SQL逻辑查询处理阶段简介
(1) FROM
FROM处理阶段会确定查询的数据源表并处理表操作符。每个表操作符都会有一系列的子步骤。比如,Join包含的子步骤有:(1-J1) 笛卡儿积(Cross Join), (1-J2) 应用ON条件, (1-J3) 添加外部数据行(Add Outer Rows). FROM阶段生成虚表VT1.
(1-J1) Cross Join 这个阶段针对两个数据表执行cross join,生成VT1-J1.
(1-J2) ON Filter 这个阶段会基于ON子句中的条件来对VT1-J1中的记录进行过滤,只有条件返回TRUE的数据行会被插入到VT1-J2.
(1-J3) Add Outer Rows 如果指定了外连接(OUTER JOIN),保留表中没有匹配成功的行会加入到VT1-J2的数据行中,生成VT1-J3.
(2) WHERE
这个阶段会基于WHERE子句的条件对VT1表进行过滤,只有条件返回TRUE的数据行会被插入到VT2.
(3) GROUP BY
对VT2中的数据行进行分组,生成VT3. 这样对于每一个组将只有一条记录。
(4) HAVING
基于HAVING子句中的条件对VT3中的分组数据进行过滤,只有条件返回TRUE的分组数据行会被插入到VT4.
(5) SELECT
处理SELECT子句中的元素,生成VT5. 它包含以下几个子步骤:
(5-1) Evaluate Expressions 对SELECT列表进行求值,生成VT5-1.
(5-2) DISTINCT 去除VT5-1中的重复行,生成VT5-2.
(5-3) TOP 基于ORDER BY子句定义的逻辑顺序,过滤出顶部的相应行数(或百分比行数),生成VT5-3.
(6) ORDER BY
对VT5-3中的数据行进行排序,生成游标(cursor) VC6
基于Customers/Orders的查询示例
为了详细描述SQL查询的逻辑处理阶段,我将会使用下面这个查询示例来进行讲解。首先,请运行下面的SQL代码来创建dbo.Customers和dbo.Orders表,并填充示例数据,
 View Code
View Code

SET NOCOUNT ON; USE tempdb; IF OBJECT_ID('dbo.Orders') IS NOT NULL DROP TABLE dbo.Orders; IF OBJECT_ID('dbo.Customers') IS NOT NULL DROP TABLE dbo.Customers; GO CREATE TABLE dbo.Customers ( customerid CHAR(5) NOT NULL PRIMARY KEY, city VARCHAR(10) NOT NULL ); CREATE TABLE dbo.Orders ( orderid INT NOT NULL PRIMARY KEY, customerid CHAR(5) NULL REFERENCES Customers(customerid) ); GO INSERT INTO dbo.Customers(customerid, city) VALUES('FISSA', 'Madrid'); INSERT INTO dbo.Customers(customerid, city) VALUES('FRNDO', 'Madrid'); INSERT INTO dbo.Customers(customerid, city) VALUES('KRLOS', 'Madrid'); INSERT INTO dbo.Customers(customerid, city) VALUES('MRPHS', 'Zion'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(1, 'FRNDO'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(2, 'FRNDO'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(3, 'KRLOS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(4, 'KRLOS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(5, 'KRLOS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(6, 'MRPHS'); INSERT INTO dbo.Orders(orderid, customerid) VALUES(7, NULL);
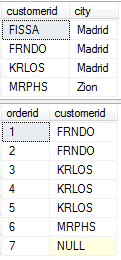
--运行查询 SELECT * FROM dbo.Customers; SELECT * FROM dbo.Orders; --将会得到以下结果
下面我将使用以下查询来讲述SQL查询的逻辑处理步骤,该查询返回来自Madrid,并且订单数少于3的customer,查询同时返回了订单的数量:

SELECT C.customerid, COUNT(O.orderid) AS numorders FROM dbo.Customers AS C LEFT OUTER JOIN dbo.Orders AS O ON C.customerid = O.customerid WHERE C.city = 'Madrid' GROUP BY C.customerid HAVING COUNT(O.orderid) < 3 ORDER BY numorders; --该查询返回如下结果

请对照表1-1以及所述的查询步骤来思考和阅读该查询。如果你还是第一次以这种方式来考虑一个SQL查询的话,那么可能会感到迷惑。希望接下来的分析能帮助你理解该查询的细节和本质。
SQL逻辑查询处理阶段之详细解析
本节通过上述示例详细介绍逻辑查询的各个处理阶段,使我们能够真正的了解SQL查询的具体运行过程。
1. FROM子句
FROM处理阶段会确定查询的数据源表并处理表操作符。每个表操作符都有一个或两个输入表,并产生一个输出表。每个表操作符都会有一系列的子步骤。比如,Join包含的子步骤有:(1-J1) Cross Join, (1-J2) ON Filter, (1-J3) Add Outer Rows. FROM阶段生成虚表VT1.
