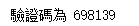用 Selenium 包实现网页自动化操作的案例中,发现很多网页都因
需输入图形验证码而导致实验无法进行 。 解决的办法就是对验证码进行识别 。 识
别的方法之 一 是通过图形处理包将验证码的大部分背景去除,再用 OCR COptical
Character Recognition ,光学字符识别)来识别出图片文字 。 不同的图形验证码需要
不同图形处理技术去除背景
简单的 OCR-丁esseract 包 Tesseract 是一个流行的 OCR 链接库,最初是由惠普公司(田)在 1985 年开始 研发,直到 2005 年 HP 将 Tesserac t 开源, 2006 年交给 Goog le 维护。
使用 Tesseract 识别图像
Tesseract 的使用方法非常简单,首先导入 Tesseract 包:
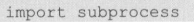
对图片进行识别的语法为:


用 Tesseract 识别文本|
识别 text I 扣g 图片后,将识别结果保存到 result. txt 文本文件中,再
读取文本文件的内容并显示到命令窗口 。
import subprocess ocr = subprocess.Popen("tesseract F:\pythonBase\pythonex\ch10\media\text1.jpg F:\pythonBase\pythonex\ch10\media\result") ocr.wait() text = open("F:\pythonBase\pythonex\ch10\media\result.txt").read().strip() print(text)

验证码识别的原理
许多网站是用很小的彩色杂点背景加上字符的图片作为验证码,现在我们以某
银行网站的验证码为例,来学习这类验证码的破解:
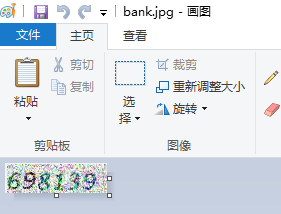
首先用 OpenCV 的 cvtColor 方法将图形转为灰度模式。 cvtColor 方法的语法为:




import cv2, subprocess img = cv2.imread("F:\pythonBase\pythonex\ch10\media\bank.jpg") #讀圖 cv2.namedWindow("Image") cv2.imshow("Image", img) #顯示圖形 cv2.waitKey (0) cv2.destroyWindow("Image")

cv2.namedWindow("Image") gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #轉為灰階 cv2.imshow("Image", gray) #顯示圖形 cv2.waitKey (0) cv2.destroyWindow("Image")

cv2.namedWindow("Image") _, inv = cv2.threshold(gray, 150, 255, cv2.THRESH_BINARY_INV) #轉為反相黑白 cv2.imshow("Image", inv) #顯示圖形 cv2.waitKey (0) cv2.destroyWindow("Image")

可以发现,黑白图形中有许多 白色杂点 。 我们可手动编写代码进行去除 :
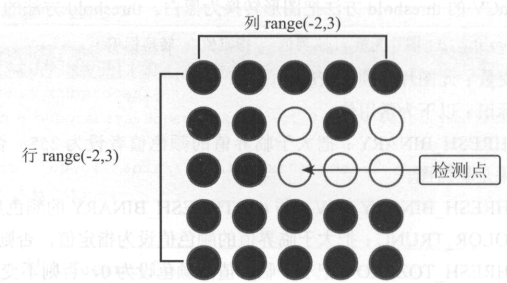
for i in range(len(inv)): #i為每一列 for j in range(len(inv[i])): #j為每一行 if(inv[i][j] == 255): #顏色為白色 count = 0 for k in range(-2, 3): for l in range(-2, 3): try: if inv[i + k][j + l] == 255: #若是白點就將count加1 count += 1 except IndexError: pass if count <= 6: #週圍少於等於6個白點 inv[i][j] = 0 #將白點去除 dilation = cv2.dilate(inv, (8,8), iterations=1) #圖形加粗 cv2.namedWindow("Image") cv2.imshow("Image", dilation) #顯示圖形 cv2.waitKey (0) cv2.destroyWindow("Image")

代码会逐行、逐列检查图片中每一个点 :以一个点为中 心 ,第 5 行和第 6 行代码用 range(-2 , 3 ) 逐一检查其上下左右各两排的点,共计 5 × 5=2 5 个点(包 含自身〉,如果是白色点就将计数器 count 加 l 。 第 12 行判断若这 2 5 个点中白点数 量小于或等于 6 个,就视此点为杂点 ,把这个点删除(设为黑点〉 。 例如下图检测点 周围只有 5 个 自点(含自身),执行的结果就会将其设置为黑点 。
图中的杂点大部分都己去除,但 Tesserac t OCR 识别此图片时仍无法得到正
确字符。所以,我们最后通过 Open CV 的 di l ate 方法把字体加粗, di l ate 方法会把图
片中的自点膨胀,语法为:


可以看到白色笔画己变粗了。再用 Tesseract OCR 识别此图片,就得到了正确验
证码。
验证码破解
程序概述
程序执行后会显示验证码图形,按任意键后会在命令窗口显示识别结果。
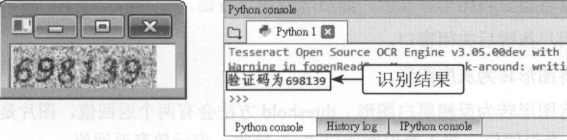
cv2.imwrite("F:\pythonBase\pythonex\ch10\media\bank_t.jpg", dilation) #存檔 child = subprocess.Popen('tesseract F:\pythonBase\pythonex\ch10\media\bank_t.jpg E:\result') #OCR辨識 child.wait() text = open('E:\result.txt').read().strip() print("驗證碼為 " + text)