理论部分:
一、爬虫的本质:使用代码,模拟用户,批量地发送网络请求,批量地获取数据。
网络请求:当用户在浏览器的地址栏中,输入网址,发送请求。
二、HTTP超文本传输协议:规定如何发送和接收网络请求。
参考《HTTP与HTTPS图解》
流程:

三、HTTP发送请求的方式:
3.1 get:
(1)可以在URL中带着参数,发送给服务器。服务器返回完整的数据流给浏览器。
(2)局限性:get请求会将参数,明文显示;参数的长度有限制。
3.2 post:
(1)数据大小没有限制
(2)服务器返回完整的数据给我们
3.3 put:
3.4 delete:
3.5 head:
——put、delete、head,都不能返回完整的数据流。
四、请求头、响应头、请求体、响应体:
4.1 general:通用设置
(1)Request URL:地址栏信息
(2)Request Method:发送请求的方式
(3)status code:状态码
——200:网络请求发送成功,服务器返回状态正确的数据。
——非200:网络请求发送不成功。
可以进行的操作:
a. 重新发送网络请求
b. 结合try except
(4)Remote Address:IP地址
(5)Referrer Policy:反向的URL
4.2 Response Headers:响应头
4.3 Request Headers:请求头(重点)
(0)真实的用户信息,全部都在请求头里面。而爬虫要做的就是模拟真实用户——应对反爬。
(1)Accept:文本格式。告诉服务器,发送的请求的文件的格式;告诉服务器,要返回什么样格式的代码。
(2)Accept Encoding:编码格式;压缩格式
(3)Accept—language:zh-CN,zh;1=0.9 返回的是中文格式
(4)Connection:长链接还是短连接
keep-alive:长链接
(5)Cookie(重要):验证用
(6)Host:域名
(7)Referrer:标志从哪一个界面,跳转到当前界面
(8)User-Agent:存储浏览器和用户的信息
4.4 Query String Parameter:
五、robot协议:针对通用爬虫
5.1 通用爬虫:
(1)搜索引擎
(2)优势:速度快、开放性
(3)劣势:目标不明确;返回内容90%以上都是用户不需要的;不清楚用户的需求在哪里
5.2 聚焦爬虫:
(1)优势:目标明确;对用户需求解读精准;返回的内容固定。
(2)增量式爬虫:需要一页一页翻
(3)深度爬虫:静态数据:HTML+CSS
动态数据:JS代码+加密的JS代码
六、写爬虫所使用的模块:
(1)python原生的:
python3:urllib.request
python2:urllib2
(2)request模块:
request模块封装的就是urllib.request
七、爬虫的工作原理:(重要)
(1)确认要抓取的目标网页的URL(需要自己找)
(2)python代码发送网络请求,获取数据
(3)解析获取到的数据(精确地解析得到的所需数据)
(4)找新的目标URL,循环到第一步;
——多页数据
——需要分析URL的规律
(5)数据持久化——数据保存
实战:
(1)爬取不带参数的网页
(2)参数拼接:爬取带1个参数的网页
(3)参数拼接:爬取带有多个参数的网页
1. 爬取不带参数的百度首页:
import urllib.request #爬取百度首页www.baidu.com def load(): #1.目标网页URL地址 URL = "http://www.baidu.com/" #2.发送网络请求: #发送的是什么请求类型,可以在浏览器的network中查看 #返回response对象,使用response对象接收服务器返回的数据 response = urllib.request.urlopen(URL) #打印response对象,结果得到response对象地址 print(response) #3.读取response对象里面的具体内容数据 data = response.read() #因为爬取回来的数据是2进制格式,需要将数据换成字符串格式 #4.数据转码,二进制——>字符串 str_data = data.decode("utf-8") #具体网页爬取回来的是什么编码格式数据,需要在浏览器中的network中查看具体网页 #5.将数据写入文件: with open('baidu01.html', 'w', encoding = 'utf-8') as f: f.write(str_data) load()
(1)结果:在pycharm中,使用浏览器直接打开baidu01.html文件,浏览器中的地址栏开头为localhost,说明这个网页是从本地启动的。

(2)遇到的问题:将baidu01.html中代码,copy到一个新的.html文档中,打开html文件,不能显示百度字样的logo图片
为什么同样一段代码,会出现两种不同情况?