(1- J1) 笛卡尔积(Cross Join)
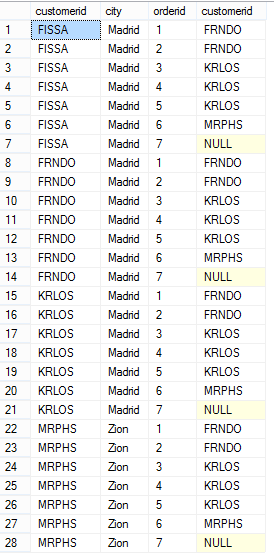
这是join表操作符三个步骤的第一步,它会对参与join的两个表执行无任何约束的交叉连接。如果左表有n行数据,右表有m行数据的话,那么这一步生成的虚表VT1-J1会包含n*m行数据。并且该表中的列会使用表名或表的别名来限定,这样在接下来的步骤中,必须使用表限定符来对不明确的列进行引用,如上面查询中的c.customerid。
针对上面的示例应用这一步骤:
FROM dbo.Customers AS C ... JOIN dbo.Orders AS O
我们会得到一个包含28(4*7)行数据的虚表VT1-J1:
1-J2: 应用ON条件过滤
我们可以在一个查询中应用三种过滤条件: ON, Where和HAVING。ON即是第一种我们可以使用的过滤条件。该条件应用于上一步骤虚表VT1-J1中的所有行上,只用那些满足ON条件的数据行会被返回,这一步骤生成的虚表我们把它称为VT1-J2。
三值逻辑(Three-Valued Logic)
在讲述ON条件之前,我们有必要先来了解一个与之相关的重要的SQL概念:三值逻辑。在SQL中,一个逻辑表达式可能的取值有TRUE,FALSE或UNKNOWN,这就是SQL中特有的三值逻辑性质。在大多数语言中,逻辑表达式可以是TRUE或FALSE。SQL中的UNKNOWN逻辑值通常对应于含有NULL值的表达式。比如,下面三个表达式的逻辑值都是UNKNOWN:NULL > 42; NULL = NULL; X + NULL > Y。NULL表示一个未知的值,当把一个未知值和别的值(即使是另一个NULL)进行比较时,其结果总是UNKNOWN。
需要注意的是,SQL语言中不同元素对于UNKNOWN和NULL的处理并不一致,比如,所有的查询条件(ON,WHERE和HAVING)把UNKNOWN作为FALSE对待,所以那些条件值为UNKNOWN的行被排除在结果集之外。另一方面,CHECK约束则把UNKNOWN作为TRUE看待。假设我们有一个CHECK约束要求salary列的值必须大于0,那么一个salary为NULL的行是可以被插入到表中的,因为NULL > 0为UNKNOWN,而CHECK约束把它当成TRUE看待。
两个NULL值得比较结果为UNKNOWN,在查询条件中,如前所述,它被处理为FALSE,就好像一个NULL不同于另外一个NULL。但是,对于一个UNIQUE约束、集合操作符(如UNION,EXCEPT)和排序分组操作来讲,NULL值被认为是相等的。
对示例查询应用这一步骤:
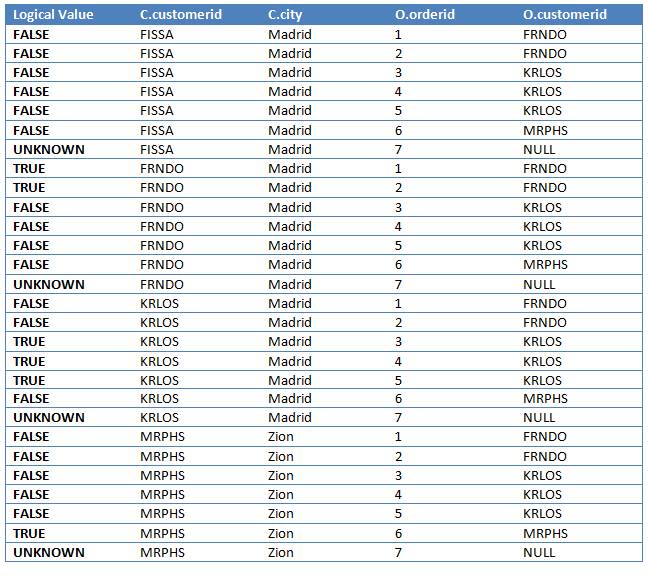
ON C.customerid = O.customerid
我们会通过VT1-J1表中得到如下的数据表,新增的列包含了ON条件的逻辑值,如下:
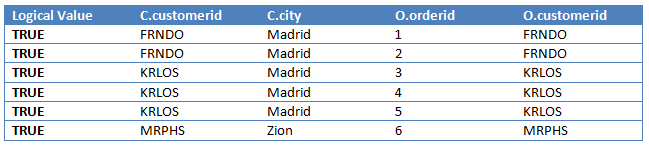
只有那些ON条件逻辑之为TRUE的行会被插入到VT1-J2表中,结果如下:
1-J3:添加外部数据行(Outer Rows)
这一步骤仅针对外连接(outer join)。对于一个外连接,我们可以使用LEFT, RIGHT或FULL来把一个或全部两个表作为保留表。在某个表被作为保留表后,它的所有数据行都会被返回,即使是被ON条件过滤掉了。这样,本步骤会返回VT1-J2中的数据行,外加VT1-J2中不存在的保留表中的数据行,我们把这些增加的数据行称为外部数据行。同时,外部数据行中非保留表的列值会赋以NULL。
