最终效果图片

环境准备
创建一个目录,并切换到改目录
[root@bigdata1 ~]# mkdir -p /opt/module/flink-sql/ [root@bigdata1 ~]# cd /opt/module/flink-sql/
从githup上下载 docker-compose.yml 文件到次目录 https://github.com/wuchong/flink-sql-demo/blob/v1.11-EN/docker-compose.yml
该 Docker Compose 中包含的容器有:
- Flink SQL Client: 用于提交 Flink SQL
- Flink集群: 包含一个 JobManager 和 一个 TaskManager 用于运行 SQL 任务。
- DataGen: 数据生成器。容器启动后会自动开始生成用户行为数据,并发送到 Kafka 集群中。默认每秒生成 2000 条数据,能持续生成一个多小时。也可以更改
docker-compose.yml中 datagen 的speedup参数来调整生成速率(重启 docker compose 才能生效)。 - MySQL: 集成了 MySQL 5.7 ,以及预先创建好了类目表(
category),预先填入了子类目与顶级类目的映射关系,后续作为维表使用。 - Kafka: 主要用作数据源。DataGen 组件会自动将数据灌入这个容器中。
- Zookeeper: Kafka 容器依赖。
- Elasticsearch: 主要存储 Flink SQL 产出的数据。
- Kibana: 可视化 Elasticsearch 中的数据。
安装Docker Compose
运行以下命令以下载Docker Compose的当前稳定版本:
[root@bigdata1 ~]# sudo curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
将可执行权限应用于二进制文件:
[root@bigdata1 ~]# sudo chmod +x /usr/local/bin/docker-compose
测试安装
[root@bigdata1 ~]# docker-compose --version [81516] Cannot open self /usr/local/bin/docker-compose or archive /usr/local/bin/docker-compose.pkg
切换到 /usr/local/bin/目录下查看docker-compose文件,发现只有1.8M
[root@bigdata1 ~]# cd /usr/local/bin/ [root@bigdata1 bin]# ll 总用量 1752 -rwxr-xr-x. 1 root root 1792577 10月 21 01:29 docker-compose [root@bigdata1 bin]# du -sh docker-compose 1.8M docker-compose
估计是因为wget下载是网络不好,没有完整下载,此时需要去github上手动下载文件 https://github.com/docker/compose/releases

将文件上传到/usr/local/bin/ 目录下,重命名为docker-compose,修改文件权限:
[root@bigdata1 ~]# cd /usr/local/bin/ [root@bigdata1 bin]# mv docker-compose-Linux-x86_64 docker-compose mv:是否覆盖"docker-compose"? y
[root@bigdata1 ~]# sudo chmod +x /usr/local/bin/docker-compose
测试安装
[root@bigdata1 ~]# docker-compose --version docker-compose version 1.25.0-rc4, build 8f3c9c58
githup上的居然是1.25.0版本的,不是最新的fuck
启动docker
[root@bigdata1 ~]# sudo systemctl start docker
切换到/opt/module/flink-sql/ 启动容器docker-compose
[root@bigdata1 ~]# cd /opt/module/flink-sql/ [root@bigdata1 flink-sql]# docker-compose up -d Creating network "flink-sql_default" with the default driver Pulling jobmanager (flink:1.11.0-scala_2.11)...
