Rethinking the Inception Architecture for Computer Vision
论文地址:https://arxiv.org/abs/1512.00567
Abstract
介绍了卷积网络在计算机视觉任务中state-of-the-art。分析现在现状,本文通过适当增加计算条件下,通过suitably factorized convolutions 和 aggressive regularization来扩大网络。并说明了取得的成果。
1. Introduction
介绍AlexNet后,推更深网络模型的提出。然后介绍GoogLeNet 考虑了内存和计算资源,五百万个参数,比六千万参数的 AlexNet 少12倍, VGGNet 则是AlexNet 的参数三倍多。提出了GoogLeNet 更适合于大数据的处理,尤其是内存或计算资源有限制的场合。原来Inception 架构的复杂性没有清晰的描述。本文主要提出了一些设计原理和优化思路。
2. General Design Principles
2.1避免特征表示瓶颈,尤其是在网络的前面。前馈网络可以通过一个无环图来表示,该图定义的是从输入层到分类器或回归器的信息流动。要避免严重压缩导致的瓶颈。特征表示尺寸应该温和的减少,从输入端到输出端。特征表示的维度只是一个粗浅的信息量表示,它丢掉了一些重要的因素如相关性结构。
2.2高纬信息更适合在网络的局部处理。在卷积网络中逐步增加非线性激活响应可以解耦合更多的特征,那么网络就会训练的更快。
2.3空间聚合可以通过低纬嵌入,不会导致网络表示能力的降低。例如在进行大尺寸的卷积(如3*3)之前,我们可以在空间聚合前先对输入信息进行降维处理,如果这些信号是容易压缩的,那么降维甚至可以加快学习速度。
2.4平衡好网络的深度和宽度。通过平衡网络每层滤波器的个数和网络的层数可以是网络达到最佳性能。增加网络的宽度和深度都会提升网络的性能,但是两者并行增加获得的性能提升是最大的。所以计算资源应该被合理的分配到网络的宽度和深度。
3. Factorizing Convolutions with Large Filter Size
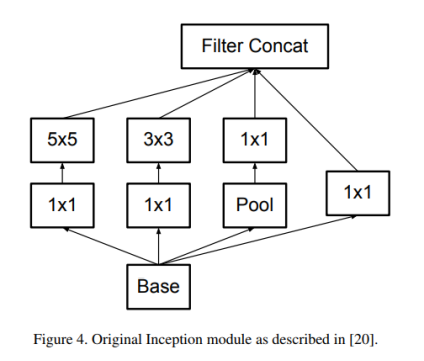
GoogLeNet 网络优异的性能主要源于大量使用降维处理。这种降维处理可以看做通过分解卷积来加快计算速度的手段。在一个计算机视觉网络中,相邻激活响应的输出是高度相关的,所以在聚合前降低这些激活影响数目不会降低局部表示能力。
3.1. Factorization into smaller convolutions
大尺寸滤波器的卷积(如5*5,7*7)引入的计算量很大。例如一个 5*5 的卷积比一个3*3卷积滤波器多25/9=2.78倍计算量。当然5*5滤波器可以学习到更多的信息。那么我们能不能使用一个多层感知器来代替这个 5*5 卷积滤波器。受到NIN的启发,用下面的方法,如图进行改进。
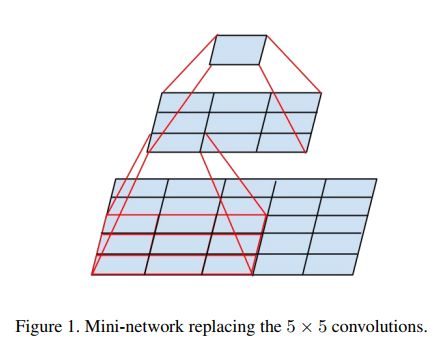
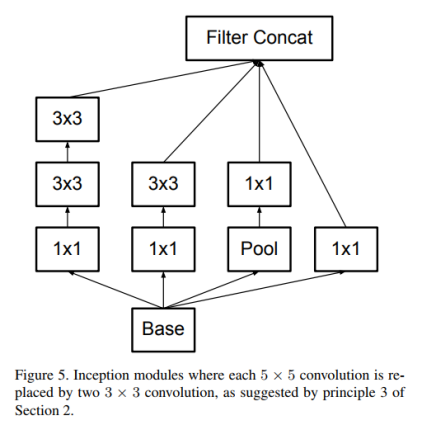
5*5卷积看做一个小的全链接网络在5*5区域滑动,我们可以先用一个3*3的卷积滤波器卷积,然后再用一个全链接层连接这个3*3卷积输出,这个全链接层我们也可以看做一个3*3卷积层。这样我们就可以用两个3*3卷积级联起来代替一个 5*5卷积。如图4,5所示。
3.2. Spatial Factorization into Asymmetric Convolutions
空间上分解为非对称卷积,受之前启发,把3*3的卷积核分解为3*1+1*3来代替3*3的卷积。如图三所示,两层结构计算量减少33%。
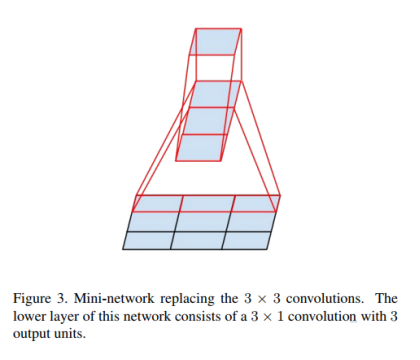
4. Utility of Auxiliary Classifiers
引入了附加分类器,其目的是从而加快收敛。辅助分类器其实起着着regularizer的作用。当辅助分类器使用了batch-normalized或dropout时,主分类器效果会更好。
5. Efficient Grid Size Reduction
池化操作降低特征图大小,使用两个并行的步长为2的模块, P 和 C。P是一个池化层,然后将两个模型的响应组合到一起来更多的降低计算量。

