实验课程名称:大数据处理技术
实验项目名称:hadoop集群实现PageRank算法
实验类型:综合性
实验日期:2018年 6 月4日-6月14日
|
学生姓名 |
吴裕雄 |
学号 |
15210120331 |
|
班级 |
软工三班 |
专业名称 |
软件工程 |
|
实验组 其他成员 |
无 |
||
|
实验地点 |
F110 |
||
|
实验成绩 (教师签名) |
|||
实验目的与要求
了解PageRank算法
学会用mapreduce解决实际的复杂计算问题
搭建hadoop分布式集群
编写mapreduce代码
根据输入的网页链接数据,能够得到最终的pagerank结果
实验原理与内容
一、什么是pagerank
PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO(^_^)。PageRank算法计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。它的思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟后,跳转到该网页所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank就是估计这个悠闲的上网者分布在各个网页上的概率。
二、最简单pagerank模型
互联网中的网页可以看出是一个有向图,其中网页是结点,如果网页A有链接到网页B,则存在一条有向边A->B,下面是一个简单的示例:

这个例子中只有四个网页,如果当前在A网页,那么悠闲的上网者将会各以1/3的概率跳转到B、C、D,这里的3表示A有3条出链,如果一个网页有k条出链,那么跳转任意一个出链上的概率是1/k,同理D到B、C的概率各为1/2,而B到C的概率为0。一般用转移矩阵表示上网者的跳转概率,如果用n表示网页的数目,则转移矩阵M是一个n*n的方阵;如果网页j有k个出链,那么对每一个出链指向的网页i,有M[i][j]=1/k,而其他网页的M[i][j]=0;上面示例图对应的转移矩阵如下:

初试时,假设上网者在每一个网页的概率都是相等的,即1/n,于是初试的概率分布就是一个所有值都为1/n的n维列向量V0,用V0去右乘转移矩阵M,就得到了第一步之后上网者的概率分布向量MV0,(nXn)*(nX1)依然得到一个nX1的矩阵。下面是V1的计算过程:

注意矩阵M中M[i][j]不为0表示用一个链接从j指向i,M的第一行乘以V0,表示累加所有网页到网页A的概率即得到9/24。得到了V1后,再用V1去右乘M得到V2,一直下去,最终V会收敛,即Vn=MV(n-1),上面的图示例,不断的迭代,最终V=[3/9,2/9,2/9,2/9]':

三.原理介绍
有关pagerank的原理和各种情况网络上的资料比较多,我们省略掉中间的很多高深的数学证明,给出比较简单的原理介绍:
(1).PR的核心思想有2点:
- 如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PR值会相对较高
- 如果一个PR值很高的网页链接到一个其他的网页,那么被链接到的网页的PR值会相应地因此而提高
(2).WIKI上有一个PR的简便算法,它不考虑转移概率,而是采用的是迭代的方式,每次都更新所有网页的PR值,更新的方式就是将每个网页的PR值平摊分给它指向的所有网页,每个网页累计所有指向它的网页平摊给它的值作为它该回合的PR值,直到全部网页的PR值收敛了或者满足一定的阈值条件就停止。
(3).ABCD的初始PR值都是1,现在A投票给BCD,所以用所以给BCD的PR值都加上A的PR/3,同理,B投票给AD,所以AD的PR值都要加上B的PB/2,CD同理,这样一轮完成后,ABCD都有了新的PR值,再重复上面的步骤,直到相邻两次的误差达到精度要求为止。
(4).上面的算法有个问题,如果每次都把原始的PR值和获得的投票的PR值直接相加作为新的PR值,结果容易受到初始误差的影响,所以有一种方法是选择将原有的PR值乘以一个系数加上获得投票的PR和乘以另一个系数,这样得到的结果更合理,经过很多互联网公司的实验结果来看,一般会使用0.85和0.15两个系数。
四.PageRank简单计算
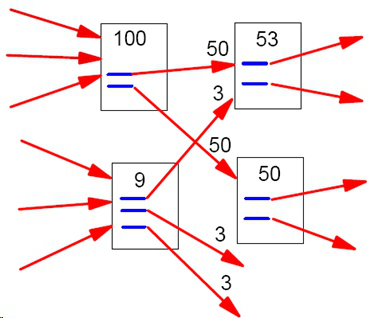
假设一个由只有4个页面组成的集合:A,B,C和D。如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。

