_neighbors': [i for i in range(2, 11)], 'p': [i for i in range(1, 6)] } ] grid_search = GridSearchCV(knn_clf, param_grid, verbose=1, cv=3) grid_search.fit(X_train, y_train) # 输出:Fitting 3 folds for each of 45 candidates, totalling 135 fits
- “3 folds”:就是指网格搜索使用交叉验证的方式,默认将 X_train 分割成 3 份;如果将 X_train 分割成 k 份:grid_search = GridSearchCV(knn_clf, param_grid, verbose=1, cv=k);
- “45 candidates”:k 从 [2, 11) 有 9 个值,p 从 [1, 6) 有 5 个值,一共要对 45 组参数进行搜索;
- “135 fits”:一共要对 45 组参数进行搜索,每次搜索要训练出 3 个模型,一共要进行 135 此拟合训练;
-
查看在网格搜索过程中,交叉验证的最佳的准确率
grid_search.best_score_ # 输出:0.9823747680890538
-
查看搜索找到的最佳超参数
grid_search.best_params_ # 输出:{'n_neighbors': 2, 'p': 2, 'weights': 'distance'}
-
获得最佳参数对应的最佳分类器(也就是最佳模型),此分类器不需要再进行 fit
best_knn_clf = grid_search.best_estimator_ best_knn_clf.score(X_test, y_test) # 输出:0.980528511821975
# 0.980528511821975 就是模型真正的泛化能力;