早期的数据IO,由用户进程向CPU发起,应用程序与磁盘之间的 I/O 操作都是通过 CPU 的中断完成的。
CPU还要负责将磁盘缓冲区拷贝到内核缓冲区(pageCache),再从内核缓冲区拷贝到用户缓冲区。
为了减少CPU占用,产生了DMA技术,大大解放了CPU
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。
目前大多数的硬件设备,包括磁盘控制器、网卡、显卡以及声卡等都支持 DMA 技术。
传统IO方式及DMA技术图解可以参考之前一篇 https://www.cnblogs.com/ttaall/p/13738562.html
DMA技术存在的问题:
举个例子,从本地文件中发一张图片给你的好盆友。
传统的访问方式是通过 write() 和 read() 两个系统调用实现的,通过 read() 函数读取图片到到缓存区中,然后通过 write() 方法把缓存中的图片输出到网络端口。
read操作:
当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据。
如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(read buffer)中,再从读缓存拷贝到用户进程的页内存中。
write操作:
当应用程序准备好数据,执行 write 系统调用发送网络数据时,先将数据从用户空间的页缓存拷贝到内核空间的网络缓冲区(socket buffer)中,
然后再将写缓存中的数据拷贝到网卡设备完成数据发送。
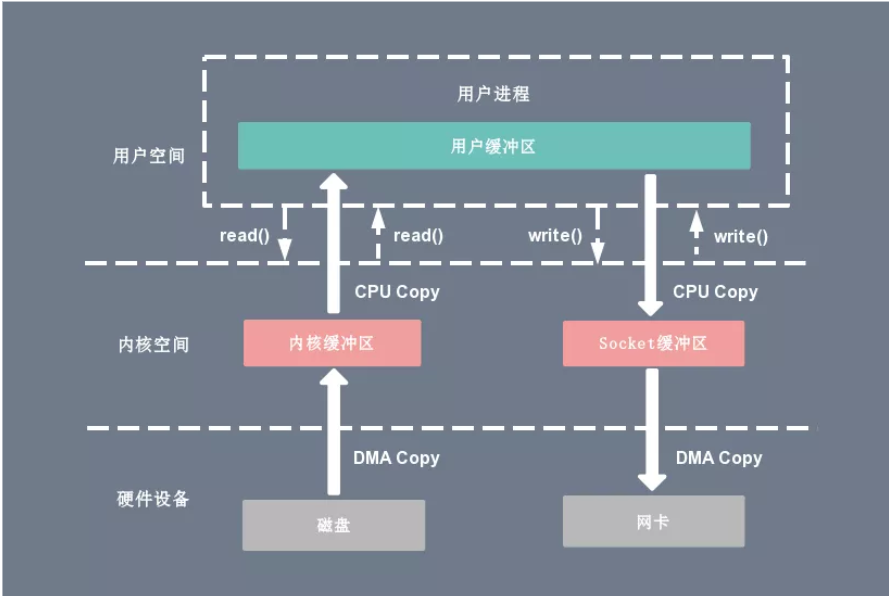
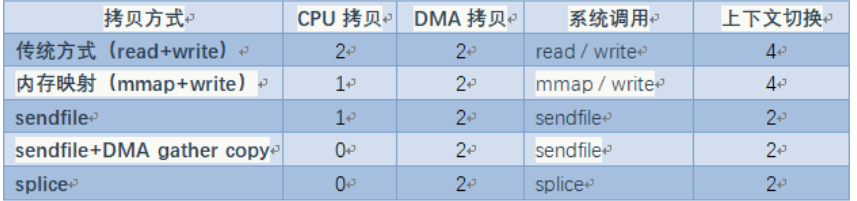
需要进行两次DMA拷贝,两次CPU拷贝,四次上下文切换
总共四次拷贝,四次切换,代价属实有点点大。
-
上下文切换:当用户程序向内核发起系统调用时,CPU 将用户进程从用户态切换到内核态;当系统调用返回时,CPU 将用户进程从内核态切换回用户态。
-
CPU 拷贝:由 CPU 直接处理数据的传送,数据拷贝时会一直占用 CPU 的资源。
-
DMA 拷贝:由 CPU 向DMA磁盘控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,从而减轻了 CPU 资源的占有率。
零拷贝的想法
1.用户态可以直接操作读写,不需要切换用户态内核态
2.尽量减少拷贝次数,尽量减少上下文切换次数
3.写时复制,需要写操作的时候再拷贝,只是读操作没必要拷贝
用户态直接IO
用户态直接 I/O 使得应用进程或运行在用户态(user space)下的库函数直接访问硬件设备。
用户态直接 I/O 只能适用于不需要内核缓冲区处理的应用程序,这些应用程序通常在进程地址空间有自己的数据缓存机制,称为自缓存应用程序,如数据库管理系统 就是一个代表。