在我们的示例中,保留表是Customers:
Customers AS C LEFT OUTER JOIN Orders AS O
因为只有customer FISSA没有任何匹配的orders,从而被ON条件过滤掉了,没有出现在VT1-J2表中。所以,FISSA行被添加到VT1-J2中,而Orders的所有列属性被赋予NULL。结果虚表VT1-J3如下:

如果FROM子句有多个表操作符,那么他们会从左到右依次处理,每个表操作符的结果会作为下一个表操作符的第一个输入表。最终的虚表VT1会作为下一步骤的输入。
2. WHERE子句
WHERE过滤条件会应用于VT1(前一步生成的虚表)的所有数据行。只有WHERE条件返回TRUE的数据行会被插入到VT2.
值得注意的是,在当前步骤时,因为数据还没有被分组(group),所以我们不能再此时使用聚合函数,比如:WHERE orderdate = MAX(orderdate)。同理,我们此时也不能引用在SELECT子句中创建的列别名,比如:SELECT YEAR(orderdate) AS orderyear . . . WHERE orderyear > 2008。
对我们的示例应用WHERE条件WHERE C.city = 'Madrid',结果customer MRPHS的数据行被过滤掉了,最终的虚表VT2如下:

对于包含OUTER JOIN子句的查询来说,一个有意思又容易迷惑的问题是:我们应该把逻辑表达式置于ON条件还是WHERE条件?他们的主要区别在于ON条件的执行在添加外部数据行(1-J3)之前,而WHILE则在之后。对于一个保留表来说,被ON条件过滤的数据行还会在步骤1-J3中添加回来,而被WHERE条件过滤的数据行则是最终的过滤掉了。记住这一点应该会让你知道如何选择。
对于我们的示例程序,为了返回没有任何order的customer,我们必须在ON条件处指定两者的关系(ON C.customerid = O.customerid)。这样他们被ON过滤掉但又被之后的添加外部数据行(1-J3)步骤添加进来了。但是,因为我们只希望查询来自Madrid的customers,所以必须在WHERE条件中指定此条件(WHERE C.city = ‘Madrid’)。
当然,ON和WHERE条件的逻辑处理的区别只存在于OUTER JOIN查询中,对INNER JOIN来讲,把条件放在何处都不会影响查询的结果。因为在1-J3步骤省略之后,ON和WHERE条件连着执行的,他们之间没有任何中间步骤。
3. GROUP BY子句
GROUP BY阶段会对上一步骤返回的虚表VT2中的数据行进行分组,生成VT3。根据指定的GROUP标识,所有的数据行都被关联到唯一的一个分组。
对示例程序应用分组:GROUP BY C.customerid,我们得到的VT3包含了VT2中的原始数据以及GROUP标识,如下所示:
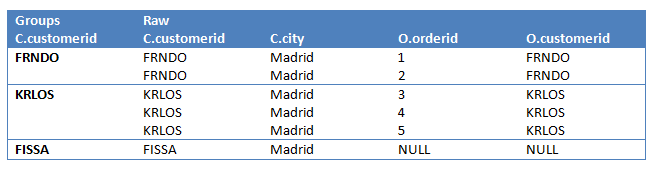
最终,对于一个包含GROUP BY子句的查询来说,每个分组只能产生一行数据,除非该分组被过滤掉了。所以,所有GROUP BY的后续步骤(HAVING,SELECT等)只能指定标量表达式。例如,我们可以使用GROUP BY列表中的列(C.customerid),或使用聚合函数(COUNT(O.orderid))。
4. HAVING子句
在这个阶段,会基于HAVING子句中的条件对VT3中的分组数据进行过滤,只有条件返回TRUE的分组数据行会被插入到VT4.