继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。

换句话说,根据链出总数平分一个页面的PR值。
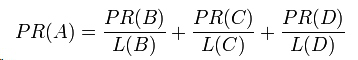
以下所示的例子可以更容易理解PageRank的具体计算过程:
五、终止点问题
上述上网者的行为是一个马尔科夫过程的实例,要满足收敛性,需要具备一个条件:
图是强连通的,即从任意网页可以到达其他任意网页:
互联网上的网页不满足强连通的特性,因为有一些网页不指向任何网页,如果按照上面的计算,上网者到达这样的网页后便走投无路、四顾茫然,导致前面累计得到的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为0。假设我们把上面图中C到A的链接丢掉,C变成了一个终止点,得到下面这个图:
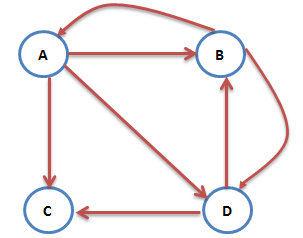
对应的转移矩阵为:

连续迭代下去,最终所有元素都为0:
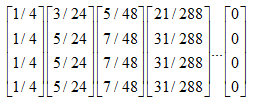
六、陷阱问题
另外一个问题就是陷阱问题,即有些网页不存在指向其他网页的链接,但存在指向自己的链接。比如下面这个图:
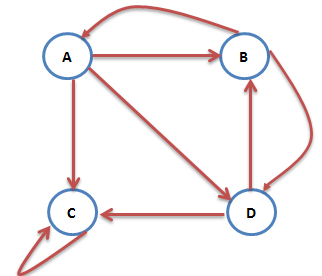
上网者跑到C网页后,就像跳进了陷阱,陷入了漩涡,再也不能从C中出来,将最终导致概率分布值全部转移到C上来,这使得其他网页的概率分布值为0,从而整个网页排名就失去了意义。如果按照上面图对应的转移矩阵为:

不断的迭代下去,就变成了这样:
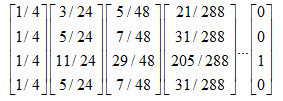
七、解决终止点问题和陷阱问题
上面过程,我们忽略了一个问题,那就是上网者是一个悠闲的上网者,而不是一个愚蠢的上网者,我们的上网者是聪明而悠闲,他悠闲,漫无目的,总是随机的选择网页,他聪明,在走到一个终结网页或者一个陷阱网页(比如两个示例中的C),不会傻傻的干着急,他会在浏览器的地址随机输入一个地址,当然这个地址可能又是原来的网页,但这里给了他一个逃离的机会,让他离开这万丈深渊。模拟聪明而又悠闲的上网者,对算法进行改进,每一步,上网者可能都不想看当前网页了,不看当前网页也就不会点击上面的连接,而上悄悄地在地址栏输入另外一个地址,而在地址栏输入而跳转到各个网页的概率是1/n。假设上网者每一步查看当前网页的概率为a,那么他从浏览器地址栏跳转的概率为(1-a),于是原来的迭代公式转化为:

现在我们来计算带陷阱的网页图的概率分布:

重复迭代下去,得到:

可以看到C虽然占了很大一部分pagerank值,但其他网页页获得的一些值,因此C的链接结构,它的权重确实应该会大些。
八、用Map-reduce计算Page Rank
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决。实际上,google发明Map-Reduce最初就是为了分布式计算大规模网页的pagerank,Map-Reduce的pagerank有很多实现方式,我这里计算一种简单的。
考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个网页及其链出的网页作为一行,这样第四节中的web图结构用如下方式表示:
1 A B C D2 B A D3 C C4 D B C
A有三条出链,分别指向B、C、D,实际上,我们爬取的网页结构数据就是这样的。
1、Map阶段
Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/3*1/4>,<C,1/3*1/4>,<D,1/3*1/4>;
2、Reduce阶段
Reduce操作收集网页id相同的值,累加并按权重计算,pj=a*(p1+p2+...Pm)+(1-a)*1/n,其中m是指向网页j的网页j数,n所有网页数。
思路就是这么简单,但是实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:

实验设备与软件环境
Windows 10
Vmware虚拟机
Centos7
实验过程与结果(可贴图)
1、安装好两台Centos机器


网络配置
查看client机的网络连接模式
a.右键选择Centos客户机。
b.点击"设置"
c.网络适配器.
查看DHCP的分配网段
a.vmware-->编辑-->虚拟网络编辑器
b.选中V8条目
c.下方显示的V8的详细信息。
d.点击DHCP的设置.
e.查看分配网段.