A:查看网页代码,发现该段图片的代码为:src="//www.baidu.com/g/bd_logo1.png";缺少了HTTP协议开头!
在pycharm中,使用浏览器打开,浏览器会自动补全,开头协议;而打开HTML文件,却不会补全,导致图片链接失败。
修正方法:在HTML文件中,将该段代码,加上HTTP或HTTPS开头,src="https://www.baidu.com/g/bd_logo1.png",logo图片再次正常。

(3)str_data = data.decode("utf-8"):
3.1 网络传输数据,都是通过二进制格式传输的。所以response.read()得到的数据,永远都是二级制格式!!!
3.2 传输过来的数据,是2进制格式,浏览器自动把数据转码了
3.3 response.read()读取之后得到的数据,是否需要.decode('utf-8')转码,看实际需求。有时候,我们需要把爬取下来得到的数据保存到Excel文件中,这时就需要将数据转码成字符串格式,否则,无法打开Excel文件。
这个涉及到计算机原理,博主也不是很懂。。。。但是,只要记住结论就行,response.read()得到的数据永远都是二进制格式,是否转码看需求。
2. 拼接参数——只拼接一个参数:
(1)假设我们要爬取,百度关于“美女”的搜索结果页面首页
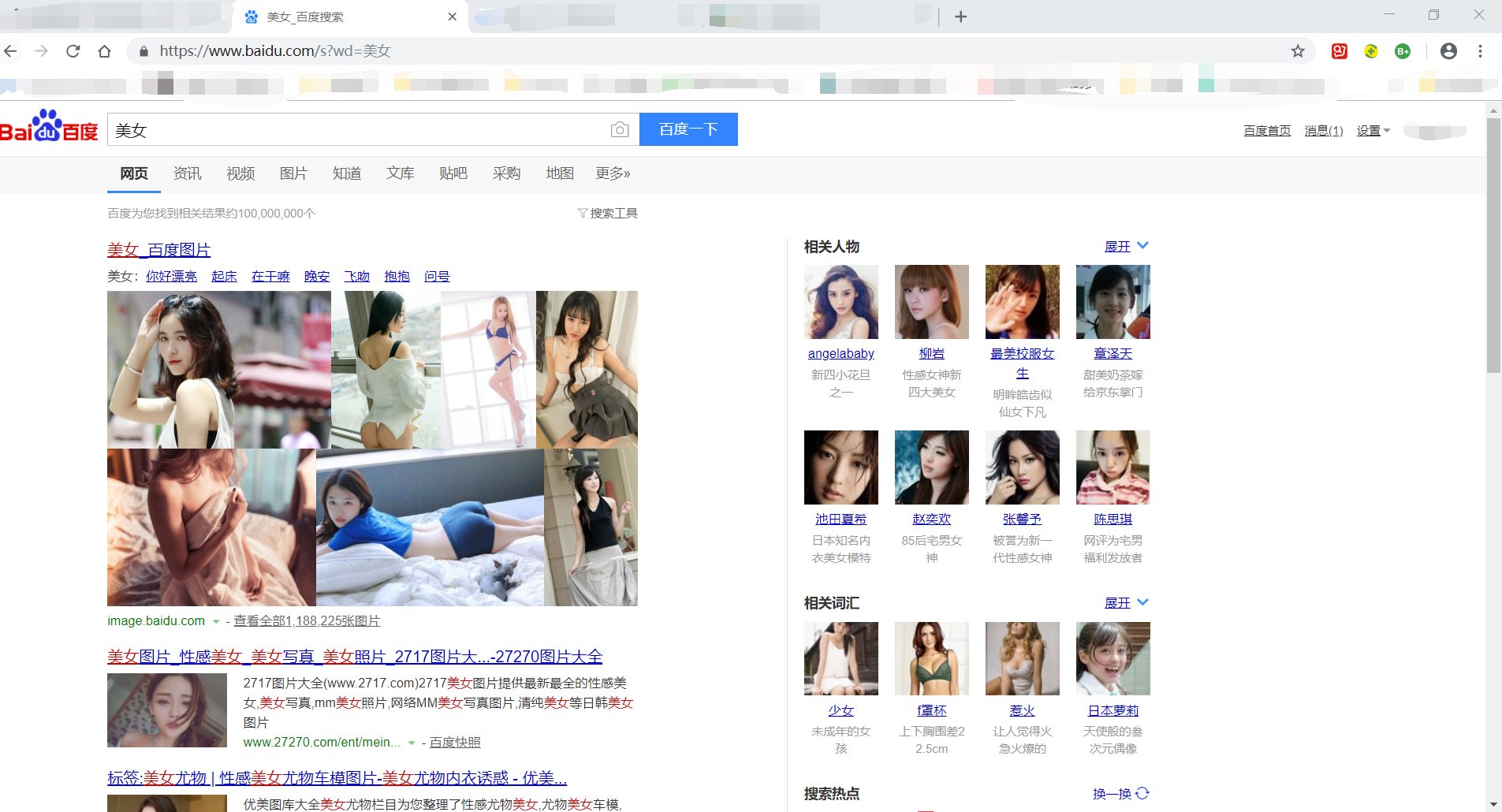
(2)观察网页的URL,发现是:https://www.baidu.com/s?wd=美女
结构为:固定URL(https://www.baidu.com/) + /s?wd= + 关键字(美女)的形式
注意:这里的固定网址和可变参数之间的“ /s?wd=”,这个是网站后台自己定义的,和所要爬取的网站有关系,需要自己去观察所要爬取的网站的URL是什么结构。