其次,这种零拷贝机制会直接操作磁盘 I/O,由于 CPU 和磁盘 I/O 之间的执行时间差距,会造成大量资源的浪费,解决方案是配合异步 I/O 使用。
写时复制
写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中。
这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。
mmap+write零拷贝技术
以mmap+write的方式替代传统的read+write的方式,减少了一次拷贝
mmap 是 Linux 提供的一种内存映射文件方法,即将一个进程的地址空间中的一段虚拟地址映射到磁盘文件地址
使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射。
从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程。
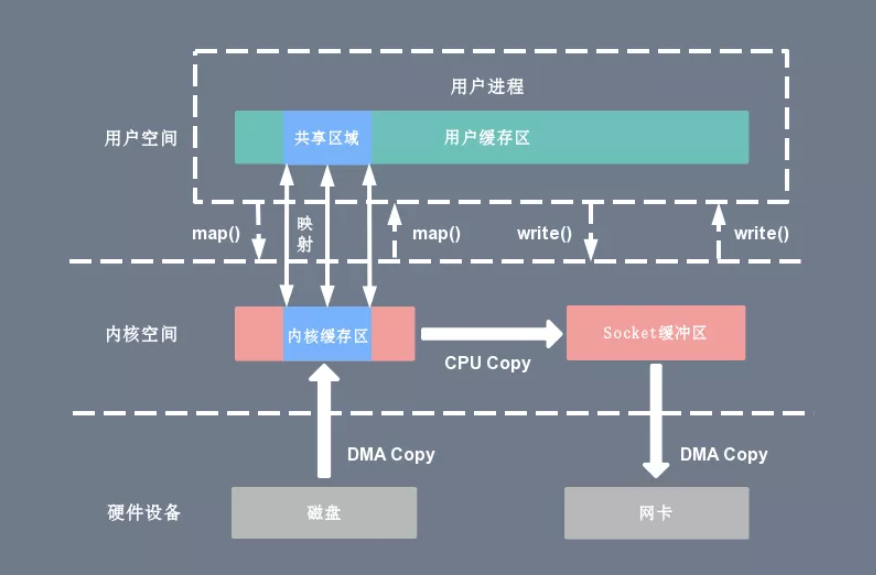
整个拷贝过程会发生 4 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝。
mmap 主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费。
Sendfile零拷贝技术
通过 Sendfile 系统调用,数据可以直接在内核空间内部进行 I/O 传输,从而省去了数据在用户空间和内核空间之间的来回拷贝。
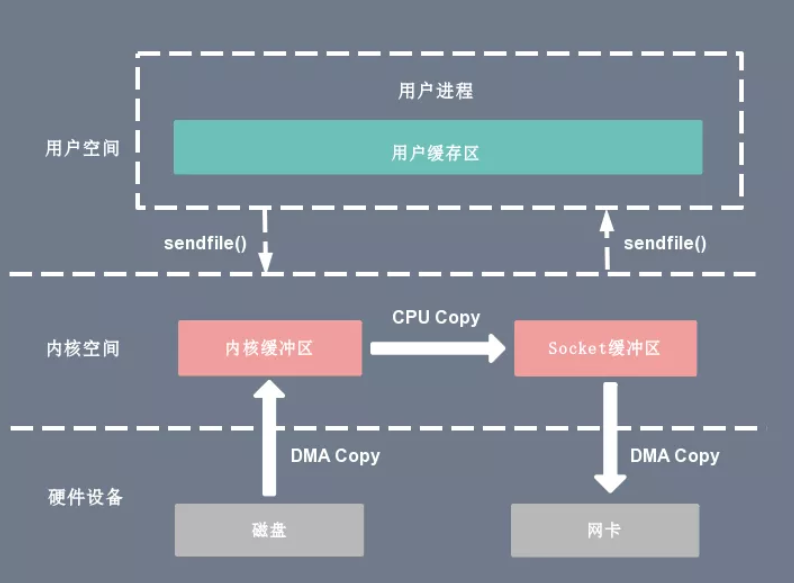
将要读取的文件缓冲区的文件 fd 和要发送的Socket缓冲区的Socket fd 传给sendfile函数,
Sendfile 调用中 I/O 数据对用户空间是完全不可见的。也就是说,这是一次完全意义上的数据传输过程。
也就是说用户程序不能对数据进行修改,而只是单纯地完成了一次数据传输过程。
整个拷贝过程会发生 2 次上下文切换,1 次 CPU 拷贝和 2 次 DMA 拷贝。
Sendfile+DMA gather copy
它只适用于将数据从文件拷贝到 socket 套接字上的传输过程。
它将内核空间的读缓冲区(read buffer)中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,
由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区(read buffer)拷贝到网卡设备中。
这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可,本质就是和虚拟内存映射的思路类似。
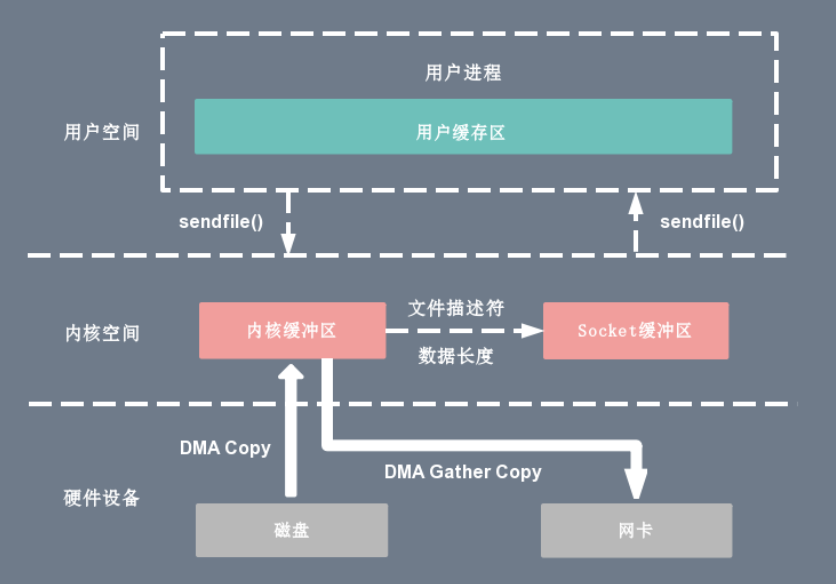
