目录
前言
安装模块
例1:创建一个excel 文件,并写入不同类的内容
例2:写入时间
例3:创建sheet
例4 :操作单元格
例5 :操作行/列/指定区域
例6:显示小数
例7:获取所有的行对象
例8:获取所有的列对象
例9:单元格类型
例10:公式
例11:合并单元格/取消合并单元格
例12:插入图片
前言
python中操作excel的模块有很多,比如xlrd,xlwt,openpyxl,xlutils等。前两个是一套,一个读一个写。注意:xlwt模块,只能支持到excel2003,也就是扩展名为.xls的excel;xlrd模块可以支持读取07版本,也就是.xlsx扩展名的excel。每个模块都有一些优缺点,本文以openpyxl模块为例来进行介绍。
安装模块
安装openpyxl和pillow(在文件中插入图片时使用)
py -3 -m pip install openpyxl==2.5.4(指定版本安装)
py -3 -m pip install pillow
一、创建excel 文件,并写入不同的内容
# -*- coding: utf-8 -*-
import locale
from openpyxl import Workbook
wb = Workbook() #创建文件对象
#获取第一个sheet
ws = wb.active
# 将数据写入到指定的单元格
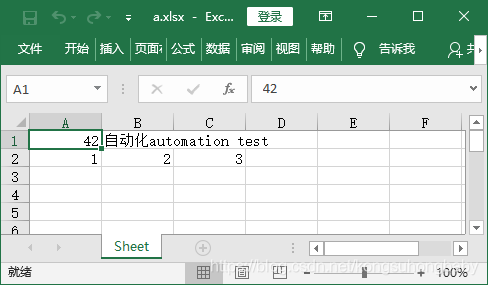
ws['A1'] = 42 #写入数字
ws['B1'] = "自动化"+"automation test" #写入中文
ws.append([1, 2, 3]) #写入多个单元格
#保存为a.xlsx
wb.save("a.xlsx")
运行结果
二、写入时间
from openpyxl import Workbook
import datetime
import time
import locale
wb = Workbook() #创建文件对象
ws = wb.active #获取第一个sheet
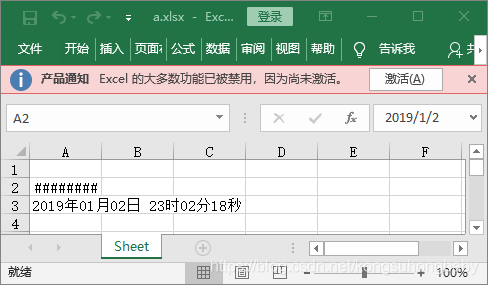
ws['A2'] = datetime.datetime.now() #写入一个当前时间
#写入一个自定义的时间格式
locale.setlocale(locale.LC_CTYPE, 'chinese')
ws['A3'] =time.strftime("%Y年%m月%d日 %H时%M分%S秒",time.localtime())
# Save the file
wb.save("sample.xlsx")
运行结果
三、创建sheet
前面的例子都是操作默认创建的sheet,也可以用create_sheet()方法生成指定名称的sheet进行操作。
from openpyxl import Workbook
wb = Workbook()
ws = wb.create_sheet("kongsh")
ws1 = wb.create_sheet("Mysheet")
ws1.title = "New Title"
ws2 = wb.create_sheet("Mysheet", 0) #设定sheet的插入位置
ws2.title = u"测试用例"
#设置sheet名的背景色
ws1.sheet_properties.tabColor = "1072BA"
#获取某个sheet对象
print (wb["测试用例"])
print (wb["New Title" ])
#获取所有的sheet名字
print (wb.sheetnames)
for sheet_name in wb.sheetnames:
print (sheet_name)
print(wb[sheet_name])
#遍历获取sheet对象,按照sheet顺序获取
for sheet in wb:
print (sheet)
print(sheet.title)#获取sheet名称
#复制一个sheet
wb["New Title" ]["A1"]="gloryroad"
source = wb["New Title" ]
target = wb.copy_worksheet(source)
target.title="New copy Title"
#保存文件
wb.save("a.xlsx")
运行结果

