# 注:使用线性回归算法的前提是,假设数据存在线性关系,如果最后求得的准确度R < 0,则说明很可能数据间不存在任何线性关系(也可能是算法中间出现错误),此时就要检查算法或者考虑使用其它算法;
一、功能与特点
1)解决回归问题
2)思想简单,实现容易
# 因为算法运用了很多的数学推到,使计算机实现变得容易
3)许多非线性模型的基础
4)结果具有很好的可解释性
# 算法系统通过学习数据,训练模型,可以学到真实世界中真实的知识
5)蕴含机器学习中的很多重要思
二、定义与思路
- 目的:根据样本特征,预测样本的其它性质、特征或数据;
- 思路:寻找一条直线,最大程度的“拟合”样本特征和样本输出标记之间的关系,建立数学模型,求解最优的数学模型对应的参数;
- 怎么才算最大程度的“拟合”:让数据集中的所有样本点,距离线性模型的距离的和最小;
- 例:根据房子的面积预测房子的价格,面积是房子特征,价格是房子的输出标记;
三、简单线性回归
- 单线性回归:样本特征只有一个;
- 数学模型:y = ax + b
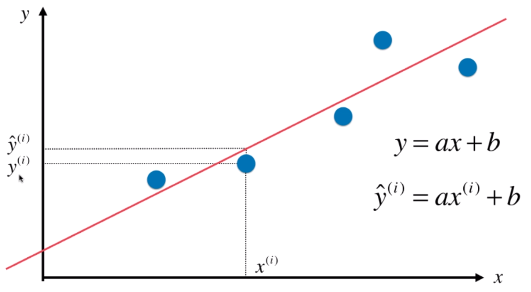
四、最优化简单线性回归
1)思路
- 假设的线型关系:y = ax + b
- (xi, yi):为训练集中的一个样本点
- ý = axi + b,(xi, ý):是根据数学模型得到的点
- |ý - yi| = |axi + b - yi|:一个预测值与其真实值之间的距离
- 训练集中,所有样本的预测值与其真实值之间的距离和,优化出最小距离和所对应的a、b,即为得出最优的数学模型;
- 公式:(axi + b - yi)2,来表示一个样本点的距离,而不用绝对值,因为优化过程中使用绝对值计算不方便;
2)公式

- m:训练集中的m个样本
-
x(i) 和 y(i):训练集中的特征和其对应的标记值
-
x + - 和 y + -:训练集中特征和标记的均值
3)优化过程
- 优化求参数b的表达式
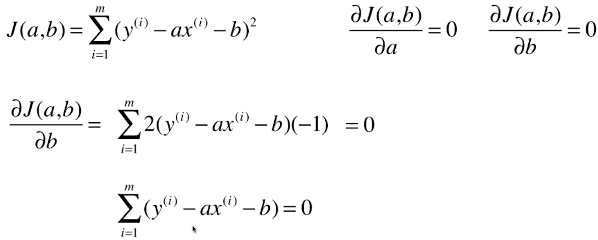
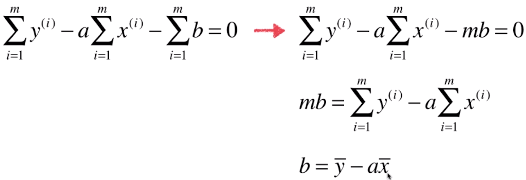
- 优化求参数a的表达式
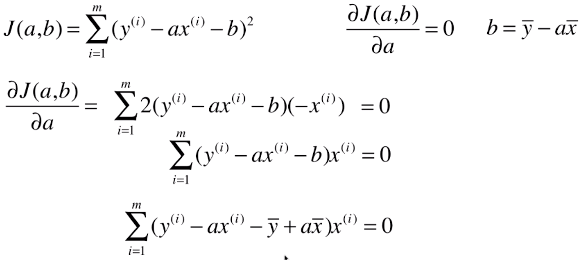
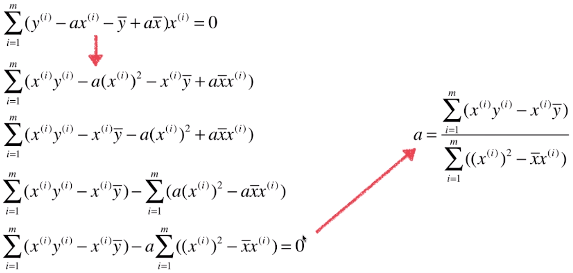
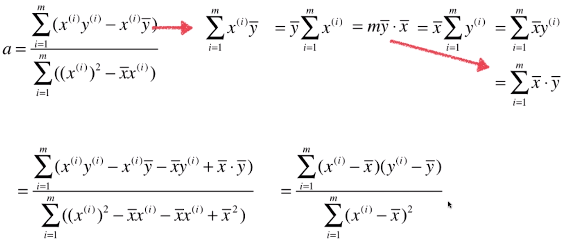
- 一般用J(a, b)表示损失函数
- a、b是要求的参数,x、y是训练集中已知的数据
- 运算思路:将运算式整理成向量之间进行运算的形式(向量化)
4)向量化
- 向量化:将运算式整理成向量之间进行运算的形式
- 优点:向量之间运算效率更高;
- 例:J(a, b) = np.sum(array1.array2) == np.dot(array1, array2) == array1.dot(array2),而不是采用for循环;
- 注1:array1 * array2,两向量对应数据相乘,结果还是一个array
- 注2:np.dot(array1, array2),两向量相乘所得新向量的数据和
五、简单线性回归算法的代码实现和使用
1)内部代码实现
import numpy as np from sklearn.metrics import r2_score class SimpleLinearRegression: def __init__(self): """初始化Simple Linear Regression模型""" self.a_ = None self.b_ = None def fit(self, x_train, y_train): """根据训练数据集x_train, y_train训练Simple Linear Regression模型""" assert x_train.ndim == 1, "Simple Linear Regressor