静态IP配置(每台机器都要执行)
1.切换root用户
$>su root
2.编辑vim /etc/sysconfig/network-scripts/ifcfg-eno16777736
a.备份文件
$>cd /etc/sysconfig/network-scripts
$>cp ifcfg-eno16777736 ifcfg-eno16777736.bak
b.进入/etc/sysconfig/network-scripts
$>cd /etc/sysconfig/network-scripts
c.编辑ifcfg-eno16777736文件
vim /etc/sysconfig/network-scripts/ifcfg-eno16777736
HWADDR=60:D8:19:D4:A5:E2
ESSID="X4140"
MODE=Managed
KEY_MGMT=WPA-PSK
TYPE=Wireless
BOOTPROTO=static #将这个改为具体模式
IPADDR=192.168.157.128 #对应host文件的具体IP(另一台配:192.168.157.129)
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.1.1 #默认网关
DNS1=192.168.1.1
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=X4140
UUID=4eee027c-d4ab-4f64-b2bf-1d8cdd697954
ONBOOT=yes
SECURITYMODE=open
MAC_ADDRESS_RANDOMIZATION=default
PEERDNS=yes
重启网络服务
$>su root
$>service network restart
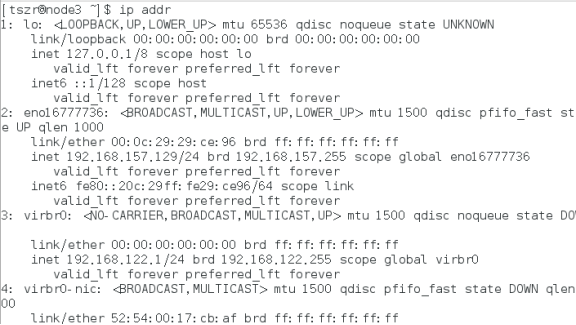
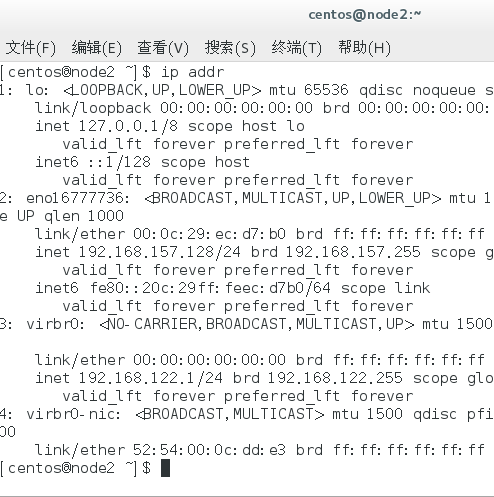
查看ip这是是否配置正确 ---------ip addr
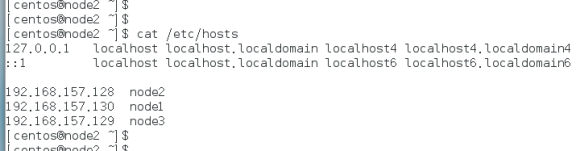
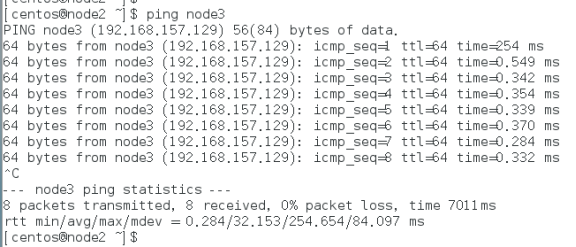
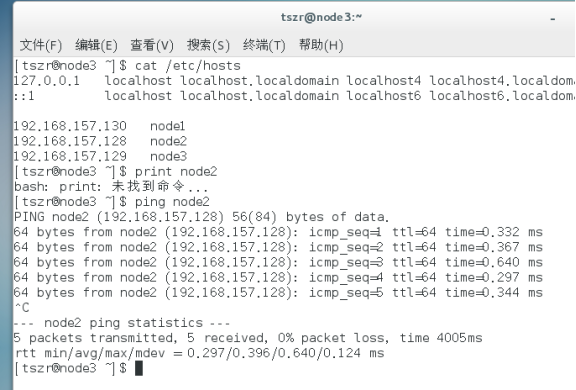
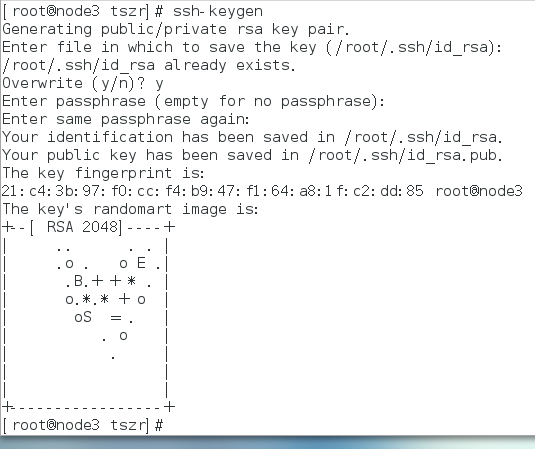
免密登录
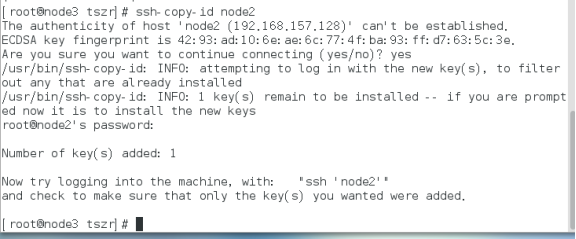
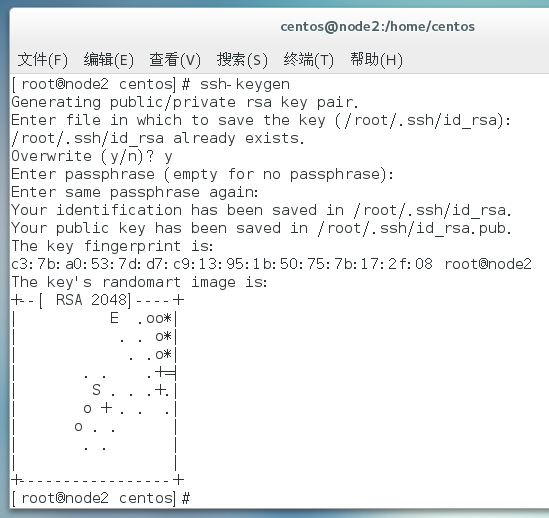
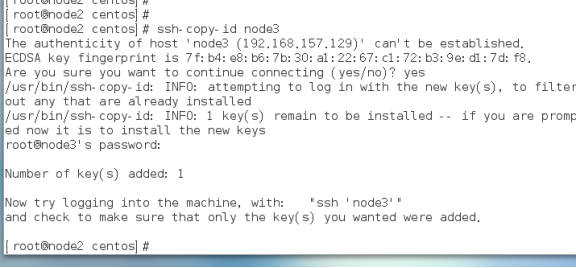