四、操作单元格
# -*- coding: utf-8 -*-
from openpyxl import Workbook
wb = Workbook()
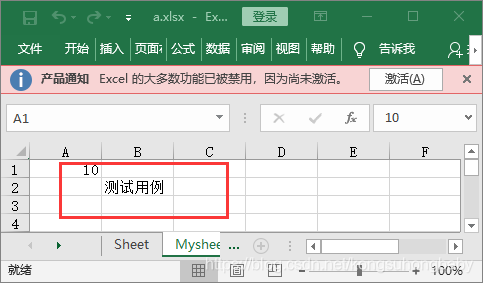
ws1 = wb.create_sheet("Mysheet") #创建一个sheet
ws1["A1"]=123.11
ws1["B2"]="测试用例"
#行号和列号必须从1开始,获取指定单元格的内容
d = ws1.cell(row=1, column=1, value=10)
#指定行列坐标组成的字符串,value属性就是单元格的值
print (ws1["A1"].value)
print (ws1["B2"].value)
print (d.value)
print (ws1.cell(row=4,column=2).value)
# 保存文件
wb.save("a.xlsx")
运行结果
五、操作行/列/指定区域
# -*- coding: utf-8 -*-
from openpyxl import Workbook, load_workbook
wb = Workbook()
ws1 = wb.create_sheet("Mysheet") #创建一个sheet
ws1["A1"]=1
ws1["A2"]=2
ws1["A3"]=3
##ws1["A10"]=3
ws1["B1"]=4
ws1["B2"]=5
ws1["B3"]=6
ws1["C1"]=7
ws1["C2"]=8
ws1["C3"]=9
#操作单列
print (ws1["A"])
for cell in ws1["A"]:
print (cell.value)
#最大有效行和列
print(ws1.max_row,ws1.max_column)
#最小有效行和列
print(ws1.min_row,ws1.min_column)
print(ws1.columns)
print(ws1.rows)
#操作单列
print (ws1["A"])
for cell in ws1["A"]:
print (cell.value)
#操作多列,获取每一个值
print (ws1["A:C"])
for column in ws1["A:C"]:
for cell in column:
print (cell.value)
#操作多行
row_range = ws1[1:3]
print(row_range)
for row in row_range:
for cell in row:
print(cell.value)
#指定一个操作的区域
print ("*"*50)
for row in ws1.iter_rows(min_row=1, min_col=1,
max_col=3, max_row=3):
for cell in row:
print (cell.value)
#获取所有行
print (ws1.rows)
for row in ws1.rows:
print (row)
print ("*"*50)
#获取所有列
print (ws1.columns)
for col in ws1.columns:
print (col)
# 保存文件
wb.save("a.xlsx")
运行结果

六、显示小数
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook('a.xlsx')
wb.guess_types = True#将单元格的百分数显示为小数
#wb.guess_types = False#将单元格的百分数显示为百分数
ws=wb.active
ws["D1"]="12%"
print (ws["D1"].value)
# 保存
wb.save("a.xlsx")
运行结果

七、获取所有的行对象
#coding=utf-8
from openpyxl import Workbook
from openpyxl import load_workbook
#加载一个已经存在的excel文件
wb = load_workbook('a.xlsx')
ws=wb.active
rows=[]
for row in ws.iter_rows():
rows.append(row)
print (rows) #所有行
print (rows[0]) #获取第一行
print (rows[0][0]) #获取第一行第一列的单元格对象
print (rows[0][0].value) #获取第一行第一列的单元格对象的值
print (rows[len(rows)-1]) #获取最后行
print (rows[len(rows)-1][len(rows[0])-1]) #获取第后一行和最后一列的单元格对象
print (rows[len(rows)-1][len(rows[0])-1].value) #获取第后一行和最后一列的单元格对象的值
八、获取所有的列对象
#coding=utf-8
from openpyxl import load_workbook
wb = load_workbook('sample.xlsx')
ws=wb.active
cols=[]
cols = []
for col in ws.iter_cols():
cols.append(col)
print (cols) #所有列
print (cols[0]) #获取第一列
print (cols[0][0]) #获取第一列的第一行的单元格对象
print (cols[0][0].value) #获取第一列的第一行的值
print ("*"*30)
print (cols[len(cols)-1]) #获取最后一列
print (cols[len(cols)-1][len(cols[0])-1]) #获取最后一列的最后一行的单元格对象
print (cols[len(cols)-1][len(cols[0])-1].value) #获取最后一列的最后一行的单元格对象的值
运行结果