6. Inception-v2
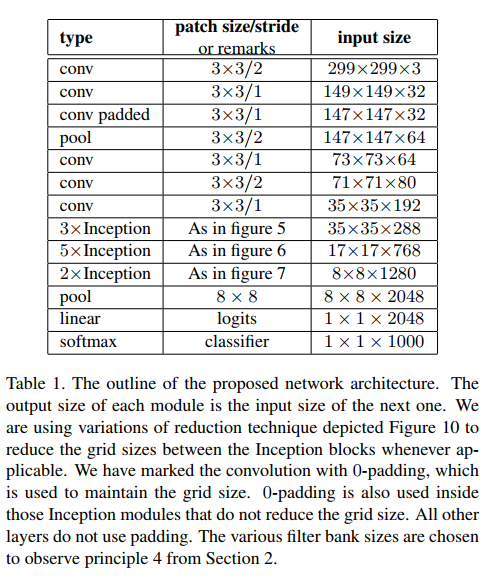
把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍。
7. Model Regularization via Label Smoothing
输入x,模型计算得到类别为k的概率

假设真实分布为q(k),交叉熵损失函数
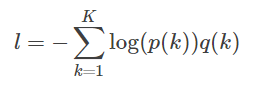
最小化交叉熵等价最大化似然函数。交叉熵函数对逻辑输出求导
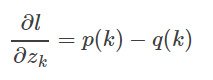
引入一个独立于样本分布的变量u(k)
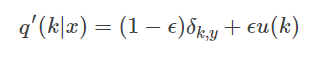
8. Training Methodology
TensorFlow 。
batch-size=32,epoch=100。SGD+momentum,momentum=0.9。
RMSProp,decay=0.9,ϵ=0.1。
lr=0.045,每2个epoch,衰减0.94。
梯度最大阈值=2.0。
9. Performance on Lower Resolution Input
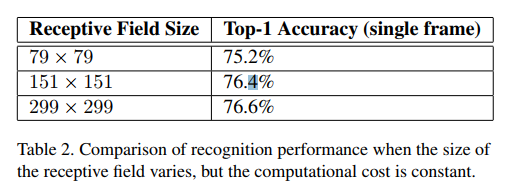
对于低分辨有图像,使用“高分辨率”receptive field。简单的办法是减小前2个卷积层的stride,去掉第一个pooling层。做了三个对比实验,实验结果
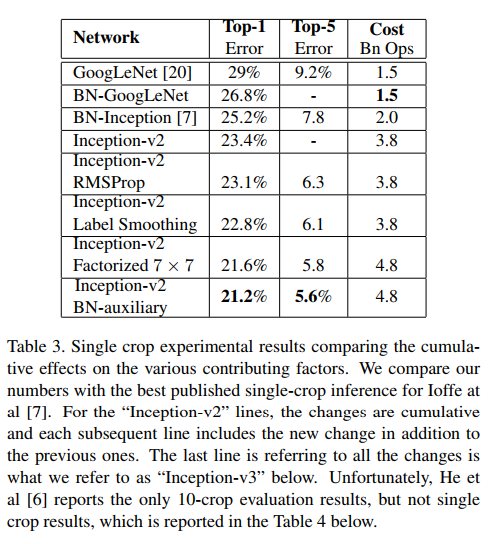
10. Experimental Results and Comparisons
实验结果和对比

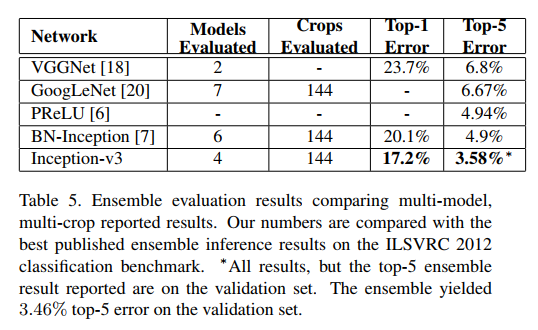
11. Conclusions
提供了几个扩大规模的设计原则卷积网络,并在其背景下进行了研究初始架构。这个指导可以导致很高的性能视觉网络有一个相对较小的计算成本比较简单,更单一架构。参数有效减小,计算量降低。我们还表明,输入分辨率79×79仍可以达到高达高质量结果。这可能有助于检测较小物体的系统。 我们研究了如何在神经网络中进行因式分解和积极维度降低可以导致网络具有相对低的计算成本,同时保持高质量。较低参数计数和附加正则化与批量归一化辅助分类器和标签平滑的组合允许在相对适度的训练集上训练高质量网络。
本文参考的博客
https://arxiv.org/abs/1512.00567