实验目的
了解PageRank算法
学会用mapreduce解决实际的复杂计算问题
实验原理
1.pagerank算法简介
PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名。
pagerank是Google排名运算法则(排名公式)的一部分,pagerank是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。
Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。pagerank通过网络浩瀚的超链接关系来确定一个页面的等级。Google把从A页面到B页面的链接解释为A页面给B页面投票,Google根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票目标的等级来决定新的等级。简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
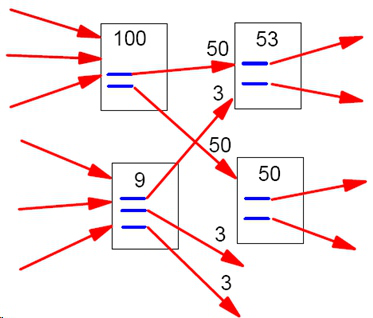
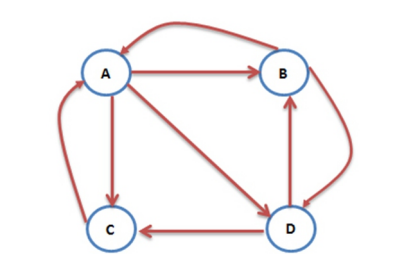
如下图一个简单的例子,互联网中的网页可以看成是一个有向图,其中网页是结点,如果网页A有链接到网页B,则存在一条有向边A->B:

2.原理介绍
有关pagerank的原理和各种情况网络上的资料比较多,我们省略掉中间的很多高深的数学证明,给出比较简单的原理介绍:
(1).PR的核心思想有2点:
如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PR值会相对较高
如果一个PR值很高的网页链接到一个其他的网页,那么被链接到的网页的PR值会相应地因此而提高
(2).WIKI上有一个PR的简便算法,它不考虑转移概率,而是采用的是迭代的方式,每次都更新所有网页的PR值,更新的方式就是将每个网页的PR值平摊分给它指向的所有网页,每个网页累计所有指向它的网页平摊给它的值作为它该回合的PR值,直到全部网页的PR值收敛了或者满足一定的阈值条件就停止。
(3).ABCD的初始PR值都是1,现在A投票给BCD,所以用所以给BCD的PR值都加上A的PR/3,同理,B投票给AD,所以AD的PR值都要加上B的PB/2,CD同理,这样一轮完成后,ABCD都有了新的PR值,再重复上面的步骤,直到相邻两次的误差达到精度要求为止。
(4).上面的算法有个问题,如果每次都把原始的PR值和获得的投票的PR值直接相加作为新的PR值,结果容易受到初始误差的影响,所以有一种方法是选择将原有的PR值乘以一个系数加上获得投票的PR和乘以另一个系数,这样得到的结果更合理,经过很多互联网公司的实验结果来看,一般会使用0.85和0.15两个系数。
3.PageRank简单计算
假设一个由只有4个页面组成的集合:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。

换句话说,根据链出总数平分一个页面的PR值。

以下所示的例子可以更容易理解PageRank的具体计算过程:
实验环境
1.操作系统
操作机:Windows_7
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1)最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2)首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3)其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4)最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1)插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2)在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3)匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4)资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
智能选择
丰富的导航模式
历史记录功能
JUnit的完美支持
对重构的优越支持
编码辅助
灵活的排版功能
XML的完美支持
动态语法检测
代码检查等等