对示例查询应用该步骤:HAVING COUNT(O.orderid) < 3,KRLOS分组被过滤掉了,最终的VT4如下:

值得注意的是,我们在此使用COUNT(O.orderid)而不是COUNT(*)。因为我们使用的是OUTER JOIN,所以对于没有order的customer来说,添加的外部行中相应的order表列的值为NULL。如果使用COUNT(*),会这些外部行也误算为1,而不是期望中的0,而COUNT(<expression>)会忽略NULL值。
5. SELECT子句
尽管SELECT写在一个查询的最前面,但实际上直到第五步它才得以执行。SELECT阶段会构建最终返回给调用者的表,它有如下几个步骤: (5-1) Evaluate Expressions 对SELECT列表进行求值, (5-2) DISTINCT 去除重复行, (5-3) 应用TOP选项。
5-1 Evaluate Expressions(表达式求值)
针对上一步骤返回的虚表,SELECT列表可以返回其中的基础列或基于基础列的表达式。需要记住的是,对一个聚合查询来讲,我们只能返回GROUP BY列表中的列,或对原始数据使用聚合函数。对于非基础列的表达式,我们还必须为他指定一个别名,比如:YEAR(orderdate) AS orderyear。
SQL的同一时间操作特性
注意:SELECT列表中创建的别名不能在之前的步骤中使用,如WHERE阶段。实际上,表达式别名甚至不能在同一SELECT列表中被另一表达式引用。在这一限制的背后,是SQL语言的另一个独特的性质:很多操作是在同一时间被执行的。比如,在下面的SELECT列表中,哪一个表达式先执行不应对结果产生影响:SELECT c1 + 1 AS e1, c2 + 1 AS e2。因此下面的查询是不被允许的:SELECT c1 + 1 AS e1, e1 + 1 AS e2。我们可以在SELECT的后续步骤(如ORDER BY)中使用SELECT列表中的表达式别名,如:SELECT YEAR(orderdate) AS orderyear . . . ORDER BY orderyear。
需要特别注意理解“同一时间操作”的概念。在多数编程环境中,我们可以使用临时变量来交换两个值。但是,在SQL中,我们可以使用如下的查询来交换表中两列的值:
UPDATE dbo.T1 SET c1 = c2, c2 = c1;
逻辑上,所有的操作在同一时间完成,就好像在整个语句完成之前表都未被修改。同理,下面的查询会在所有行的c1值上加上一个c1的一个最大值。
UPDATE dbo.T1 SET c1 = c1 + (SELECT MAX(c1) FROM dbo.T1);
我们不用担心在查询执行的过程中,c1的最大值会被改变。
对示例查询应用当前步骤:SELECT C.customerid, COUNT(O.orderid) AS numorders
我们得到如下的虚表VT5-1,因为示例查询中没有DISTINCT和TOP,所以VT5-1也是SELECT阶段最终返回的虚表VT5.

5-2 应用DISTINCT子句
如果在查询中指定了DISTINCT子句,则会在上一步骤返回的虚表中消除重复行,并生成虚表VT5-2。
5-3 应用TOP选项
TOP选项是T-SQL特有的一个功能,以让我们可以指定返回的记录行数或百分比数,而返回的记录则基于查询的ORDER BY子句。尽管根据ANSI SQL标准,ORDER BY用于数据呈现的目的。但如果指定了TOP选项,那么ORDER BY同时也被用于确定TOP返回哪些数据。
因为此步骤依赖于ORDER BY来确定前面的数据行,如果ORDER BY列表可以唯一确定数据行的排序位置,那么其结果就具有确定性(结果集的行数和顺序是唯一确定的)。如果ORDER BY列表不能唯一确定数据行的排序位置,我们可以通过指定WITH TIES来使结果集具有确定性。这时,SQL Server会返回所有与最后一行数据具有相同排序值的数据行。
但是,如果没有ORDER BY子句,或者ORDER BY列表不能唯一确定数据行排序位置的同时又没有WITH TIES选项,那么TOP查询就具有不确定性。这时返回的数据行就是SQL Serve恰巧先访问到的数据行,所以就存在多个不同但又正确的结果集。
这样,如果我们希望保证结果的确定性,那么就必须给TOP查询一个唯一的ORDER BY列表或WITH TIES选项。
6 ORDER BY呈现阶段
在这个阶段,前一步骤返回的数据行会根据ORDER BY子句进行排序,并返回游标(cursor)VC6。
如果查询指定了DISTINCT,那么ORDER BY子句只能访问前一步骤返回的虚表VT5。如果没有DISTINCT,那么ORDER BY子句将能同时访问SELECT阶段的输入和输出表。即我们可以在ORDER BY中使用任何可以在SELECT子句中使用的表达式,或者说,我们可以按某一个表达式进行排序,而不返回它。
表和游标(table and cursor)
这一阶段在概念上不同于所有其他阶段,因为它返回的是一个游标(cursor),而不是一个表(table)。SQL基于集合(set),一个集合中的数据是没有前后顺序的,它只是其元素的一个逻辑容器。一个带有ORDER BY呈现子句的查询返回的则是一个所含数据行按某种特定顺序进行组织的对象,ANSI把这种对象称为游标(cursor)。
