redis的五大数据类型:
string hash list set sorted_set
string
特点:
存储的数据:单个数据,最简单的数据存储类型,也是最常用的数据存储类型
存储数据的格式:一个存储空间保存一个数据
存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用
基础使用:
127.0.0.1:6379> set univercity ccu
OK
127.0.0.1:6379> get univercity
"ccu"
127.0.0.1:6379> del univercity
高级使用:
【一次性创建多个键值,获取多个键值。值的长度。值的追加】
127.0.0.1:6379> mset desk red pan white
127.0.0.1:6379> mget desk pan
127.0.0.1:6379> strlen desk
(integer) 3
127.0.0.1:6379> append desk -desk
(integer) 8
127.0.0.1:6379> get desk
"red-desk"
127.0.0.1:6379>
扩展:
127.0.0.1:6379> incr desk-height【默认初始为1】
(integer) 1
127.0.0.1:6379> get desk-height
"1"
127.0.0.1:6379> incrby desk-height 30
(integer) 31
127.0.0.1:6379> incrbyfloat desk-height 2.1
"33.100000000000001"
没有递减的浮点数
127.0.0.1:6379> decr desk-weight
(integer) -1
127.0.0.1:6379> decr desk-weight 20
定制数据的有效时间
127.0.0.1:6379> setex death-time 59 death
OK
127.0.0.1:6379> ttl death-time
(integer) 30
127.0.0.1:6379> get death-time
"death"
127.0.0.1:6379> psetex li 50000 time
OK
127.0.0.1:6379> get li
"time"
127.0.0.1:6379> ttl li
(integer) 40
hash
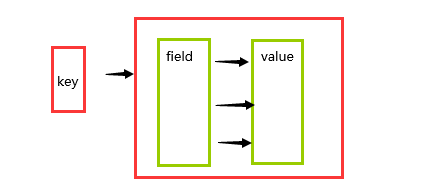
新的存储需求:对一系列存储的数据进行编组,方便管理,典型应用存储对象信息
需要的存储结构:一个存储空间保存多个键值对数据
hash类型:底层使用哈希表结构实现数据存储
hash存储结构优化
如果field数量较少,存储结构优化为类数组结构
如果field数量较多,存储结构使用HashMap结构
应用
基础:设置,获取,删除 127.0.0.1:6379> hset man field short-hair (integer) 1 127.0.0.1:6379> hset man field2 blue-eye (integer) 1 127.0.0.1:6379> hgetall man 1) "field" 2) "short-hair" 3) "field2" 4) "blue-eye" 127.0.0.1:6379> hdel man field2 (integer) 1 127.0.0.1:6379> hgetall man 1) "field" 2) "short-hair" 127.0.0.1:6379>
批量使用:
hexists key field【存在】
hmset key field1 value1 field2 value2 【设置】
hmget key field1 field2【获取】
hlen key【总长度】
hash 类型应用场景
电商网站购物车设计与实现
增加:hincrby 设置:hset
商品id:field 用户id:key
删除:hdel 总量:hlen
全选:hgetall 数量:value
总量:hlen 数量:value
商品id:field 取值:hget
业务分析
仅分析购物车的redis存储模型
添加、浏览、更改数量、删除、清空
购物车于数据库间持久化同步
购物车于订单间关系
提交购物车:读取数据生成订单
商家临时价格调整:隶属于订单级别
未登录用户购物车信息存储
cookie存储
list
数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
需要的存储结构:一个存储空间保存多个数据,且通过数据可以体现进入顺序
list类型:保存多个数据,底层使用双向链表存储结构实现
基本使用:
127.0.0.1:6379> lpush tup 1 2 3
(integer) 3
127.0.0.1:6379> rpush tup 4 5
(integer) 5
127.0.0.1:6379> lrange tup 1 3
1) "2"
2) "1"
3) "4"
127.0.0.1:6379> lrange tup 0 4
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
当然还有获取索引位置和长度获取
扩展:
规定时间内获取并移除数据
blpop key1 [key2] timeout
brpop key1 [key2] timeout
brpoplpush source destination timeout
set
新的存储需求:存储大量的数据,在查询方面提供更高的效率
需要的存储结构:能够保存大量的数据,高效的内部存储机制,便于查询
set类型:与hash存储结构完全相同,仅存储键,不存储值(nil),并且值是不允许重复的
基本使用:
127.0.0.1:6379> sadd num [2 2 4]
(integer) 3
127.0.0.1:6379> smembers num【可以看出来,存储的数据类型不单一,但是以空格作为界定是很明显的】
1) "4]"
2) "[2"
3) "2"
127.0.0.1:6379> srem num 4
(integer) 0
127.0.0.1:6379> srem num 2
(integer) 1
127.0.0.1:6379> smembers num
1) "4]"
2) "[2"
127.0.0.1:6379> sadd num 1 2 4
(integer) 3
127.0.0.1:6379> smembers num
1) "2"
2) "1"
3) "4]"
4) "[2"
5) "4"
127.0.0.1:6379> scard num
(integer) 5
127.0.0.1:6379> sismember num 1
(integer) 1
127.0.0.1:6379>
交并差集的实现:
sinter key1 [key2]
sunion key1 [key2]
sdiff key1 [key2]
set 类型应用场景
公司对旗下新的网站做推广,统计网站的PV(访问量),UV(独立访客),IP(独立IP)。
PV:网站被访问次数,可通过刷新页面提高访问量
UV:网站被不同用户访问的次数,可通过cookie统计访问量,相同用户切换IP地址,UV不变
IP:网站被不同IP地址访问的总次数,可通过IP地址统计访问量,相同IP不同用户访问,IP不变
sorted_set
新的存储需求:数据排序有利于数据的有效展示,需要提供一种可以根据自身特征进行排序的方式
需要的存储结构:新的存储模型,可以保存可排序的数据
sorted_set类型:在set的存储结构基础上添加可排序字段
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
redis 127.0.0.1:6379> ZADD runoobkey 1 redis
(integer) 1
redis 127.0.0.1:6379> ZADD runoobkey 2 mongodb
(integer) 1
redis 127.0.0.1:6379> ZADD runoobkey 3 mysql
(integer) 1
redis 127.0.0.1:6379> ZADD runoobkey 3 mysql
(integer) 0
redis 127.0.0.1:6379> ZADD runoobkey 4 mysql
(integer) 0
redis 127.0.0.1:6379> ZRANGE runoobkey 0 10 WITHSCORES