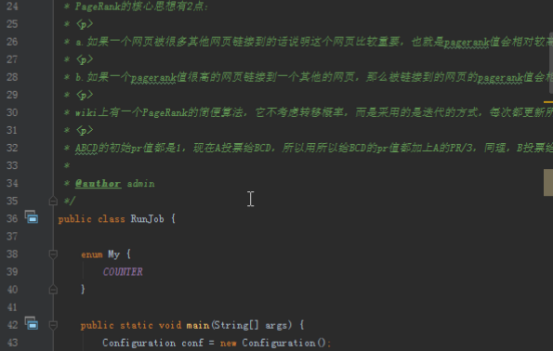
步骤2:代码类实现分析
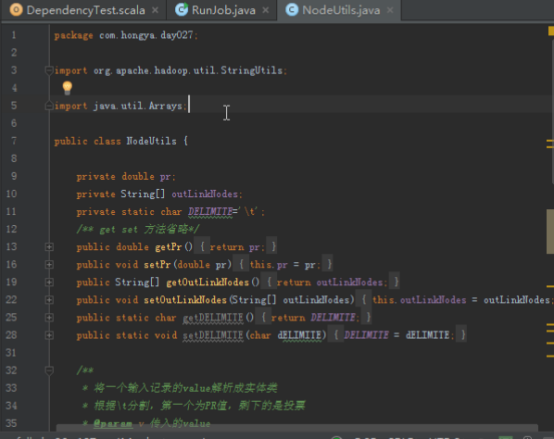
解析每个记录中的value的工具类NodeUtils,代码比较简单,主要有三个方法,解析value,判断是否有投票,将节点转化为字符串。
2.1PageRankMapper,读进来一行记录,解析得到源节点,投票节点,写出每个节点的pr值,大家可以参照hellohadoop|com.hongya|day027|RunJob中PageRankMapper方法的代码。
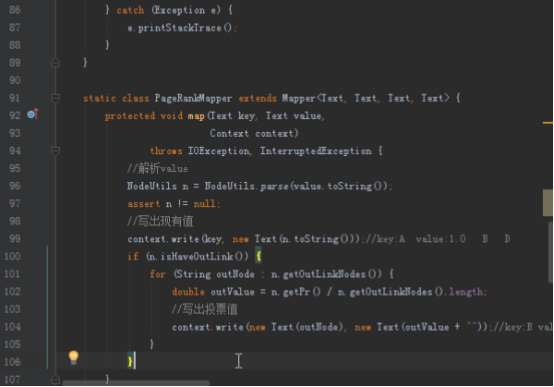
static class PageRankMapper extends Mapper<Text, Text, Text, Text> {
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
//解析value
NodeUtils n = NodeUtils.parse(value.toString());
assert n != null;
//写出现有值
context.write(key, new Text(n.toString()));//key:A value:1.0 B D
if (n.isHaveOutLink()) {
for (String outNode : n.getOutLinkNodes()) {
double outValue = n.getPr() / n.getOutLinkNodes().length;
//写出投票值
context.write(new Text(outNode), new Text(outValue + ""));//key:B value:0.5
}
}
}
}
2.2PageRankReducer直接得到map的数据后,累加得到的投票的pr值,然后写出。
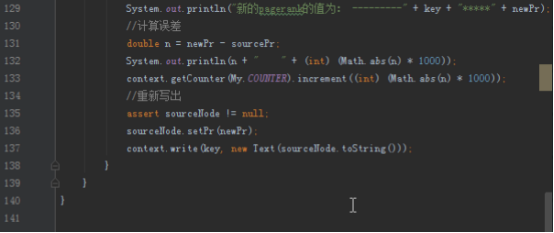
static class PageRankReducer extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values,
Context context)
throws IOException, InterruptedException {
double sum = 0;
/** sourceNode和sourcePr分别代表源节点和源PR,sum计算所有的投票的值*/
NodeUtils sourceNode = null;
double sourcePr = 0;
for (Text i : values) {
NodeUtils n = NodeUtils.parse(i.toString());
assert n != null;
if (n.isHaveOutLink()) {
sourceNode = n;
sourcePr = n.getPr();
} else {
sum = sum + n.getPr();
}
}
double newPr = sum * 0.85 + 0.15 * sourcePr;
System.out.println("新的pagerank的值为: ---------" + key + "*****" + newPr);
//计算误差
double n = newPr - sourcePr;
System.out.println(n + " " + (int) (Math.abs(n) * 1000));
context.getCounter(My.COUNTER).increment((int) (Math.abs(n) * 1000));
//重新写出
assert sourceNode != null;
sourceNode.setPr(newPr);
context.write(key, new Text(sourceNode.toString()));
}
}
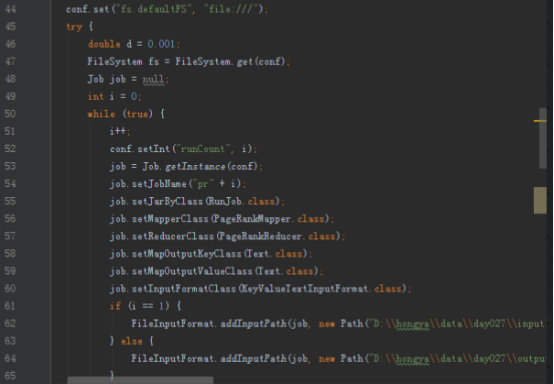
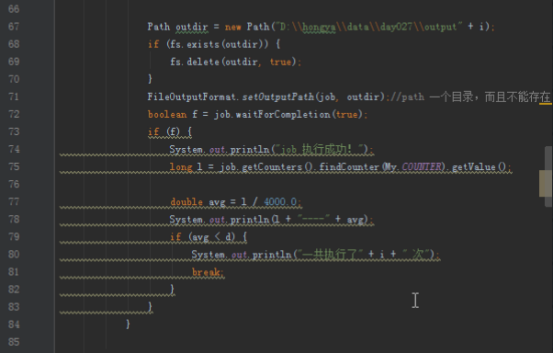
由于实现过程需要不断迭代,知道误差达到精度要求,所以job需要记录误差,不断循环运行mapreduce,具体参考hellohadoop|com.hongya|day027|RunJob。