时间同步


安装(两台机器都要执行)
a)下载jdk-8u151-linux-x64.tar.gz
b)tar开
$>su centos ; cd
$>tar -xzvf jdk-8u151-linux-x64.tar.gz -C /usr/local/src
c)验证jdk是否成功
$>cd /usr/local/src/jdk1.8.0_151/bin
$>./java -version
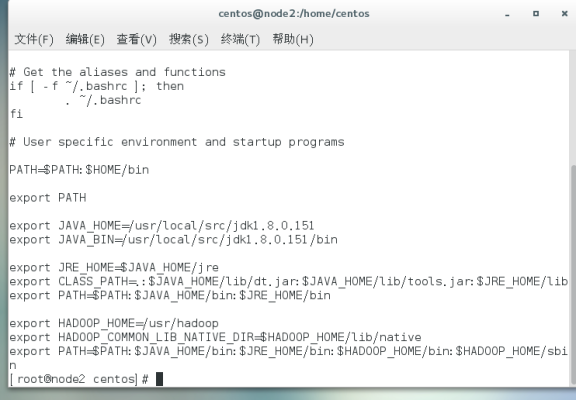
配置jdk环境变量
1.编辑/etc/profile
$>sudo vim /etc/profile
...
# JAVA
export JAVA_HOME=/usr/local/src/jdk1.8.0_151
export JRE_HOME=$JAVA_HOME/jre
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
exprot PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
2.使环境变量即刻生效
$>source /etc/profile
3. 替换默认的java
$> rm -rf /etc/alternatives/java
$> ln -s /usr/java/jdk1.8.0_151/bin/java /etc/alternatives/java
3.进入任意目录下,测试是否ok
$>cd ~
$>java -version
安装HADOOP软件
1.安装hadoop
a)下载hadoop-2.7.3.tar.gz
b)tar开
$>su centos ; cd ~
$>cp hadoop-2.7.3.tar.gz /usr/local/src
$>tar -xzvf hadoop-2.7.3.tar.gz -C /usr/local/src
c)无
d)验证hadoop安装是否成功
$>cd /usr/local/src/hadoop-2.7.3/bin
$>./hadoop version
2.配置hadoop环境变量
$>sudo vim /etc/profile
...
export JAVA_HOME=/usr/local/src/jdk1.8.0_151
exprot PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME= /usr/loca/src/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.生效
$>source /etc/profile
4.进入任意目录下,测试是否ok
$>cd ~
$>hadoop version
5.su 进入root用户
一般都在root用户下安装

