概述:处理样本数不规则的模型
recurrent neural network递归神经网络
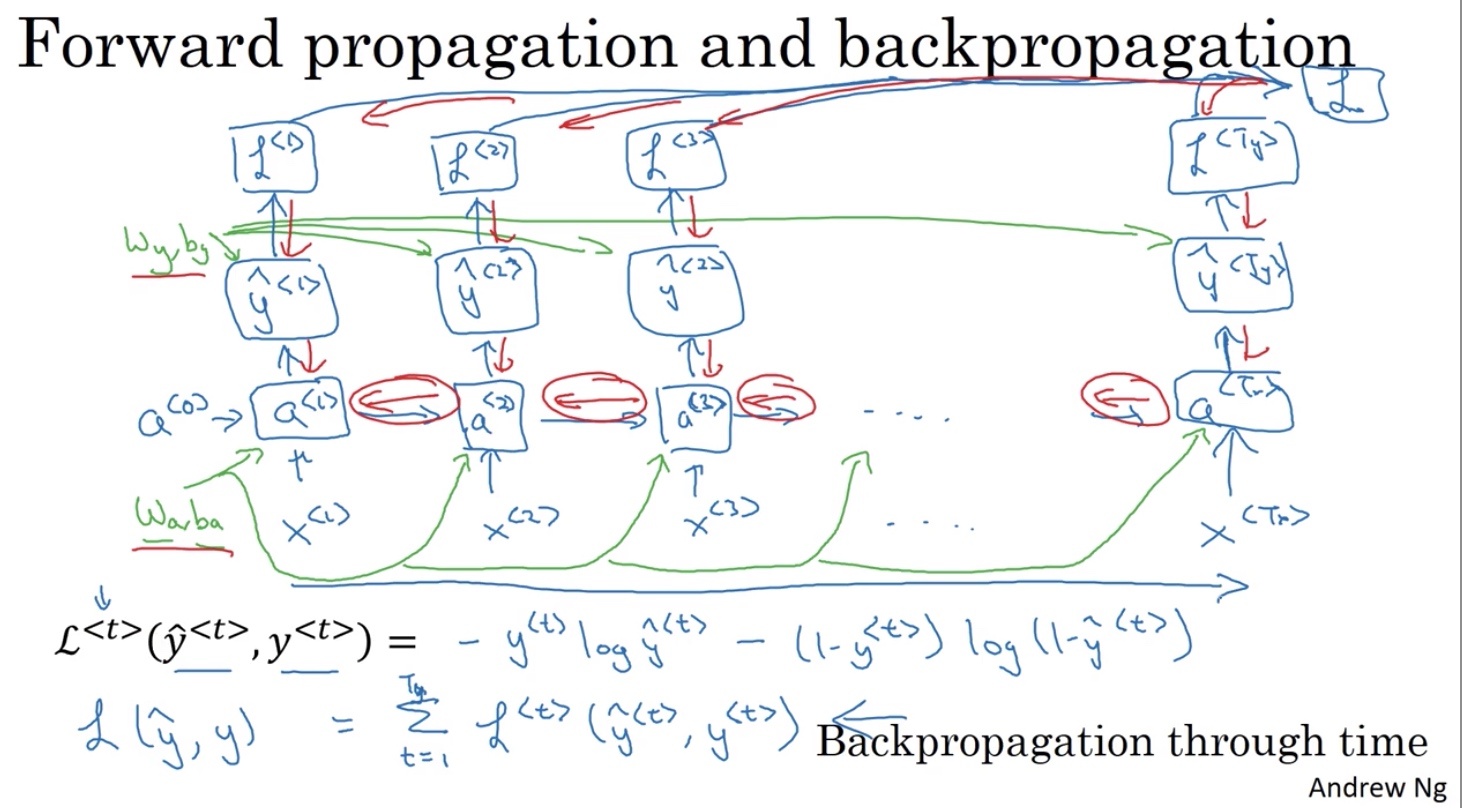
