我是在来到NLP实验室才接触的深度学习,我们实验室入门深度学习的门槛(可以说门槛吧),是写一个分类器,在刚开始的时候自己也是看了很多的文档以及我BOSS的代码,啃了好久,一直到现在接触了很多的任务,才慢慢的算是正式入门了。也提醒正在钻研深度学习的你,多做,多思考!下面我就以CNN作为模型来做一个情感分类(在这里是二分类,因为涉及情感有两个,0表示消极,1表示积极)。
假如我是选取5句话(5句话好画图和举例)作为一个batch(也就是一个批次,通俗来讲就是在整个大文件中选取一部分句子做一个batch一起过模型),如下:(数据格式就是句子加标签(金标))
- the film is strictly routine.|||0
- too bad.|||0
- a fun ride.|||1
- lurid and less than lucid work .|||0
- it 's worth taking the kids to .|||1
我们的任务是根据所给的句子和金标去训练模型,然后再将新的句子(测试数据)放进模型中来预测这个句子的情感,再将预测值和实际的金标值放在一起算出误差,再反向传播更新参数,不断调整模型使之能够达到最好的预测效果。
分类的步骤是:1.数据处理。就是将每个句子转化成向量矩阵去过模型,怎么转化呢?看上面所给出的五句话,每句话长度是不一致的,所以我们先找出每个batch(批次)中最长的句子,根据它的长度构建feature map,其他短句子不足的地方用pad填充(你会在建词典的时候明白pad在词典中的唯一标识为1)假设这些句子都在词典中。最长的句子是6(即6个单词),下面构建feature map:(图片是在wps上画好截下来的)

以第一句话为例建立feature map,可以看到这句话是五个单词,不够6个,就用<pad>进行了填充,那小格格表示的是每个单词的向量表示,初始化几维就是几维。在这里假设10维(具体数据怎么处理,请参考具体代码)其余的4个句子也是如此,都是6行10列的矩阵(短句子用pad填充,同理)。
2.接下来就是过模型。假设你设置的filter_size = 1,2,3(表示定义了三种类型的卷积核((1,dim),(2,dim), (3,dim)这里的dim就是词向量的维度,在这里我设置的为10) filter_num = 5(是每种卷积核的数量),下边分别用(1,10),(2,10),(3,10)进行卷积:
用红色表示(1,10)卷积核卷积:(只显示出第一步,一次走一步,接下来卷积第二个词,第三个词,以此类推...)
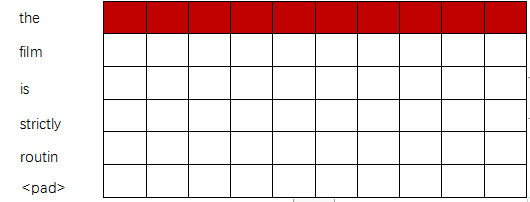
最后得到的是一个6*1的列向量:

再用(2,10)的卷积核去卷积:
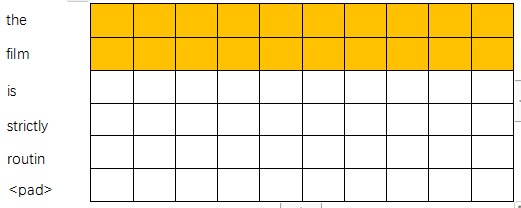
一次往下移动两个,步长为1(即交叉),可得到一个5*1的列向量:

用(3,10)卷积核进行卷积:
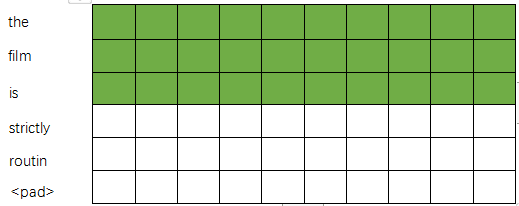
最后得到一个4*1的列向量:

因为这三种卷积核各5个,最后一个句子的feature map 经过这三个卷积核卷积得到的输出分别是6*5, 5*5, 4*5,(单词个数*单词维度),然后再经过一个maxpooling层(作用是:找出这一句话中最有信息量的一个单词,这个单词最具有代表性)所以这个句子的三个特征经过maxpooling后变成1*5, 1*5 , 1*5 ,这样就可以将三个特征cat在一起了(这样特征信息越多,模型学习的越细致)经过maxpooling层之后输出的结果就为1*15,总共5句话,每句话都是1*15,这些就组成了一个5*15的矩阵,最后过一个线性层,输出的结果就是5*n的矩阵,这个n 就是您定义的几分类(一般情况下,最后一个输出层的节点个数与分类任务的目标数相等),就比如刚开始说的二分类,最后会的出5*2的一个矩阵。
神经网络的原始输出不是一个概率值,实质上只是输入的数值做了复杂的加权和与非线性处理之后的一个值而已,那么如何将这个输出变为概率分布?这就是Softmax层的作用。下面我推荐一个博客:看这里哦,关于softmax层(这一作用就是在模型求出预测值之后,和金标比较计算交叉熵损失函数的时候应用的)的介绍,写的非常详细,很容易懂,一定要看下,多借鉴才能更好的理解。
如果对上边的卷积用到的conv2d()函数不太清楚的话,请参考博客:here ,这里边参数的意思要搞懂,还有要注意这是一个4维的Tensor,在输入句子特征图之前,要进行变换成4维(具体还是看代码吧)。多动手,多思考,才能掌握的更好!
附上我的github 情感分类代码:Mine(我的代码是参考boss框架)
我boss的情感分类代码:My boss's(写的模型很多还可以再看看bilstm,可以参考,多了解)
