楔子
我们前面介绍过 HyperLogLog 可以用来做基数统计,但它没提供判断一个值是否存在的查询方法,那我们如何才能在海量数据之中判断一个值是否存在呢?
因为是海量数据,所以我们就无法将每个键值都存起来,然后再从结果中检索数据了,比如数据库中的 select count(1) from tablename where id='XXX',或者是使用 Redis 普通的查询方法 get XXX 等方式,这样是不合适的。我们只能依靠专门处理此问题的特殊方法来实现数据的查找。
而完成一个功能的就是我们今天的主角:布隆过滤器。
布隆过滤器
什么是布隆过滤器
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。也就是说布隆过滤器的优点就是计算和查询速度很快,但是缺点也很明显,就是存在一定的误差。
但是在 Redis 中不能直接使用布隆过滤器,但我们可以通过 Redis 4.0 版本之后提供的 modules(扩展模块)的方式引入,本文提供两种方式的开启方式。
方式一:编译方式
1. 下载并安装布隆过滤器
git clone https://github.com/RedisLabsModules/redisbloom.git
cd redisbloom
make # 编译redisbloom
编译正常执行完,会在根目录生成一个 redisbloom.so 文件。
2. 启动 Redis 服务器
./redis-server redis.conf --loadmodule redisbloom.so文件路径
其中 --loadmodule 为加载扩展模块的意思,后面跟的是 redisbloom.so 文件的路径。
方式二:docker方式
也是本文所使用的方式,直接拉取镜像然后运行即可。
docker pull redislabs/rebloom # 拉取镜像
docker run -p 6379:6379 redislabs/rebloom # 运行容器
布隆过滤器的使用
关于布隆过滤器的原理我们后面会说,目前的话先来看看使用。布隆过滤器的命令不是很多,主要包含以下几个:
bf.add:添加元素bf.exists:判断某个元素是否存在bf.madd:添加多个元素bf.mexists:判断多个元素是否存在bf.reserve:设置布隆过滤器的准确率
举栗说明:
添加元素:
127.0.0.1:6379> bf.add user mea
(integer) 1
127.0.0.1:6379> bf.add user kano
(integer) 1
127.0.0.1:6379> bf.add user nana
(integer) 1
127.0.0.1:6379>
判断元素是否存在:
127.0.0.1:6379> bf.exists user mea
(integer) 1
127.0.0.1:6379> bf.exists user mea1
(integer) 0
127.0.0.1:6379>
添加多个元素:
127.0.0.1:6379> bf.madd vtb mea kano nana
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379>
判断多个元素是否存在:
127.0.0.1:6379> bf.mexists user mea kano kano1
1) (integer) 1
2) (integer) 1
3) (integer) 0
127.0.0.1:6379>
可以看出以上结果没有任何误差,然后还有一个布隆过滤器的准确率,不过在介绍它之前,我们先使用Python操作一下Redis的布隆过滤器。
我们之前使用Python操作Redis使用第三方模块也叫redis,但是对于布隆过滤器来说,这个模块是不支持的,我们需要使用另一个第三方模块:redisbloom,直接pip install redisbloom安装即可。