docker ps 查看五个容器是否正常启动
[root@bigdata1 flink-sql]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c2fc3162f707 jark/demo-sql-client:0.2 "/docker-entrypoint.…" 12 seconds ago Up 10 seconds 6123/tcp, 8081/tcp flink-sql_sql-client_1 f3c79ec39173 jark/datagen:0.2 "/usr/local/bin/mvn-…" 12 seconds ago Up 11 seconds flink-sql_datagen_1 1ca8862da311 wurstmeister/kafka:2.12-2.2.1 "start-kafka.sh" 13 seconds ago Up 11 seconds 0.0.0.0:9092->9092/tcp, 0.0.0.0:9094->9094/tcp flink-sql_kafka_1 648381b17e15 flink:1.11.0-scala_2.11 "/docker-entrypoint.…" 13 seconds ago Up 12 seconds 6123/tcp, 8081/tcp flink-sql_taskmanager_1 bfdff79acdaa wurstmeister/zookeeper:3.4.6 "/bin/sh -c '/usr/sb…" 14 seconds ago Up 12 seconds 22/tcp, 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp flink-sql_zookeeper_1 5cca44730188 docker.elastic.co/elasticsearch/elasticsearch:7.6.0 "/usr/local/bin/dock…" 14 seconds ago Up 12 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp flink-sql_elasticsearch_1 1abf608ff0ed flink:1.11.0-scala_2.11 "/docker-entrypoint.…" 14 seconds ago Up 12 seconds 6123/tcp, 0.0.0.0:8081->8081/tcp flink-sql_jobmanager_1 28ae43f07570 docker.elastic.co/kibana/kibana:7.6.0 "/usr/local/bin/dumb…" 14 seconds ago Up 12 seconds 0.0.0.0:5601->5601/tcp flink-sql_kibana_1 7349b947aab9 jark/mysql-example:0.2 "docker-entrypoint.s…" 14 seconds ago Up 13 seconds 0.0.0.0:3306->3306/tcp, 33060/tcp flink-sql_mysql_1
访问 http://localhost:5601/ 来查看 Kibana 是否运行正常。
另外可以通过如下命令停止所有的容器:
[root@bigdata1 flink-sql]# docker-compose down
进入 SQL CLI 客户端
[root@bigdata1 flink-sql]# docker-compose exec sql-client ./sql-client.sh
使用 DDL 创建 Kafka 表
Datagen 容器在启动后会往 Kafka 的 user_behavior topic 中持续不断地写入数据。数据包含了2017年11月27日一天的用户行为(行为包括点击、购买、加购、喜欢),每一行表示一条用户行为,以 JSON 的格式由用户ID、商品ID、商品类目ID、行为类型和时间组成。该原始数据集来自阿里云天池公开数据集,特此鸣谢。
我们可以在 docker-compose.yml 所在目录下运行如下命令,查看 Kafka 集群中生成的前5条数据。