(3)中文转译ASCII码:
由于python是解释型语言,python只支持ASCII码,不支持中文。
所以,如果URL地址中含有中文,就要将它转译成ASCII码,目的是让python能够看得懂。
转译ASCII码的固定写法:
转译后URL = urllib.parse.quote(转译前URL, safe=stringprintable)
(4)代码:
1 import urllib.request
2 import urllib.parse
3 import string
4
5 #爬取百度搜索结果页面,只带一个参数
6 def load():
7 #1.目标网页的URL
8 #1.1固定URL
9 fixed_url = 'https://www.baidu.com/'
10 #1.2需要加入的参数
11 #这里假设要爬取的页面,是关键词“美女”的搜索结果页面,参数为“美女”
12 params = "美女"
13 #1.3拼接参数+固定URL,组成目标网页URL
14 final_url = fixed_url + '/s?wd=' + params
15 #1.4将目标网页URL翻译为ASCII码,得到最终URL
16 new_final_url = urllib.parse.quote(new_final_url, safe=string.printable)
17
18 #2.根据URL,发送网络请求,使用response对象接收返回数据
19 response = urllib.request.urlopen(new_final_url)
20 #3.读取response对象返回数据
21 data = response.read()
22 #4.将数据转为字符串格式
23 str_data = data.decode("utf-8")
24 #5.数据持久化
