一、零碎知识点
- 准确率和召回率总是搞不清楚概念:https://blog.csdn.net/zk_j1994/article/details/78478502
池塘有1400条鲤鱼,300只虾和300只乌龟,我们的目的是打捞一次打捞上所有的鲤鱼。结果我们捞上来700条鲤鱼,200只虾和100只乌龟。那么:
精确率:目标成果占总成果的比例,700/700+200+100 = 70%
召回率:目标成果占实际目标成果的比例,700/1400=50%
我们可以进一步理解:精确率是结果中我的目标结果的比率,召回率是有多少我想要的结果被成功“打捞”上来了。 TypeError: 'str' object is not callable: 通常是由于前面定义变量名为str了。- 跑新数据的时候验证集数据量可能大了一些,
tensorflow allocation exceeds 10% of system memory.
cat /proc/meminfo | grep MemTotal 140G 内存大小
cat /proc/cpuinfo | grep "physical id" | uniq | wc -l CPU个数 8个
With device(‘/cpu:0’) 不区分设备号 统一用0来表示, 所以CPU不能像GPU一样把数据分配到设备上面。
Resource exhausted : OOM when allocating tensor with shape(27757, 10950, 300) Caused by text-embedding/embedding_lookup 根据这条警告减少某个维度的大小,一般batch调小一点,max_length调小一点试一下。
4. https://blog.csdn.net/u010223750/article/details/51437854 深度学习在文本分类中的应用
https://github.com/zackhy/TextClassification/blob/master/train.py 可以动手实践一下!
5. https://www.leiphone.com/news/201709/QJAIUzp0LAgkF45J.html
Vscode 代码提示很慢:左下角齿轮setting-text editor-delay = 0
二、LSTM学习
https://zybuluo.com/hanbingtao/note/541458
Lstm 是 改进后的 rnn,因为RNN无法解决长距离的依赖问题。
我们先学习一下RNN的原理知识:
首先提出语言模型中的N-gram模型,假设一个词出现的频率与前面N个词有关,但是N越大,模型便会占用越大的存储空间。RNN却在理论上可以往前看任意多个词。
循环神经网络的隐藏层的值不仅仅取决于当前这次的输入X,还取决于上一次隐藏层的值S。
循环神经网络:

双向循环神经网络:
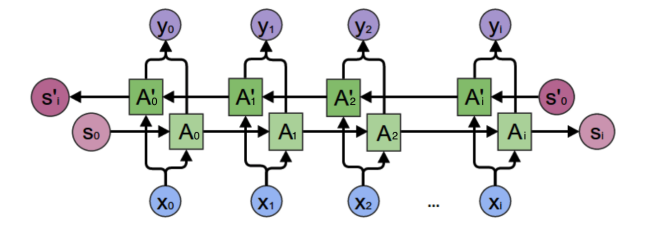
深度循环神经网络:多个 隐藏层
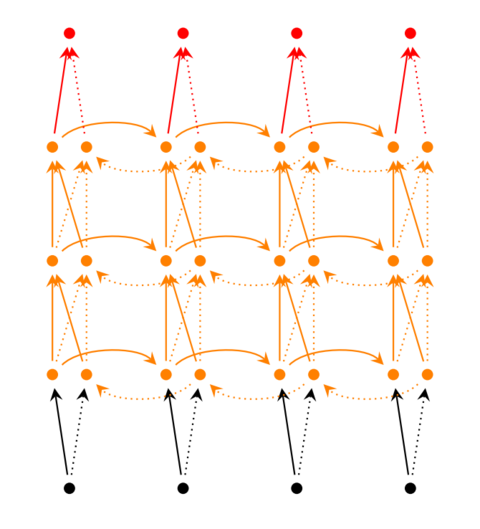
但是,前面介绍的几种RNN模型并不能很好地处理较长的序列,因为在训练中很可能发生梯度爆炸和梯度消失,从而使RNN无法捕捉到长距离的影响。
LSTM的思路:
原始RNN的隐藏层只有一个状态H,它对于短期的输入非常敏感,我们可以再增加一个状态C,让它保存长期的状态。
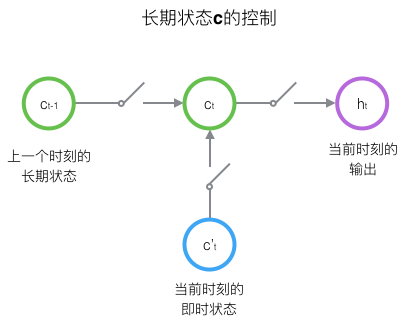
LSTM的关键是如何控制长期状态C,思路是使用三个控制开关。第一个开关,控制继续保存长期状态;第二个开关负责控制把即时状态输入到长期状态;第三个状态控制是否把长期状态C作为当前LSTM的输出。
Tensorflow LSTM函数
Outputs, state = tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
Final_state[0].h 没有H这个属性
outputs形状为 [ batch_size, max_time, cell.output_size ]
Max_time 是最长句子的单词数量,output_size是rnn cell中神经元的个数。
State 是一个tensor, state是最终的状态,也就是序列中最后一个cell输出的状态,[batchsize, cell.outputsize]
tf.contrib.rnn.LSTMCell():LSTM的一个单元细胞定义
李宏毅老师的课堂笔记:
1.Output of hidden layer are stored in the memory and can be considered as another input. 要给memory一个初始值。改变序列顺序结果会变。同一个network在不同的时间点的图像。Elman network 存储隐藏层的值, jordan network存储output。
2.Lstm 写到memory cell前有个闸门,决定说什么时候能写进去;还有个output gate输出到神经网络的其他部分。Forget gate忘记cell中的内容。
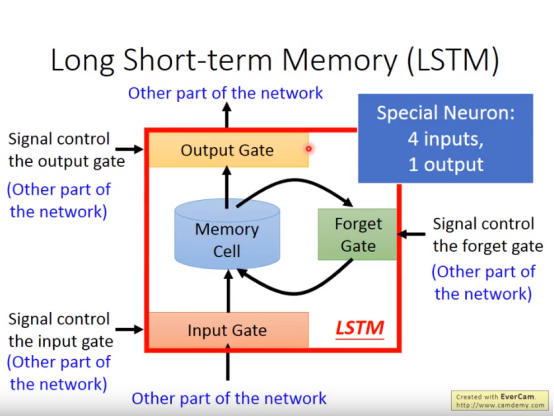
四个输入和一个输出
tf.nn.dynamic_rnn(cell,inputs,sequence_length=None, initial_state=None,dtype=None, parallel_iterations=None,swap_memory=False, time_major=False, scope=None)
http://www.cnblogs.com/wzdLY/p/10071962.html
Dynamic : 输入数据的time_step不一定相同,如果长短不一,会自动跟短的补0,但处理的时候不会处理0,在0前面就截止了。
Time_major : true tensor must be shaped [max_time_length, batchsize ,depth] false: [batchsize, max_time, depth], output 为[batchsize, max_time, cell.output_size] ``output_size就是cell的num_units`.这里的outputs 是每个cell输出的叠加,而state是一个元组类型的数据,有c and h两个变量,存储的是LSTM的最后一个cell的输出状态。
Dynamic_rnn 相当于调用了N次call函数。