can only solve single feature training data." assert len(x_train) == len(y_train), "the size of x_train must be equal to the size of y_train" x_mean = np.mean(x_train) y_mean = np.mean(y_train) self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean) self.b_ = y_mean - self.a_ * x_mean return self def predict(self, x_predict): """给定待预测数据集x_predict,返回表示x_predict的结果向量""" assert x_predict.ndim == 1, "Simple Linear Regressor can only solve single feature training data." assert self.a_ is not None and self.b_ is not None, "must fit before predict!" return np.array([self._predict(x) for x in x_predict]) def _predict(self, x_single): """给定单个待预测数据x,返回x的预测结果值""" return self.a_ * x_single + self.b_ def score(self, x_test, y_test): """根据测试数据集 x_test 和 y_test 确定当前模型的准确度""" y_predict = self.predict(x_test) return r2_score(y_test, y_predict) def __repr__(self): return "SimpleLinearRegression()"
2)在Jupyter Notebook中使用所写的算法
# 导入封装算法的类 import numpy as np import matplotlib.pyplot as plt from LR.S_L_R_2 import SimpleLinearRegression x = np.array([1., 2., 3., 4., 5.]) y = np.array([1., 3., 2., 3., 5.]) # 初始化 regl = Simple_linear_Regression1() # fit regl.fit(x, y)
3)其它
- 参数学习算法与kNN算法内部实现的区别:参数学习算法不需要存储用户传进来的训练数据集
- 训练数据集的意义就是训练模型的参数,一旦模型得到参数的值,训练数据集就没用了
- 在预测时,只需要使用训练到的参数对待预测的数据进行计算即可
- np.dot(array1, array2) == array1.dot(array2):计算两个向量(返回一个数值),或者两矩阵的乘积(返回一个矩阵/向量)
六、对线性回归算法的其它思考
1)算法特点
-
线性回归算法:典型的参数学习算法;
# kNN算法:非参数学习算法
-
线性回归算法:只能解决回归问题,虽然很多分类方法中,线性回归是基础(如逻辑回归);
# kNN算法:即可解决分类问题,又可以解决回归问题;
-
线性回归算法对数据有假设性:线性
# 数据和最终的结果具有线性关系,关系越强,预测到的结果越好
# kNN算法对数据没有假设
- 一般稍微改变线性回归算法,就可以处理非线性的问题
2)优缺点
- 优点:对数据具有强解释性
- 缺点:时间复杂度高:O(n3)(即使优化后O(2.4))
3)线性回归算法具有可解释性
- 实例(sklearn.datasets中波士顿的房价数据)