通常我们在描述一个表的时候,会认为表中的数据行具有某种顺序。然而实际上,一个表代表了一个集合(set),即没有任何顺序,下图以一种正确的方式描绘了Customers和Orders表的内容,其中不包含任何顺序。记住,深刻理解表和游标的区别对我们理解SQL非常重要。
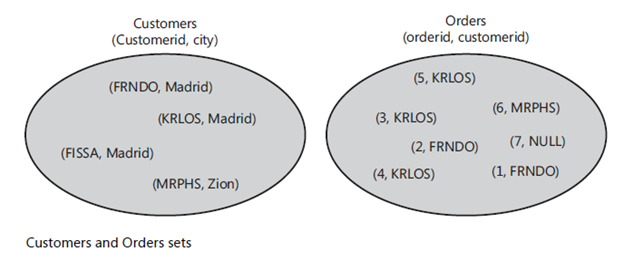
因为这一步骤返回一个游标,而不是一个表,因此带有ORDER BY呈现子句的查询不可以用来定义一个表表达式,包括View(视图),内联表值函数,派生表,CTE(公用表表达式)。相反,此游标只能返回给客户端应用程序来使用。比如,下面的派生表查询就是无效的:
SELECT * FROM (SELECT orderid, customerid FROM dbo.Orders ORDER BY orderid DESC) AS D;
同样的,下面的View视图也是无效的:
CREATE VIEW dbo.VSortedOrders AS SELECT orderid, customerid FROM dbo.Orders ORDER BY orderid DESC; GO
在SQL中,表表达式中的ORDER BY子句是不允许的。在T-SQL中,该规则有一个例外:当同时指定了TOP选项时。这一例外带来了很多迷惑。TOP选项从逻辑处理的顺序来看,它是SELECT阶段的一个子步骤,在呈现ORDER BY之前,其目的则是按照某种顺序返回指定的数据行数。然而,TOP选项并没有自己的ORDER BY子句,而是共用了用于呈现目的的ORDER BY子句。这样一来,当我们试图找出一个TOP查询的结果类型(表还是游标)时就不是那么清晰了。这时我们需要记住,对于一个最外层的TOP查询,ORDER BY子句有两个作用,定义TOP选项的逻辑顺序(步骤5-3),以及结果游标的呈现顺序(步骤6)。考虑下面的查询:
SELECT TOP (3) orderid, customerid FROM dbo.Orders ORDER BY orderid DESC;
我们可以确保orderid最大的3条记录被返回,并且按orderid的倒序输出。
但是,如果一个带有ORDER BY子句的TOP查询被用于定义一个表表达式,那么它代表了一个没有顺序的表。所以在这种情况下,ORDER BY子句只应用于TOP选项,而没有呈现顺序。比如,下面的查询并不保证呈现的顺序:
SELECT * FROM (SELECT TOP (3) orderid, customerid FROM dbo.Orders ORDER BY orderid DESC) AS D;
当然,在按索引顺序存取一个表,或通过排序获取指定行数的表时,SQL没有理由去改变数据行的输出顺序。但我们需要明白的是在这样情况下,SQL并不保证呈现顺序。
如果我们没有明白这一点,或者是表和游标的区别,就有可能误用TOP选项。比如,试图创建一个排序的视图(sorted view):
CREATE VIEW dbo.VSortedOrders AS SELECT TOP (100) PERCENT orderid, customerid FROM dbo.Orders ORDER BY orderid DESC; GO
再次强调,View用来表示一个表(table),而表不包含任何顺序。尽管SQL允许在一个视图中使用ORDER BY子句,只要同时指定了TOP选项。但是请记住,对一个表表达式来讲,ORDER BY仅应用与TOP选项,用来选择数据,而不会保证呈现顺序。这样,如果我们运行下面的查询就能发现,输出的记录并没有按照视图中ORDER BY的顺序来排序。
所以,除非确实需要对行进行排序,或者使用TOP选项来过滤数据,尽量不要使用ORDER BY子句。另外,排序需要开销,SQL Server需要扫描排序索引或应用sort操作符。
ORDER BY子句认为所有的NULL值是相等的,这样,在顺序上他们会排在一起。至于是排在已知值得前面还是后面则取决于具体实现,对T-SQL来讲,NULL值小于已知值。
对我们的示例程序应用此步骤:ORDER BY numorders,我们得到游标VC6,如下所示:

逻辑查询处理流程图
本篇最后,给出逻辑查询处理的完整流程图,以供参考:

从SQL SERVER 2008开始,SQL查询中支持四种表操作符:JOIN,APPLY,PIVOT和UNPIVOT。其中,APPLY,PIVOT和UNPIVOT并非ANSI标准操作符,而是T-SQL中特有的扩展。
下面列出了这四个表操作符的使用格式:
(J) <left_table_expression> {CROSS | INNER | OUTER} JOIN <right_table_expression> ON <on_predicate> (A) <left_table_expression> {CROSS | OUTER} APPLY <right_table_expression> (P) <left_table_expression> PIVOT (<aggregate_func(<aggregation_element>)> FOR <spreading_element> IN(<target_col_list>)) AS <result_table_alias> (U) <left_table_expression> UNPIVOT (<target_values_col> FOR <target_names_col> IN(<source_col_list>)) AS <result_table_alias>
