1.概述
压缩列表是一块连续的内存空间,元素之间紧挨着存储,没有任何冗余空间。
Redis 为了节约内存空间使用,zset 和 hash 容器对象在元素个数较少的时候,采用压缩列表 (ziplist) 进行存储。3.2.0版本之前, 当 List 容器对象在元素个数较少的时候,也采用压缩列表 (ziplist) 进行存储, 3.2.0之后 List 全部使用 quickList(快速列表).
2. zipList 基本结构
struct ziplist<T> { int32 zlbytes; // 4 byte, 记录整个压缩列表占用内存字节数,在内存分配或者计算 zlend 的位置时使用 int32 zltail_offset; // 4 byte, 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点 int16 zllength; // 2 byte, 元素个数当属性值 < 65535 时, 属性值表示节点个数, 当属性值 = 65535 时, 真实节点个数需要遍历压缩列表才能计算得出 T[] entries; // 元素节点列表,节点之间挨个紧凑存储,无冗余空间 int8 zlend; // 1 byte,标志压缩列表的结束,值恒为 0xFF }
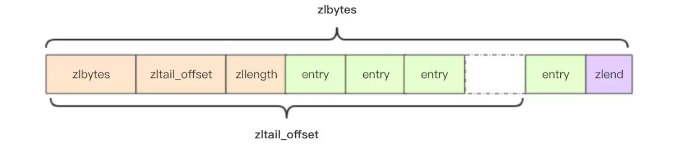
压缩列表为了支持双向遍历,所以才会有 ztail_offset 这个字段,用来快速定位到最后一个元素,然后倒着遍历。
3. entry 基本结构
每个压缩列表的节点可以保存一个字节数组或者一个整数值.
struct entry { int<var> prevlen; // 前一个 entry 的字节长度, 前一个节点长度小于254字节,则该属性用一个字节表示, 否则(大于等于254字节)用五个字节表示,第一个字节被设置为0xFE(254), 后四个字节表示前一个节点长度 int<var> encoding; // 记录了节点的 content 属性所保存的数据的类型及长度. 当属性长度为 1 2 5 字节,值最高位为 00 01 10 时表示为字节数组, 数组长度有编码去除最高2位之后的其他位记录, 当属性长度为 1 字节长, 最高位以 11 开头表示是整数编码,整数的类型和长度有编码去除最高2位的其他位表示 optional byte[] content; // 保存节点的值, 可以是一个字节数组或者整数. }
4. 连锁更新
当压缩列表有多个连续的且长度介于250字节到253字节的节点,连锁更新才可能被触发.实际中这种情况并不多见.
其次, zipList 本来就是元素较少的情况下使用的数据结构, 所有更新节点的数量也并不会太多, 对性能造成的影响并不大.
prevlen 属性的字节长度引起的连锁更新
有N个节点的长度都是介于250字节到254字节之间, 当增加了一个新的节点 ,该节点的 prevlen 属性值字节长度为五个字节,则下一个节点的 prevlen 属性则变为五个字节, 其总体长度也介于254字节到257字节之间,下下一个节点也发生同样的变化.之后后续节点都要进行更新操作.
5. 内存分配
因为 ziplist 都是紧凑存储,没有冗余空间 (对比一下 Redis 的字符串结构)。节点的增删都会影响其结构
插入一个新的元素就需要调用 realloc 扩展内存。取决于内存分配器算法和当前的 ziplist 内存大小,realloc 可能会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址,也可能在原有的地址上进行扩展,这时就不需要进行旧内容的内存拷贝.
当删除一个元素后, 后面的节点则要向前移动