整个拷贝过程会发生 2 次上下文切换、0 次 CPU 拷贝以及 2 次 DMA 拷贝。
Splice零拷贝技术
Splice相当于在Sendfile+DMA gather copy上的提升
Splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了两者之间的 CPU 拷贝操作。
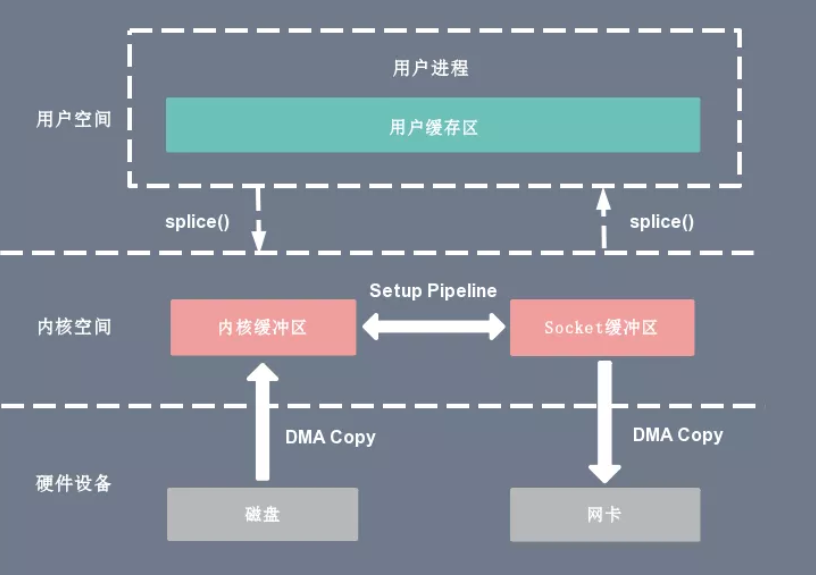
基于 Splice 系统调用的零拷贝方式,整个拷贝过程会发生 2 次上下文切换,0 次 CPU 拷贝以及 2 次 DMA 拷贝。
-
用户进程通过 splice() 函数向内核(kernel)发起系统调用,上下文从用户态(user space)切换为内核态(kernel space)。
-
CPU 利用 DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的读缓冲区(read buffer)。
-
CPU 在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline)。
-
CPU 利用 DMA 控制器将数据从网络缓冲区(socket buffer)拷贝到网卡进行数据传输。
-
上下文从内核态(kernel space)切换回用户态(user space),Splice 系统调用执行返回。
对比
无论是传统 I/O 拷贝方式还是引入零拷贝的方式,2 次 DMA Copy 是都少不了的,因为两次 DMA 都是依赖硬件完成的。
kafka实现零拷贝: sendfile函数
2.4 内核改进的的sendfile函数 + 硬件提供的DMA Gather Copy实现零拷贝,将文件通过socket传送
Kafka底层基于java.nio包下的FileChannel的transferTo: transferTo 可将一个文件直接传输到另一个文件
transferTo将FileChannel关联的文件发送到指定channel,当Comsumer消费数据,Kafka Server基于FileChannel将文件中的消息数据发送到SocketChannel
RocketMq零拷贝实现: mmap+write()
RocketMQ基于mmap + write的方式实现零拷贝
内部实现基于nio提供的java.nio.MappedByteBuffer,基于FileChannel的map方法得到mmap的缓冲区:
Netty零拷贝实现:
- 1 基于操作系统实现的零拷贝,底层基于FileChannel的transferTo方法
- 2 基于Java 层操作优化,对数组缓存对象(ByteBuf )进行封装优化,通过对ByteBuf数据建立数据视图,支持ByteBuf 对象合并,切分,当底层仅保留一份数据存储,减少不必要拷贝
加上selectorIO多路复用