参数共享,前->后
样本逐个扫描
a激活用一套参数
y激活用一套参数
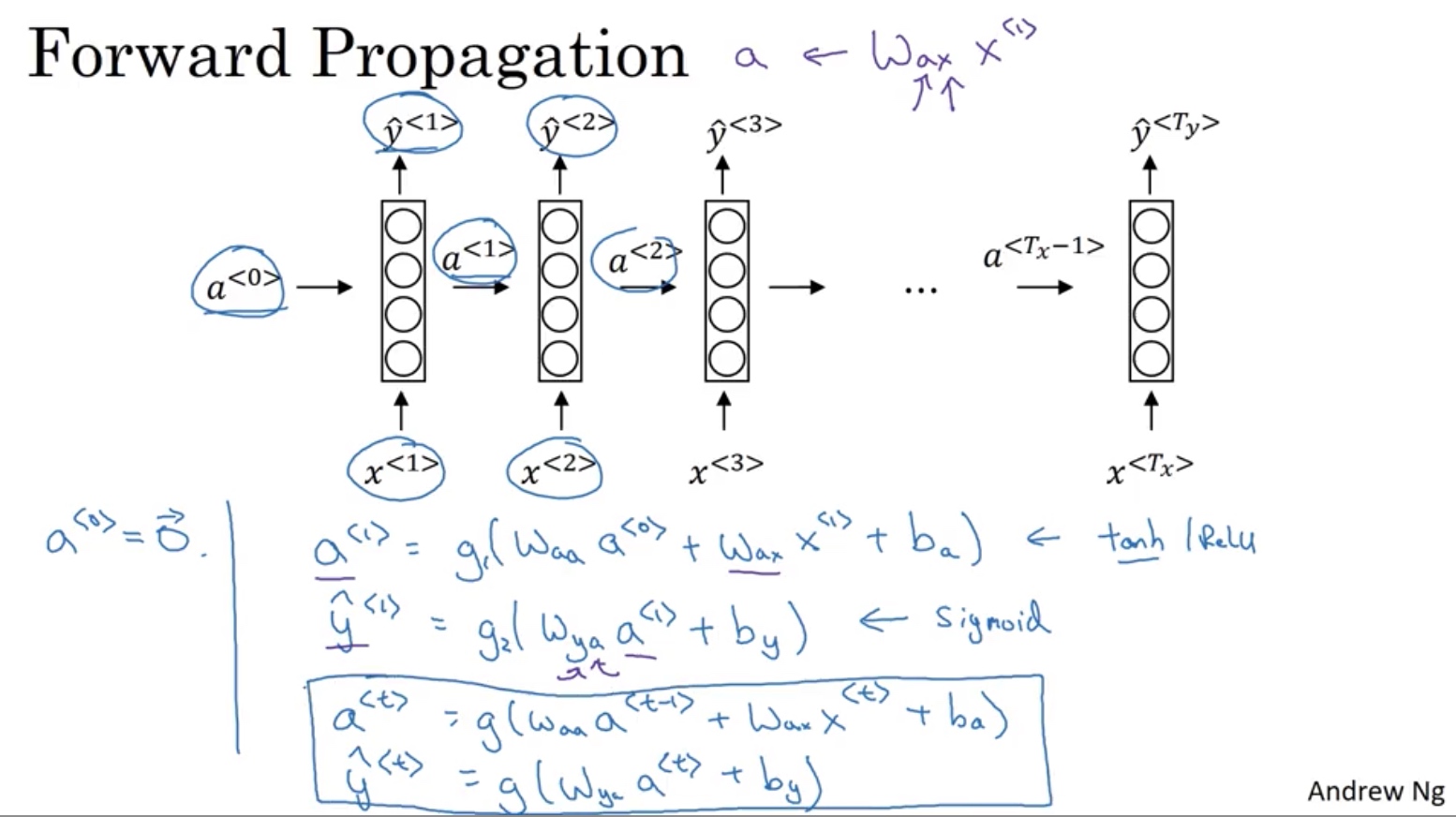
参数流
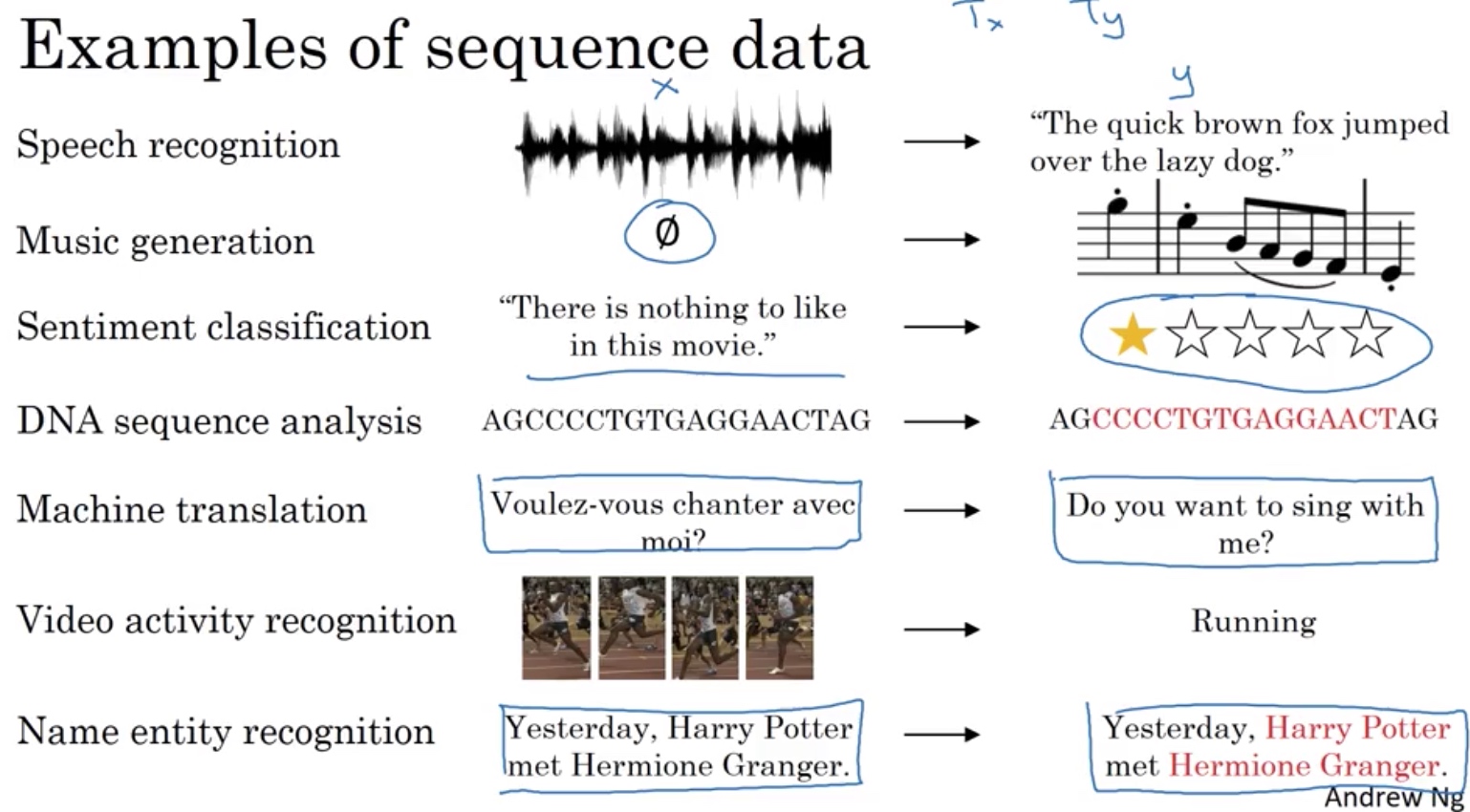