JOIN
在前一篇中,我们已经对JOIN进行了比较详细的描述,详情请参阅:SQL逻辑查询解析
简单来说,它包含如下三个子步骤:(1-J1) 笛卡儿积(Cross Join), (1-J2) 应用ON条件, (1-J3) 添加外部数据行。
本篇会对另外三个表操作符进行讲解。
APPLY
按类型不同,APPLY操作符包含如下一个或全部二个步骤:
- A1:对左表的数据行应用右表表达式
- A2:添加外部数据行
APPLY操作符对左表的每一行应用右表表达式,并且,右表表达式可以引用左表的列。对于左表的每一行,右表表达式都会运行一遍,以获得一个与该行相匹配的集合并与之联结,结果加入返回数据集。CROSS APPLY和OUTER APPLY都包含步骤A1,但只有OUTER APPLY才包含步骤A2。对于左表的输入行,如果右表表达式返回空,那么CROSS APPLY不会返回外部行(左表当前行),而OUTER APPLY则会返回它,并且右表表达式的相关列为NULL。
比如,下面的查询为每个customer返回两个order ID最大的order:
SELECT C.customerid, C.city, A.orderid FROM dbo.Customers AS C CROSS APPLY (SELECT TOP (2) O.orderid, O.customerid FROM dbo.Orders AS O WHERE O.customerid = C.customerid ORDER BY orderid DESC) AS A;
查询返回如下数据:

可以看到FISSA并没有出现在结果集中,因为表表达式A对于该数据行返回空集,如果我们希望返回那些没有任何order的customer,则需要使用OUTER APPLY,如下所示:
SELECT C.customerid, C.city, A.orderid FROM dbo.Customers AS C OUTER APPLY (SELECT TOP (2) O.orderid, O.customerid FROM dbo.Orders AS O WHERE O.customerid = C.customerid ORDER BY orderid DESC) AS A;
查询返回如下数据:

PIVOT
PIVOT操作符允许我们对行和列中的数据进行旋转和透视,并执行聚合计算。
示例数据
请使用如下Script创建示例数据:
CREATE TABLE dbo.OrderValues ( orderid INT NOT NULL PRIMARY KEY, customerid INT NOT NULL, empid VARCHAR(20) NOT NULL, orderdate DATETIME NOT NULL, val NUMERIC(12,2) ); INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1000, 100, 'John', '2006/01/12', 100) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1001, 100, 'Dick', '2006/01/12', 100) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1002, 100, 'James', '2006/01/12', 100) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1003, 100, 'John', '2006/02/12', 200) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1004, 200, 'John', '2007/03/12', 300) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1005, 200, 'John', '2008/04/12', 400) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1006, 200, 'Dick', '2006/02/12', 500) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1007, 200, 'Dick', '2007/01/12', 600) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1008, 200, 'Dick', '2008/01/12', 700) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1009, 200, 'Dick', '2008/01/12', 800) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1010, 200, 'James', '2006/01/12', 900) INSERT INTO dbo.OrderValues(orderid, customerid, empid, orderdate, val) VALUES(1011, 200, 'James', '2007/01/12', 1000)