1 import numpy as np 2 from sklearn import datasets 3 4 boston = datasets.load_boston() 5 X = boston.data 6 y = boston.target 7 8 X = X[y < 50.0] 9 y = y[y < 50.0] 10 11 from sklearn.linear_model import LinearRegression 12 13 lin_reg = LinearRegression() 14 lin_reg.fit(X, y) 15 16 lin_reg.coef_ 17 # 输出:array([-1.05574295e-01, 3.52748549e-02, -4.35179251e-02, 4.55405227e-01, 18 -1.24268073e+01, 3.75411229e+00, -2.36116881e-02, -1.21088069e+00, 19 2.50740082e-01, -1.37702943e-02, -8.38888137e-01, 7.93577159e-03, 20 -3.50952134e-01]) 21 22 # 对系数排序:默认从小到大,返回系数的index 23 np.argsort(lin_reg.coef_) 24 # 输出:array([ 4, 7, 10, 12, 0, 2, 6, 9, 11, 1, 8, 3, 5], dtype=int64) 25 26 # 根据系数排序后的index,对特征从新排序 27 boston.feature_names[np.argsort(lin_reg.coef_)] 28 29 # 查看每个特征相对样本的意义 30 print(boston.DESCR)
- 系数的意义(依据实例说明)
- 系数有正有负,正负表示特征与最终预测的目标(也就是房价)是正相关还是负相关;
- 系数为正,特征与目标是正相关,则特征越大房价越高;
- 系数为负,特征与目标是负相关,则特征越大房价越低;
- 系数的绝对值的大小,决定了特征对目标的影响程度;
- 根据系数和特征,分析预测结果(依据实例分析)
- RM(房间数量)特征:系数最大,说明房间越多的房屋,房价越高;
- CHAS(房屋临河)特征:系数排第二,说明临河的房屋,房价高,不临河的房屋房价低;
- NOX(房屋周围一氧化氮的浓度)特征:系数最小,说明房屋周围的一氧化碳的浓度越低,房价越高;
- DIS(房屋距离劳务雇佣中心的距离)特征:系数排倒数第二,说明房屋距离劳务雇佣中心的距离约小,房价越高;
- 知道特征与目标之间的关系后,可以采集更多的特征,来更好的描述房屋的房价
七、其它
- 很多学界领域的研究,很多时候都会首先尝试使用线性回归算法这种最基础最简单的方式
- 回归问题中,具体预测的是一个数值,这个具体的数值是在一个连续的空间里的
- 所谓的建模的过程,其实就是找到一个数学模型,最大程度的“拟合”数据,如:y = ax + b
- 所谓最大程度“拟合”数据,本质就是找到一个函数(目标函数),度量出模型没有“拟合”住的那一部分样本,或者度量出能最大“拟合”的程度
- 在线性回归算法中,建立的模型就是一个直线方程
- 目标函数:损失函数、效用函数
- 特征空间中,有些点在数学模型上(满足数学模型的关系),有些不模型上,不在数学模型上的那部分点,称为损失的数据
- 效用函数:度量的是“拟合”的程度
机器学习算法的思路
- 分析问题,确定问题的目标函数(损失函数或者效用函数)
- 最优化目标函数,获取机器学习的模型:优化损失函数,使其尽可能的小;优化效用函数,使其尽可能的大;
- 所有的参数学习算法都是这样的套路:线性回归、多项式回归、逻辑回归、SVM、神经网络等,区别在于这些算法的模型、目标函数、优化方式不同;
- 有一个学科:最优化原理,凸优化为最优化原理的分支,专门研究优化问题
- 解决了最优化的问题后,就获得了一个机器学习的模型;