[root@bigdata1 flink-sql]# docker-compose exec kafka bash -c 'kafka-console-consumer.sh --topic user_behavior --bootstrap-server kafka:9094 --from-beginning --max-messages 5' {"user_id": "952483", "item_id":"310884", "category_id": "4580532", "behavior": "pv", "ts": "2017-11-27 00:00:00"} {"user_id": "794777", "item_id":"5119439", "category_id": "982926", "behavior": "pv", "ts": "2017-11-27 00:00:00"} {"user_id": "875914", "item_id":"4484065", "category_id": "1320293", "behavior": "pv", "ts": "2017-11-27 00:00:00"} {"user_id": "980877", "item_id":"5097906", "category_id": "149192", "behavior": "pv", "ts": "2017-11-27 00:00:00"} {"user_id": "944074", "item_id":"2348702", "category_id": "3002561", "behavior": "pv", "ts": "2017-11-27 00:00:00"} Processed a total of 5 messages
有了数据源后,我们就可以用 DDL 去创建并连接这个 Kafka 中的 topic 了。在 Flink SQL CLI 中执行该 DDL。
CREATE TABLE user_behavior ( user_id BIGINT, item_id BIGINT, category_id BIGINT, behavior STRING, ts TIMESTAMP(3), proctime AS PROCTIME(), -- generates processing-time attribute using computed column WATERMARK FOR ts AS ts - INTERVAL '5' SECOND -- defines watermark on ts column, marks ts as event-time attribute ) WITH ( 'connector' = 'kafka', -- using kafka connector 'topic' = 'user_behavior', -- kafka topic 'scan.startup.mode' = 'earliest-offset', -- reading from the beginning 'properties.bootstrap.servers' = 'kafka:9094', -- kafka broker address 'format' = 'json' -- the data format is json );
如上我们按照数据的格式声明了 5 个字段,除此之外,我们还通过计算列语法和 PROCTIME() 内置函数声明了一个产生处理时间的虚拟列。我们还通过 WATERMARK 语法,在 ts 字段上声明了 watermark 策略(容忍5秒乱序), ts 字段因此也成了事件时间列。关于时间属性以及 DDL 语法可以阅读官方文档了解更多:
- 时间属性: https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/streaming/time_attributes.html
- DDL: https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/sql/create.html#create-table
在 SQL CLI 中成功创建 Kafka 表后,可以通过 show tables; 和 describe user_behavior; 来查看目前已注册的表,以及表的详细信息。我们也可以直接在 SQL CLI 中运行 SELECT * FROM user_behavior; 预览下数据(按q退出)。
接下来,我们会通过三个实战场景来更深入地了解 Flink SQL 。
统计每小时的成交量
使用 DDL 创建 Elasticsearch 表
我们先在 SQL CLI 中创建一个 ES 结果表,根据场景需求主要需要保存两个数据:小时、成交量。
CREATE TABLE buy_cnt_per_hour ( hour_of_day BIGINT, buy_cnt BIGINT ) WITH ( 'connector' = 'elasticsearch-7', -- using elasticsearch connector 'hosts' = 'http://elasticsearch:9200', -- elasticsearch address 'index' = 'buy_cnt_per_hour' -- elasticsearch index name, similar to database table name );