选择该表的所有数据,如下所示:
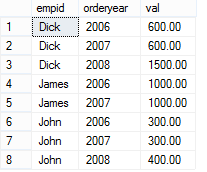
SELECT * FROM dbo.OrderValues
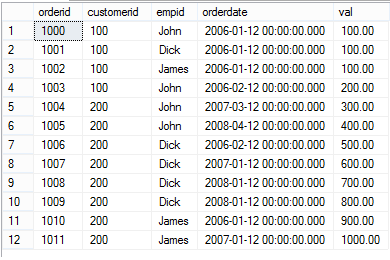
现在加入我们想知道每个employee在每一年完成的订单总价。下面的PIVOT查询能够让我们获得如下的结果:每一行对应一个employee,每一列对应一个年份,并且计算出相应的订单总价。
SELECT * FROM (SELECT empid, YEAR(orderdate) AS orderyear, val FROM dbo.OrderValues) AS OV PIVOT(SUM(val) FOR orderyear IN([2006],[2007],[2008])) AS P;
这个查询产生的结果如下所示:

不要被子查询产生的派生表OV迷惑了,我们关心的是,PIVOT操作符获得了一个表表达式OV作为它的左输入,该表的每一行代表了一个order,包含empid, orderyear和val(订单价格)。
PIVOT逻辑处理步骤解析
PIVOT操作符包含如下三个逻辑步骤:
- P1:分组
- P2: 扩展
- P3: 聚合
第一个步骤其实是一个隐藏的分组操作,它基于所有未出现在PIVOT子句中的列进行分组。上例中,在输入表OV中有三个列empid, orderyear, val,其中只有empid没有出现在PIVOT子句中,因此这里会按empid进行分组。
PIVOT的第二个步骤会对扩展列的值进行扩展,使其属于相应的目标列。逻辑上,它使用如下的CASE表达式为IN子句中指定的每个目标列进行扩展:
CASE WHEN <spreading_col> = <target_col_element> THEN <expression> END
在我们的示例中,会应用下面三个表达式:
CASE WHEN orderyear = 2006 THEN val END, CASE WHEN orderyear = 2007 THEN val END, CASE WHEN orderyear = 2008 THEN val END
这样,对于每个目标列,只有在数据行的orderyear与之相等时,才返回相应的值val,否则返回NULL,从而实现了数据值到相应目标列的分配和扩展。
PIVOT的第三步会使用指定的聚合函数对每一个CASE表达式进行聚合计算,生成结果列。在我们的示例中,表达式相当于:
SUM(CASE WHEN orderyear = 2006 THEN val END) AS [2006], SUM(CASE WHEN orderyear = 2007 THEN val END) AS [2007], SUM(CASE WHEN orderyear = 2008 THEN val END) AS [2008]
综合上述三个步骤,我们的示例PIVOT查询在逻辑上与下面的SQL查询相同:
SELECT empid, SUM(CASE WHEN orderyear = 2006 THEN val END) AS [2006], SUM(CASE WHEN orderyear = 2007 THEN val END) AS [2007], SUM(CASE WHEN orderyear = 2008 THEN val END) AS [2008] FROM (SELECT empid, YEAR(orderdate) AS orderyear, val FROM dbo.OrderValues) AS OV GROUP BY empid
UNPIVOT
UNPIVOT是PIVOT的反操作,它把数据从列旋转到行。
示例数据
在讲述UNPIVOT的逻辑处理步骤之前,让我们先运行下面的Script来创建示例数据表dbo.EmpYearValues,结果如下:
SELECT * INTO dbo.EmpYearValues FROM (SELECT empid, YEAR(orderdate) AS orderyear, val FROM dbo.OrderValues) AS OV PIVOT(SUM(val) FOR orderyear IN([2006],[2007],[2008])) AS P; SELECT * FROM dbo.EmpYearValues
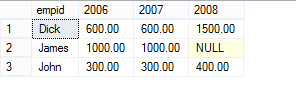
我将会使用下面的示例查询来描述UNPIVOT操作符的逻辑处理步骤:
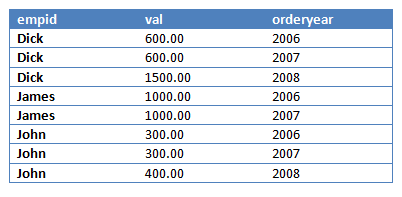