九、单元格类型
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
import datetime
wb = load_workbook('a.xlsx')
ws=wb.active
wb.guess_types = True
ws["A1"]=datetime.datetime(2010, 7, 21)
print (ws["A1"].number_format)
ws["A2"]="12%"
print (ws["A2"].number_format)
ws["A3"]= 1.1
print (ws["A3"].number_format)
ws["A4"]= "中国"
print (ws["A4"].number_format)
# 保存文件
wb.save("a.xlsx")
运行结果
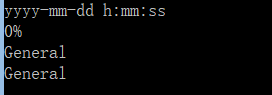
说明:如果是常规,显示general,如果是数字,显示'0.00_ ',如果是百分数显示0%
十、公式
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook('a.xlsx')
ws1=wb.active
ws1["A1"]=1
ws1["A2"]=2
ws1["A3"]=3
ws1["A4"] = "=SUM(1, 1)"
ws1["A5"] = "=SUM(A1:A3)"
print (ws1["A4"].value) #打印的是公式,不是公式计算后的值,程序无法取到计算后的值
print (ws1["A5"].value) #打印的是公式,不是公式计算后的值,程序无法取到计算后的值
# 保存文件
wb.save("a.xlsx")
运行结果

十一、合并单元格/取消合并单元格
# -*- coding: utf-8 -*-
from openpyxl import Workbook
from openpyxl import load_workbook
wb = Workbook()
ws = wb.active
ws.merge_cells('A2:D2')
ws.unmerge_cells('A2:D2')#取消合并
# 或者
ws.merge_cells(start_row=2,start_column=1,end_row=2,end_column=4)
ws.unmerge_cells(start_row=2,start_column=1,end_row=2,end_column=4)#取消合并
#保存文件
wb.save("a.xlsx")
十二、插入图片
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
from openpyxl.drawing.image import Image
wb = load_workbook('a.xlsx')
ws1=wb.active
img = Image(r'F:important icon_xx.png')
ws1.add_image(img, 'A1')
# 保存文件
wb.save("a.xlsx")
运行结果

十三、python简单操作读excel
以如下excel文件为例进行操作
文件名为demo,有两个sheet,名为工作表1和工作表2
工作表1中有如下数据
简单使用

# coding=utf-8
import xlrd
# 打开文件
data = xlrd.open_workbook('file/demo.xlsx')
# 查看工作表
data.sheet_names()
print("sheets:" + str(data.sheet_names()))
# 通过文件名获得工作表,获取工作表1
table = data.sheet_by_name('工作表1')
# 打印data.sheet_names()可发现,返回的值为一个列表,通过对列表索引操作获得工作表1
# table = data.sheet_by_index(0)
# 获取行数和列数
# 行数:table.nrows
# 列数:table.ncols
print("总行数:" + str(table.nrows))
print("总列数:" + str(table.ncols))
# 获取整行的值 和整列的值,返回的结果为数组
# 整行值:table.row_values(start,end)
# 整列值:table.col_values(start,end)
# 参数 start 为从第几个开始打印,
# end为打印到那个位置结束,默认为none
print("整行值:" + str(table.row_values(0)))
print("整列值:" + str(table.col_values(1)))
# 获取某个单元格的值,例如获取B3单元格值
cel_B3 = table.cell(3,2).value
print("第三行第二列的值:" + cel_B3)
获得所有的数据
# coding=utf-8
import xlrd
def read_xlrd(excelFile):
data = xlrd.open_workbook(excelFile)
table = data.sheet_by_index(0)
for rowNum in range(table.nrows):
rowVale = table.row_values(rowNum)
for colNum in range(table.ncols):
if rowNum > 0 and colNum == 0:
print(int(rowVale[0]))
else:
print(rowVale[colNum])
print("---------------")
# if判断是将 id 进行格式化
# print("未格式化Id的数据:")
# print(table.cell(1, 0))
# 结果:number:1001.0
if __name__ == '__main__':
excelFile = 'file/demo.xlsx'
read_xlrd(excelFile=excelFile)
运行结果:

python修改数据
如果在项目中使用则可将内容方法稍为做修改,获得所有的数据后,将每一行数据作为数组进行返回
# coding=utf-8
import xlrd
def read_xlrd(excelFile):
data = xlrd.open_workbook(excelFile)
table = data.sheet_by_index(0)
dataFile = []
for rowNum in range(table.nrows):
# if 去掉表头
if rowNum > 0:
dataFile.append(table.row_values(rowNum))
return dataFile
if __name__ == '__main__':
excelFile = 'file/demo.xlsx'
print(read_xlrd(excelFile=excelFile))
运行结果