25 with open('baidu02.html', 'w', encoding=''utf-8') as f:
26 f.write(str_data)
27
28 #调用方法
29 load()
得到baidu02.html文件,运行该文件结果:
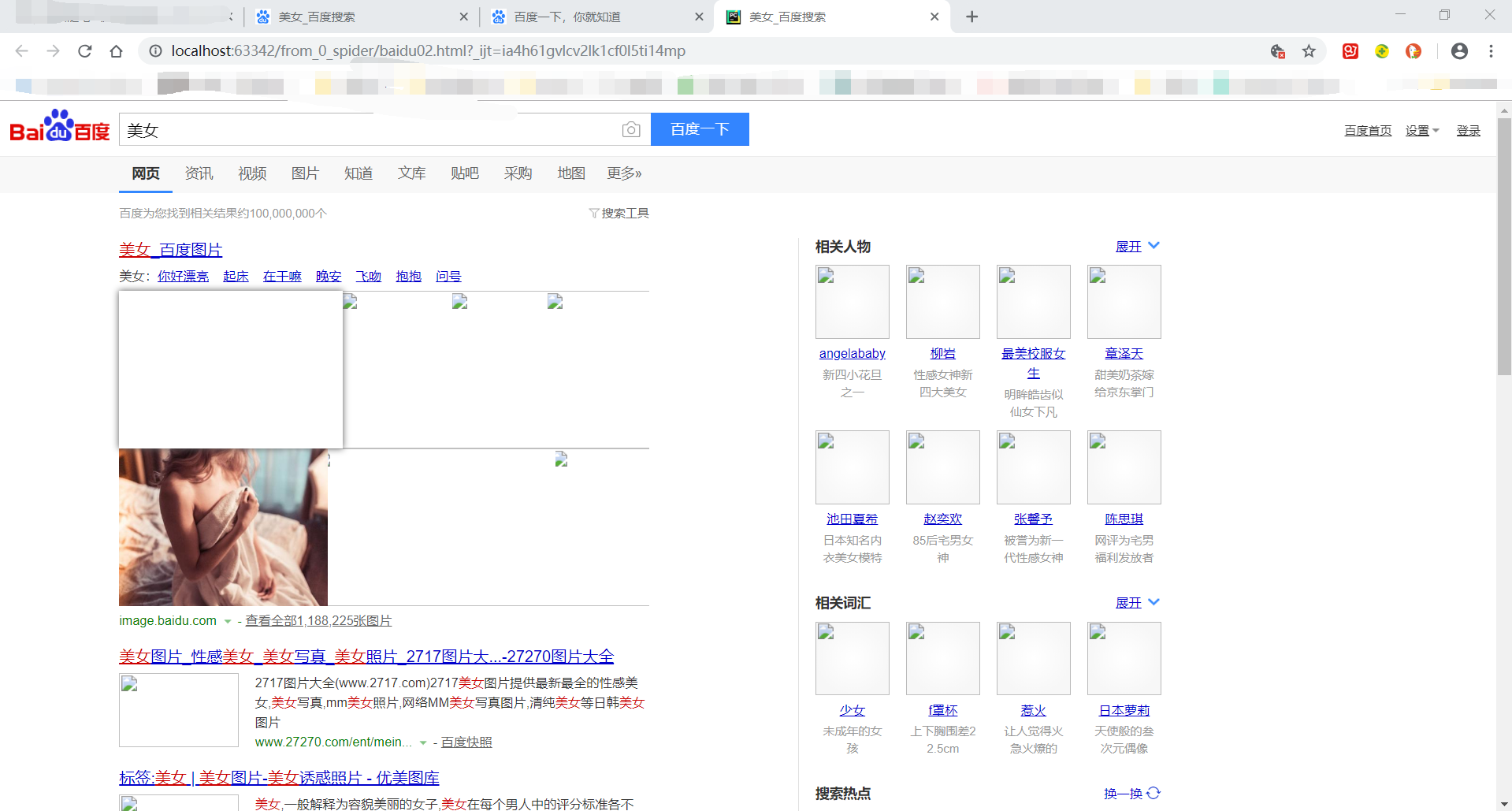
注意:如果不对含有中文的URL转译,就会以下错误:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 11-12: ordinal not in range(128)
3. 拼接参数——拼接多个参数:
(1)目标:爬取搜狗搜索关键词“美女”“哈哈”的搜索结果首页。
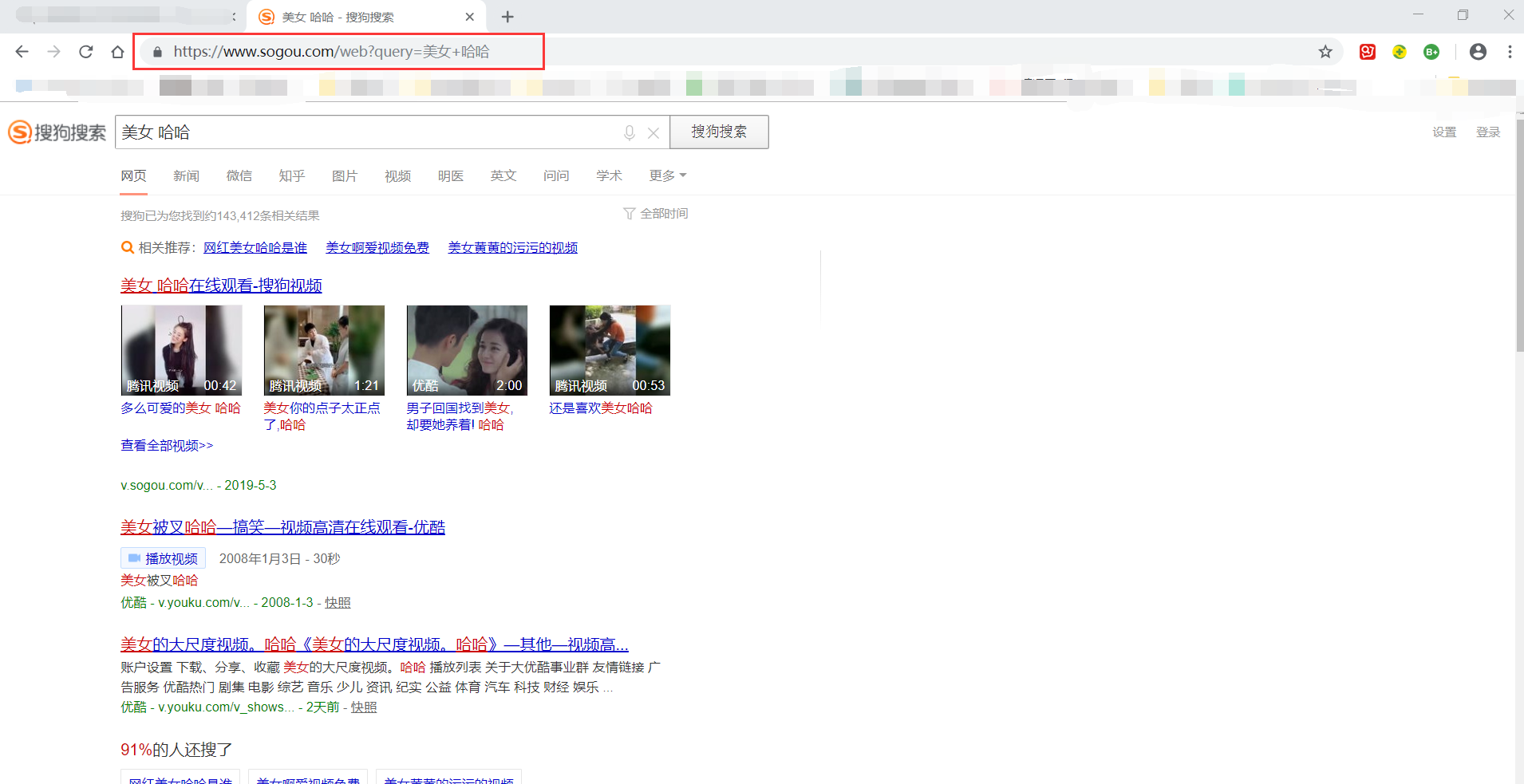
(2)观察网页的URL结构:https://www.sogou.com/web?query=美女+哈哈
固定网址(https://www.sogou.com/)+ web?query + 参数(美女+哈哈)
(3)当所要拼接的参数为多个时:需要构造参数字典。params_dict
(4)代码:
1 import urllib.request
2 import urllib.parse
3 import string
4
5 #爬取搜狗https://www.sogou.com/web?query=美女+哈哈
6 def load():
7 #1.目标URL
8 #1.1固定URL
9 fixed_URL = 'https://www.sogou.com/'
10 #1.2可变参数——关键词
11 #由于有多个参数,需要构造参数字典,参数都放在字典中
12 params_dict = {
13 "key1": "美女",
14 "key2": "哈哈"
15 }
16 #1.3拼接参数和固定URL,得到目标URL
17 final_URL = 'https://www.sogou.com/' + 'web?query=' + params_dict['key1'] + "+" + params_dict['key2']
18 #1.4将目标URL转译,得到最终URL
19 new_final_URL = urllib.parse.quote(final_URL, safe=string.printable)
20
21 request = urllib.request.Request(new_final_URL)
22 request.add_headers('User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1')
23
24 #2.发送网络请求
25 response = urllib.request.urlopen(request)
26 #3.读取response数据
27 data = response.read()
28 #4.将数据转成字符串格式
29 str_data = data.decode('utf-8')
30 #5.持久化
31 with open('sougou01.html', 'w', encoding='utf-8') as f:
32 f.write(str_data)
33 load()
得到sougou01.html,打开文件,结果显示:
注意:
还有一个方法:str_params = urllib.parse.urlencode(参数字典)
- 将key:value之间的冒号(:),变为等号(=),变成key=value形式
- 会将字典中的各个item之间,使用&符连接
- 该方法会同时将URL中的中文,转译成ASCII码形式