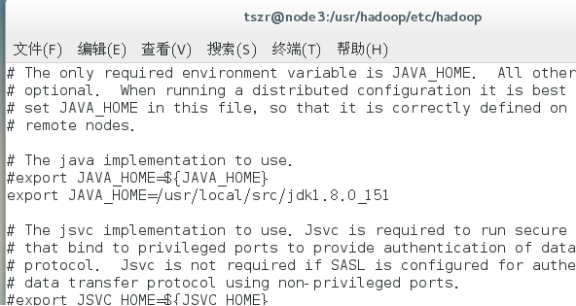
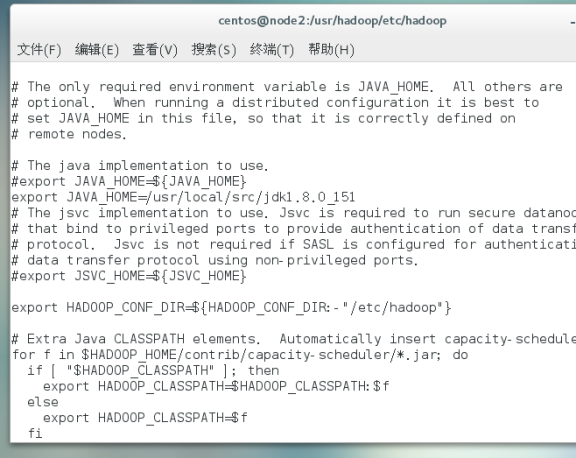
配置hadoop-env.sh
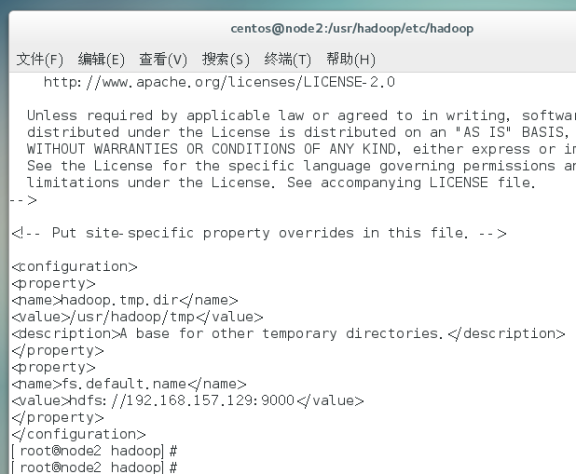
配置core-site.xml