我们不需要在 Elasticsearch 中事先创建 buy_cnt_per_hour 索引,Flink Job 会自动创建该索引。
提交 Query
统计每小时的成交量就是每小时共有多少 "buy" 的用户行为。因此会需要用到 TUMBLE 窗口函数,按照一小时切窗。然后每个窗口分别统计 "buy" 的个数,这可以通过先过滤出 "buy" 的数据,然后 COUNT(*) 实现。
INSERT INTO buy_cnt_per_hour SELECT HOUR(TUMBLE_START(ts, INTERVAL '1' HOUR)), COUNT(*) FROM user_behavior WHERE behavior = 'buy' GROUP BY TUMBLE(ts, INTERVAL '1' HOUR);
这里我们使用 HOUR 内置函数,从一个 TIMESTAMP 列中提取出一天中第几个小时的值。使用了 INSERT INTO将 query 的结果持续不断地插入到上文定义的 es 结果表中
(可以将 es 结果表理解成 query 的物化视图)。
另外可以阅读该文档了解更多关于窗口聚合的内容:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/sql/queries.html#group-windows
在 Flink SQL CLI 中运行上述查询后,在 Flink Web UI 中就能看到提交的任务,该任务是一个流式任务,因此会一直运行。

可以看到凌晨是一天中成交量的低谷。
使用 Kibana 可视化结果
我们已经通过 Docker Compose 启动了 Kibana 容器,可以通过 http://localhost:5601 访问 Kibana。首先我们需要先配置一个 index pattern。点击左侧工具栏的 "Management",就能找到 "Index Patterns"。点击 "Create Index Pattern",然后通过输入完整的索引名 "buy_cnt_per_hour" 创建 index pattern。创建完成后, Kibana 就知道了我们的索引,我们就可以开始探索数据了。
先点击左侧工具栏的"Discovery"按钮,Kibana 就会列出刚刚创建的索引中的内容。
接下来,我们先创建一个 Dashboard 用来展示各个可视化的视图。点击页面左侧的"Dashboard",创建一个名为 ”用户行为日志分析“ 的Dashboard。然后点击 "Create New" 创建一个新的视图,选择 "Area" 面积图,选择 "buy_cnt_per_hour" 索引,按照如下截图中的配置(左侧)画出成交量面积图,并保存为”每小时成交量“。

统计一天每10分钟累计独立用户数
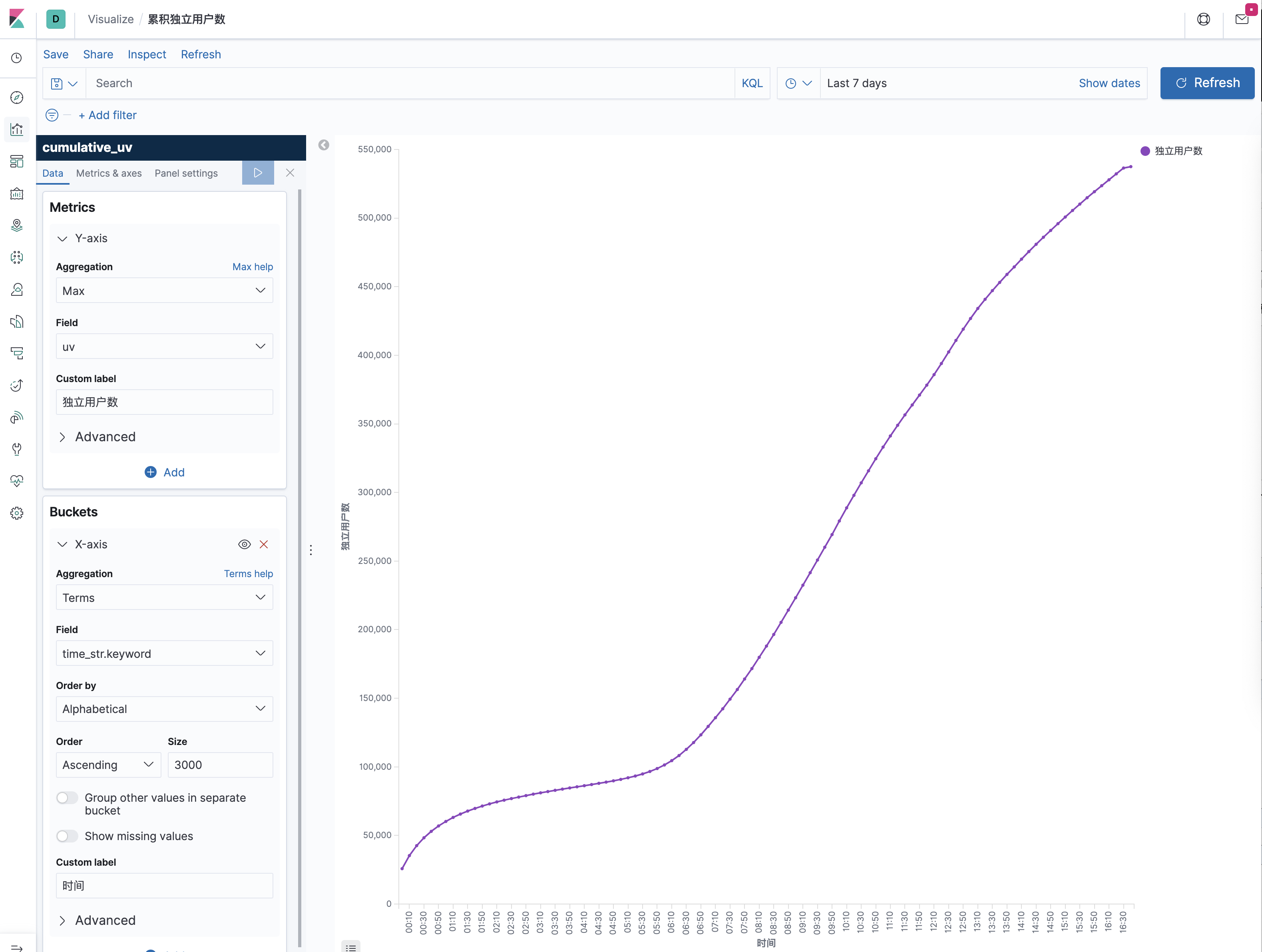
另一个有意思的可视化是统计一天中每一刻的累计独立用户数(uv),也就是每一刻的 uv 数都代表从0点到当前时刻为止的总计 uv 数,因此该曲线肯定是单调递增的。
我们仍然先在 SQL CLI 中创建一个 Elasticsearch 表,用于存储结果汇总数据。主要字段有:日期时间和累积 uv 数。我们将日期时间作为 Elasticsearch 中的 document id,便于更新该日期时间的 uv 值。
CREATE TABLE cumulative_uv ( date_str STRING, time_str STRING, uv BIGINT, PRIMARY KEY (date_str, time_str) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'http://elasticsearch:9200', 'index' = 'cumulative_uv' );
为了实现该曲线,我们先抽取出日期和时间字段,我们使用 DATE_FORMAT 抽取出基本的日期与时间,再用 SUBSTR 和 字符串连接函数 || 将时间修正到10分钟级别,如: 12:10, 12:20。其次,我们在外层查询上基于日期分组,求当前最大的时间,和 UV,写入到 Elasticsearch 的索引中。UV 的统计我们通过内置的 COUNT(DISTINCT user_id)来完成,Flink SQL 内部对 COUNT DISTINCT 做了非常多的优化,因此可以放心使用。
这里之所以需要求最大的时间,同时又按日期+时间作为主键写入到 Elasticsearch,是因为我们在计算累积 UV 数。
