脚本原子化设计理念
运维的目标:运维当中重复着大量相同相似的工作,机器规模数量一上来,则需要考虑自动化运维,尽量做到第一次人工处理,后面都依赖脚本或者工具和WEB化来完成。这样编写shell、python脚本变得非常重要,不仅可以替代很多重复工作,而且提高效率和减少人工失误率,我建议即使公司只有10台服务器,最低标准也要脚本化。然而我发现工作中很多运维人员编写出来的脚本质量太差,并且每个脚本都在重复很多代码,用数据库名词来说就叫做冗余,这样触发我写该文章的目的,设计脚本原子化(该名词由腾讯某位大牛提出来的)
一、设计初衷
1. 运维在日常的工作中可能会写很多脚本来完成特定的一些功能,比如运维A写个版本发布的代码,里面会有文件推送的逻辑,运维B想实现一个远程脚本执行的功能,可能在他的代码里也有文件推送的逻辑。在没有引入原子化设计的概念下,运维人员用各自的方式来实现文件推送这块的逻辑。这样一来工作效率会很低,运维人员都在重复的造轮子,而且这个轮子只适合他自己的业务场景

2. 在引入原子化设计后,我们尽量将脚本的一些常用逻辑抽出来,做成一个公用的模块,这个模块就可以成为一个原子。有了原子,运维不用再关心这些基础的模块怎么去实现,而是只关心上层的逻辑,当他需要一个基础功能时,只需要去原子资源池里找,找到后然后调用这个原子即可。

这样设计有以下方面的好处:
(1).提高运维开发效率
运维不需要再从头到尾写他的逻辑代码了,而是转而去资源池找他需要的原子,然后再把这些原子拼接起来。
(2).脚本充分解耦
因为脚本是一个个原子组成的,出现时易于排查。
二、原子化设计规范
所谓脚本原子,就相当于是一个脚本(如:python),完成一个特定的功能。用户不用关心里面的逻辑是什么样的,只需要知道这个原子是干什么的,然后向这个原子传入事先约定好的参数(类型API),然后根据原子的输出来判断原子的执行状态。

Demo:
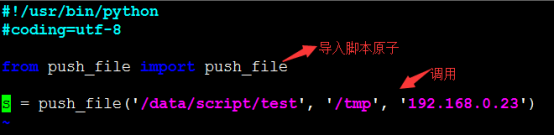
1.编写原子脚本
cat push_fle.py
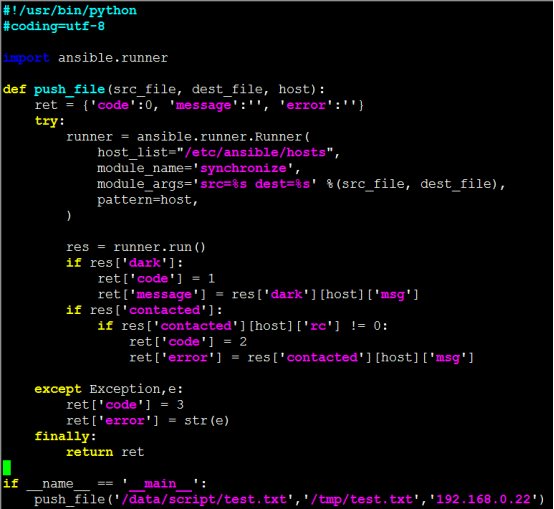
该原子实现了一个文件推送的功能,它需要用户提供三个参数,源文件路径、目的文件路径、推送的机器,返回的结果是一个字典,包括状态码、正确信息、错误信息。
2.原子调用
运维调用原子建议用python来实现。因为shell在调用python脚本时是作为该shell脚本的子进程出现的,如果原子异常退出,shell脚本还是会往下执行的,而且shell在调用python脚本时对它的返回结果也不好获取