配置hdfs-site.xml


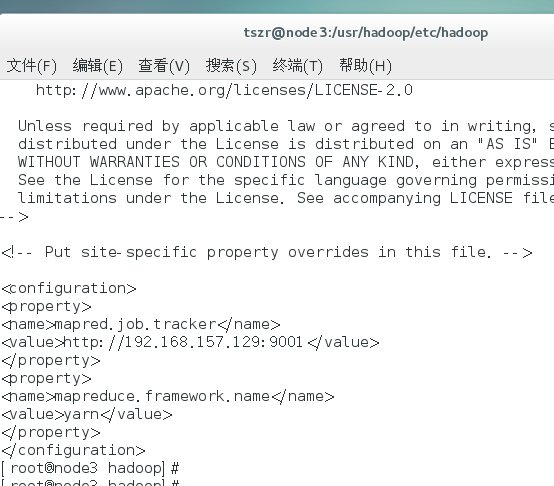
配置mapred-site.xml
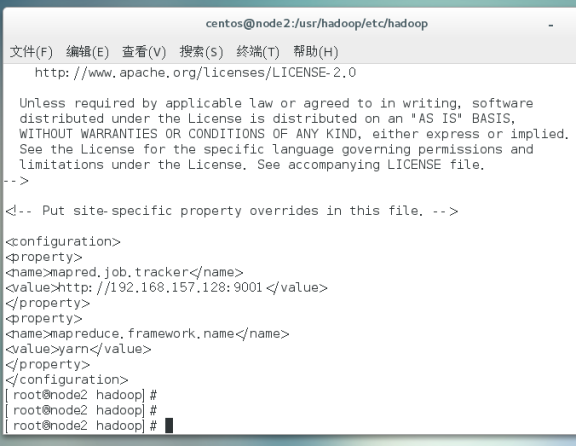
配置yarn-site.xml


添加masters
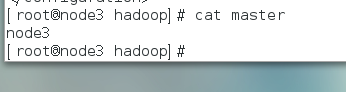

添加slaves
启动集群
启动集群之前,需要主节点中格式化hdfs(仅主节点执行)。


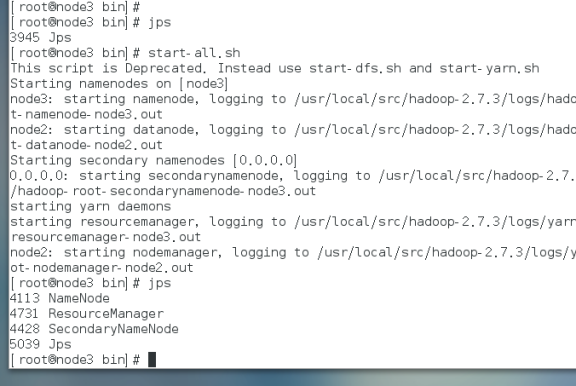
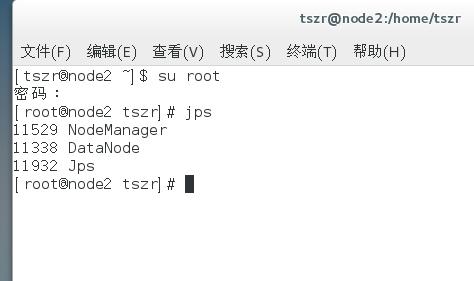
登录50070查看是否成功

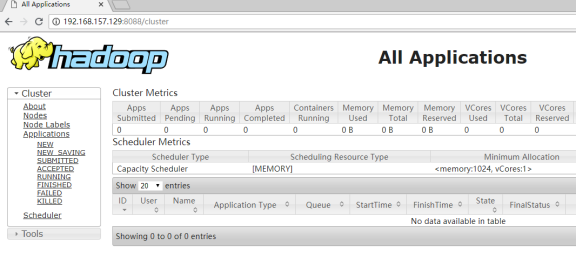
然后登录8088
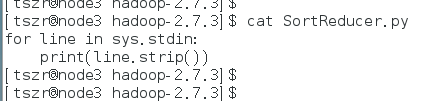
编写代码文件:

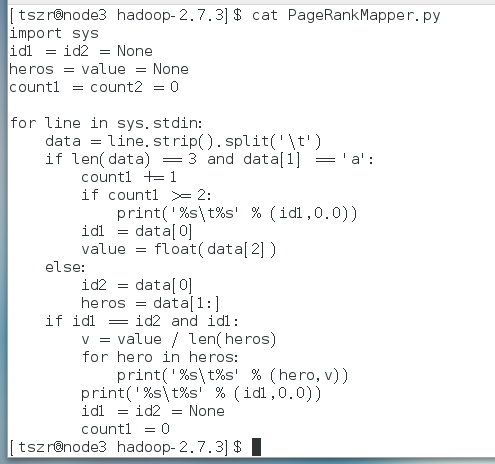

使用shell脚本和hadoop streaming调用上面的python代码

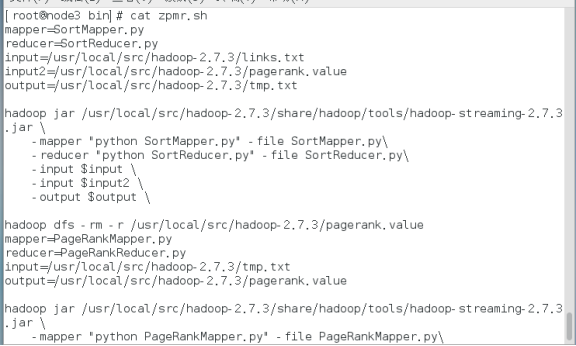


上传文件

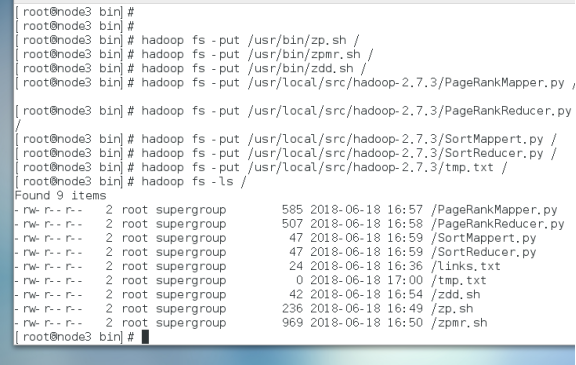
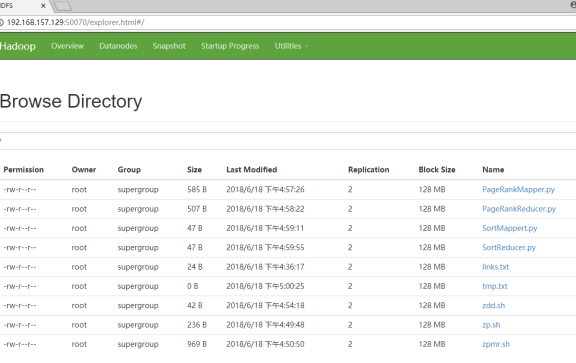
执行zpmr.sh


结果
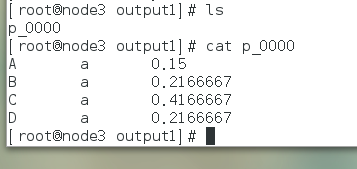
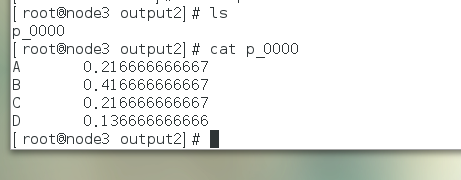
操作异常问题与解决方案
1、原本两台机器已经设置好ssh免密登录,重装其中一台之后,再次设置ssh免密登录时出错。
答:应该将其中好的那一台原有的配置清除掉:ssh keygen -R 新需要连接的ip
2、编写脚本文件里面的hadoop jar包命令出错。
答:使用hadoop jar的绝对路径,并且把需要执行的文件都上传到hdfs,那样就不会报错了。
实验总结
通过本次hadoop集群的搭建以及使用python来实现pagerange算法,我对Hadoop集群的搭建有了更深刻的理解和认识,具体主要是:完全分布式hdfs各个文件的配置,相关网络配置,ssh免密登录,添加映射等相关操作。对map和reduce这两个的基本工作流程及python代码也有了更加具体的认识和了解,具体内容包括有:把第一次map之后的结果的键值对作为reduce的输入,reduce工作完了之后,将结果返回给master节点,也可以直接写入本地磁盘等相关的知识内容。对pagerange这个算法的原理及其对应python代码的实现也有了更加深刻、清晰的认识,具体是:解析txt文件,格式化输出数据,构建pagerange矩阵并且进行相关的矩阵向量的求解等相关的知识内容。
对使用hadoop hdfs的相关命令操作也更加熟练了,例如:上传:hadoop fs -put 文件路径 / ,查看hadoop fs -ls / ,删除:hadoop fs -rm/-rmdir /文件名称等命令的使用。最后是编写和使用shell脚本来调用和执行相关的文件代码,使得我对这一块原本比较陌生的地方有了更加好的体悟,但一开始写shell脚本及里面所需要使用到的hadoop相关导入jar包操作等命令,可以说是困难重重的,但经过努力去理解和学习,最终还是把问题都解决了。
所以总的来说,这次的期末作业实验还是学到和巩固了这一学期所学的知识。也很感谢老师的指导和同学们的学习经验讨论和给予的帮助,谢谢...