其实redisbloom底层还是使用了我们之前的redis模块。
from redisbloom.client import Client
# 我们之前创建连接使用的是redis.Redis,而这个Client继承自Redis
# 所以我们之前的一些操作,这里都可以用
client = Client(host="47.94.174.89", decode_responses="utf-8")
# 添加单个元素
client.bfAdd("VTuber", "mea")
# 添加多个元素
client.bfMAdd("VTuber", "kano", "nana")
# 判断单个元素是否存在
print(client.bfExists("VTuber", "kano")) # 1
# 判断多个元素是否存在
print(client.bfMExists("VTuber", "kano", "nana", "mea", "xxx")) # [1, 1, 1, 0]
设置布隆过滤器的准确率:
127.0.0.1:6379> bf.reserve user 0.01 200
(error) ERR item exists # 对于一个已经存在的key,不可以使用bf.reserve
127.0.0.1:6379> bf.reserve user1 0.01 200
OK
127.0.0.1:6379>
key后面的两个值分别表示:error_rate、initial_size
error_rate:允许布隆过滤器的错误率,这个值越低过滤器占用空间也就越大,以为此值决定了位数组的大小,位数组是用来存储结果的,它的空间占用的越大 (存储的信息越多),错误率就越低,它的默认值是 0.01;initial_size:布隆过滤器存储的元素大小,实际存储的值大于此值,准确率就会降低,它的默认值是 100。
布隆过滤器常见使用场景有:
垃圾邮件过滤;爬虫里的 URL 去重;判断一个值在亿级数据中是否存在。
布隆过滤器在数据库领域的使用也比较广泛,例如:HBase、Cassandra、LevelDB、RocksDB 内部都有使用布隆过滤器。
对于布隆过滤器而言,数据量增大到一定程度之后误差也会随之增大。
原理解析
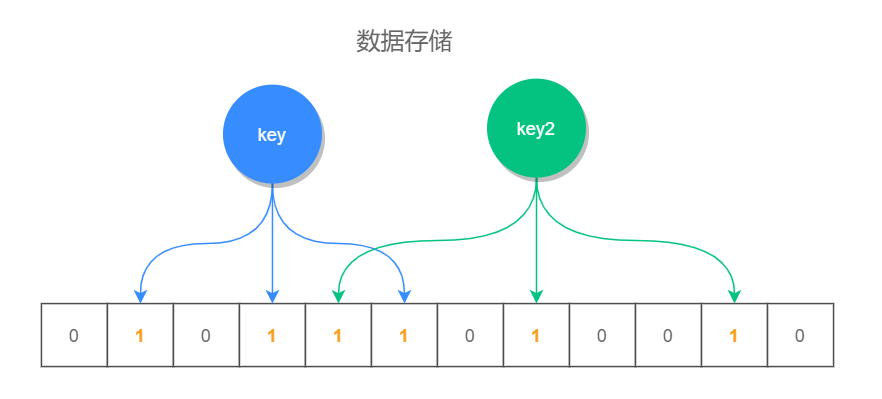
Redis 布隆过滤器的实现,依靠的是它数据结构中的一个位数组,每次存储键值的时候,不是直接把数据存储在数据结构中,因为这样太占空间了,它是利用几个不同的无偏哈希函数,把此元素的 hash 值均匀的存储在位数组中,也就是说,每次添加时会通过几个无偏哈希函数算出它的一些位置,把这些位置设置成 1 就完成了添加操作。
当进行元素判断时,查询此元素的几个哈希位置上的值是否为 1,如果全部为 1,则表示此值存在,如果有一个值为 0,则表示不存在。因为此位置是通过 hash 计算得来的,所以即使这个位置是 1,并不能确定是一定是该元素把它标识为 1 的,因此布隆过滤器查询此值存在时,此值不一定存在,但查询此值不存在时,此值一定不存在。
并且当位数组存储值比较稀疏的时候,查询的准确率越高,而当位数组存储的值越来越多时,误差也会增大。
位数组和 key 之间的关系,如下图所示:
小结
通过本文我们知道可以使用 Redis 4.0 之后提供的 modules 方式来开启布隆过滤器,并学习了布隆过滤器的三个重要操作方法 bf.add 添加元素、bf.exists 查询元素是否存在,还有 bf.reserve 设置布隆过滤器的准确率,其中 bf.reserve 有 2 个重要的参数:错误率和数组大小,错误率设置的越低,数组设置的越大,需要存储的空间就越大,相对来说查询的错误率也越低,需要如何设置需要使用者根据实际情况进行调整。我们也知道布隆过滤器的特点:当它查询有数据时,此数据不一定真的存在,当它查询没有此数据时,此数据一定不存在。