SELECT empid, orderyear, val FROM dbo.EmpYearValues UNPIVOT(val FOR orderyear IN([2006],[2007],[2008])) AS U;
这个查询会对employee每一年(表中IN子句中的每一列)的值分割到单独的数据行,生成如下结果:
UNPIVOT逻辑处理步骤解析
UNPIVOT操作符包含如下三个逻辑处理步骤:
- U1: 生成数据副本
- U2: 抽取数据
- U3: 删除带NULL值的行
第一步会生成UNPIVOT输入表的数据行的副本(在我们的示例中为dbo.EmpYearValues)。它会为UNPIVOT中IN子句定义的每一列生成一个数据行。因为我们在IN子句中有三列,所以会为每一行生成三个副本。新生成的虚表会包含一个新数据列,该列的列名为IN子句前面指定的名字,列值为IN子句中指定的列表的名字。对于我们的示例,该虚表如下所示:

第二步会为UNPIVOT的当前行从原始数据列中(列名与当前orderyear的值关联)抽取数据,用于存放抽取数据的列名是在FOR子句之前定义的(我们的示例中为val)。这一步返回的虚表如下:

第三步会消除结果列(val)中值为NULL的数据行,结果如下:
OVER子句
OVER子句用于支持基于窗口(window-based)的计算。我们可以随聚合函数一起使用OVER子句,它同时也是四个分析排名函数(ROW_NUMBER、RANK、DENSE_RANK和NTILE)的必要元素。OVER子句定义了数据行的一个窗口,而我们可以在这个窗口上执行聚合或排名函数的计算。
在我们的SQL查询中,OVER子句可以用于两个逻辑阶段:SELECT阶段和ORDER BY阶段。这个子句可以访问为相应逻辑阶段提供的输入虚表。
在下面的示例中,我们在SELECT子句中使用了带COUNT聚合函数的OVER子句:
SELECT orderid, customerid, COUNT(*) OVER(PARTITION BY customerid) AS numorders FROM dbo.Orders
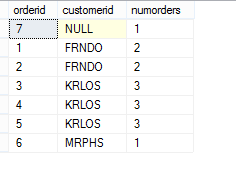
PARTITION BY子句定义了执行聚合计算的窗口,COUNT(*)汇总了SELECT输入虚表中customerid的值等于当前customerid的行数。
我们还可以在ORDER BY子句中使用OVER子句,如下:
SELECT orderid, customerid, COUNT(*) OVER(PARTITION BY customerid) AS numorders FROM dbo.Orders ORDER BY COUNT(*) OVER(PARTITION BY customerid) DESC
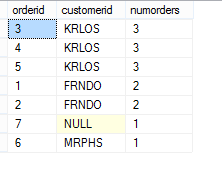
关于OVER子句,篇幅所限,我在这里不准备详细的讨论它的工作方式,只是简单的介绍了它的使用方式。如有机会,我会在后续博客中对它进行详细的解析。
集合运算符
SQL Server 2008支持四种集合运算符:UNION ALL,UNION,EXCEPT和INTERSECT。这些SQL运算符对应了数学领域中相应的集合概念。
通常,一个包含集合运算符的查询结构如下所示,每一行前面的数字是指该元素运行的逻辑顺序:
(1) query1 (2) <set_operator> (1) query2 (3) [ORDER BY <order_by_list>]
集合运算符会比较两个输入表中的所有行。UNION ALL返回的结果集包含了所有两个输入表中的行。UNION返回的结果集中包含了两个输入表中的不同的数据行(没有重复行)。EXCEPT返回在第一个输入中出现,但没有在第二个输入中出现的数据行。INTERSECT返回在两个输入中都出现过的数据行。
在涉及集合运算的单个查询中不允许使用ORDER BY 子句,因为查询期望返回的是(无序的)集合。但我们可以在查询的最后指定ORDER BY子句,对集合运算的结果进行排序。
从逻辑处理角度来看,每个输入查询都会根据自己的相应阶段进行处理,然后处理集合运算符。如果指定了ORDER BY子句,它作用于集合运算符产生的结果集。
比如,下面的查询:
SELECT region, city FROM Sales.Customers WHERE country = N'USA' INTERSECT SELECT region, city FROM HR.Employees WHERE country = N'USA' ORDER BY region, city;
首先,每个输入查询都会单独处理。第一个查询返回来自USA的客户位置,第二个查询返回来自USA的员工位置。INTERSECT返回同时出现在两个输入查询中的记录,即同时属于客户和员工的位置。最后,按照位置信息进行排序。
理解逻辑查询处理的各个阶段和SQL的一些特性,对于理解SQL编程的特殊性和树立正确的思维方式是非常重要的。我们的目的是真正的掌握这些必要的基础知识,这样我们就可以写出优雅的查询,制定出高效的解决方案,并且了解其中的原理。
出处:http://www.cnblogs.com/lifepoem/archive/2013/03/26/2981494.html