INSERT INTO cumulative_uv SELECT date_str, MAX(time_str), COUNT(DISTINCT user_id) as uv FROM ( SELECT DATE_FORMAT(ts, 'yyyy-MM-dd') as date_str, SUBSTR(DATE_FORMAT(ts, 'HH:mm'),1,4) || '0' as time_str, user_id FROM user_behavior) GROUP BY date_str;
提交上述查询后,在 Kibana 中创建 cumulative_uv 的 index pattern,然后在 Dashboard 中创建一个"Line"折线图,选择 cumulative_uv 索引,按照如下截图中的配置(左侧)画出累计独立用户数曲线,并保存。
顶级类目排行榜
最后一个有意思的可视化是类目排行榜,从而了解哪些类目是支柱类目。不过由于源数据中的类目分类太细(约5000个类目),对于排行榜意义不大,因此我们希望能将其归约到顶级类目。所以笔者在 mysql 容器中预先准备了子类目与顶级类目的映射数据,用作维表。
在 SQL CLI 中创建 MySQL 表,后续用作维表查询。
CREATE TABLE category_dim ( sub_category_id BIGINT, parent_category_name STRING ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://mysql:3306/flink', 'table-name' = 'category', 'username' = 'root', 'password' = '123456', 'lookup.cache.max-rows' = '5000', 'lookup.cache.ttl' = '10min' );
同时我们再创建一个 Elasticsearch 表,用于存储类目统计结果。
CREATE TABLE top_category ( category_name STRING PRIMARY KEY NOT ENFORCED, buy_cnt BIGINT ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'http://elasticsearch:9200', 'index' = 'top_category' );
第一步我们通过维表关联,补全类目名称。我们仍然使用 CREATE VIEW 将该查询注册成一个视图,简化逻辑。维表关联使用 temporal join 语法,
可以查看文档了解更多:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/streaming/joins.html#join-with-a-temporal-tabl
CREATE VIEW rich_user_behavior AS SELECT U.user_id, U.item_id, U.behavior, C.parent_category_name as category_name FROM user_behavior AS U LEFT JOIN category_dim FOR SYSTEM_TIME AS OF U.proctime AS C ON U.category_id = C.sub_category_id;
最后根据 类目名称分组,统计出 buy 的事件数,并写入 Elasticsearch 中。
INSERT INTO top_category SELECT category_name, COUNT(*) buy_cnt FROM rich_user_behavior WHERE behavior = 'buy' GROUP BY category_name;
提交上述查询后,在 Kibana 中创建top_category的 index pattern,然后在 Dashboard 中创建一个"Horizontal Bar"条形图,
选择top_category索引,按照如下截图中的配置(左侧)画出类目排行榜,并保存。

可以看到服饰鞋包的成交量远远领先其他类目。
Kibana 还提供了非常丰富的图形和可视化选项,感兴趣的用户可以用 Flink SQL 对数据进行更多维度的分析,并使用 Kibana 展示出可视化图,并观测图形数据的实时变化。
结尾
在本文中,我们展示了如何使用 Flink SQL 集成 Kafka, MySQL, Elasticsearch 以及 Kibana 来快速搭建一个实时分析应用。整个过程无需一行 Java/Scala 代码,使用 SQL 纯文本即可完成。期望通过本文,可以让读者了解到 Flink SQL 的易用和强大,包括轻松连接各种外部系统、对事件时间和乱序数据处理的原生支持、维表关联、丰富的内置函数等等。希望你能喜欢我们的实战演练,并从中获得乐趣和知识!
本文章转自:https://github.com/wuchong/flink-sql-demo#%E5%87%86%E5%A4%87