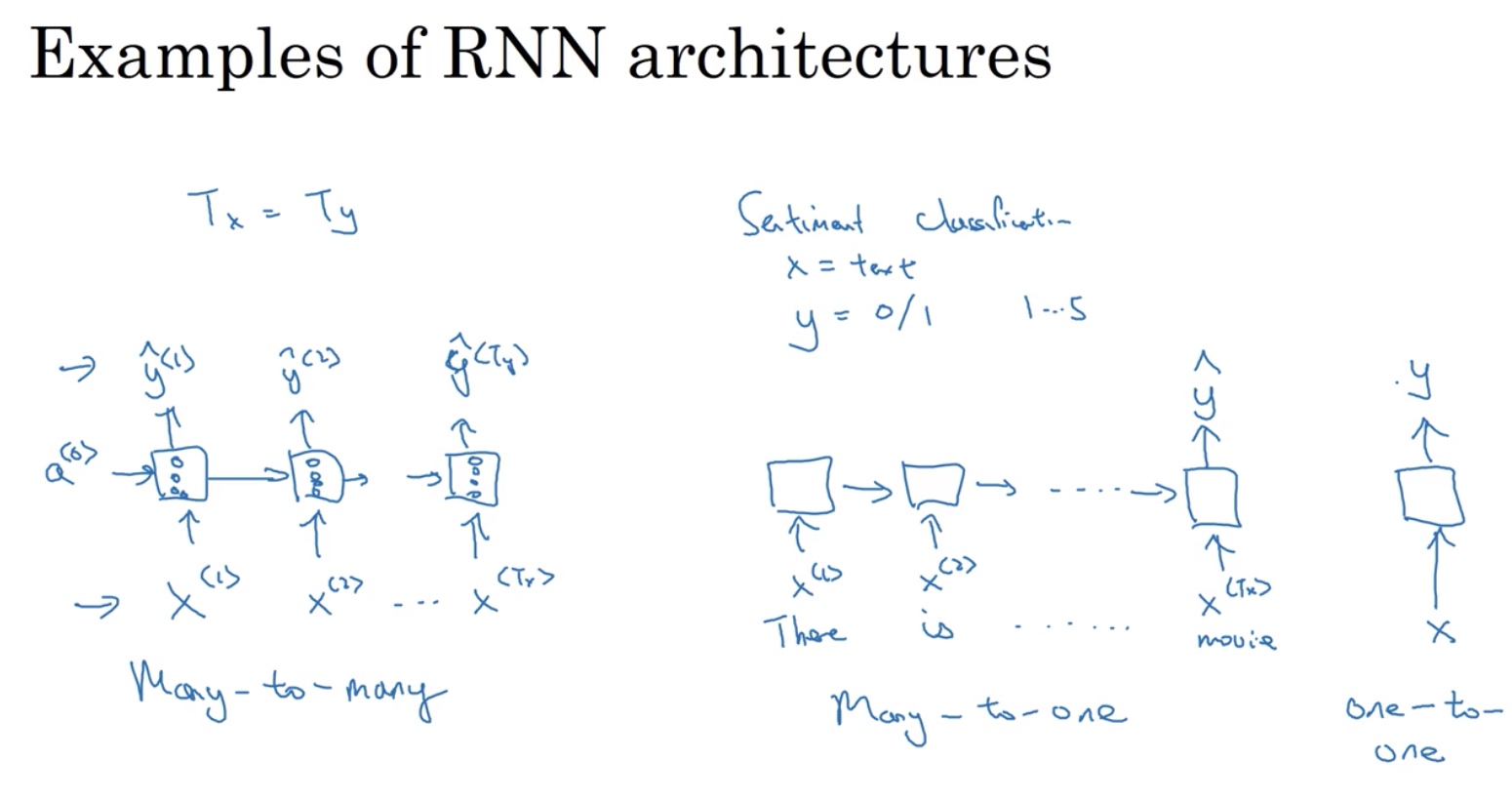
x、y个数不一致的RNN
序列样本分类问题
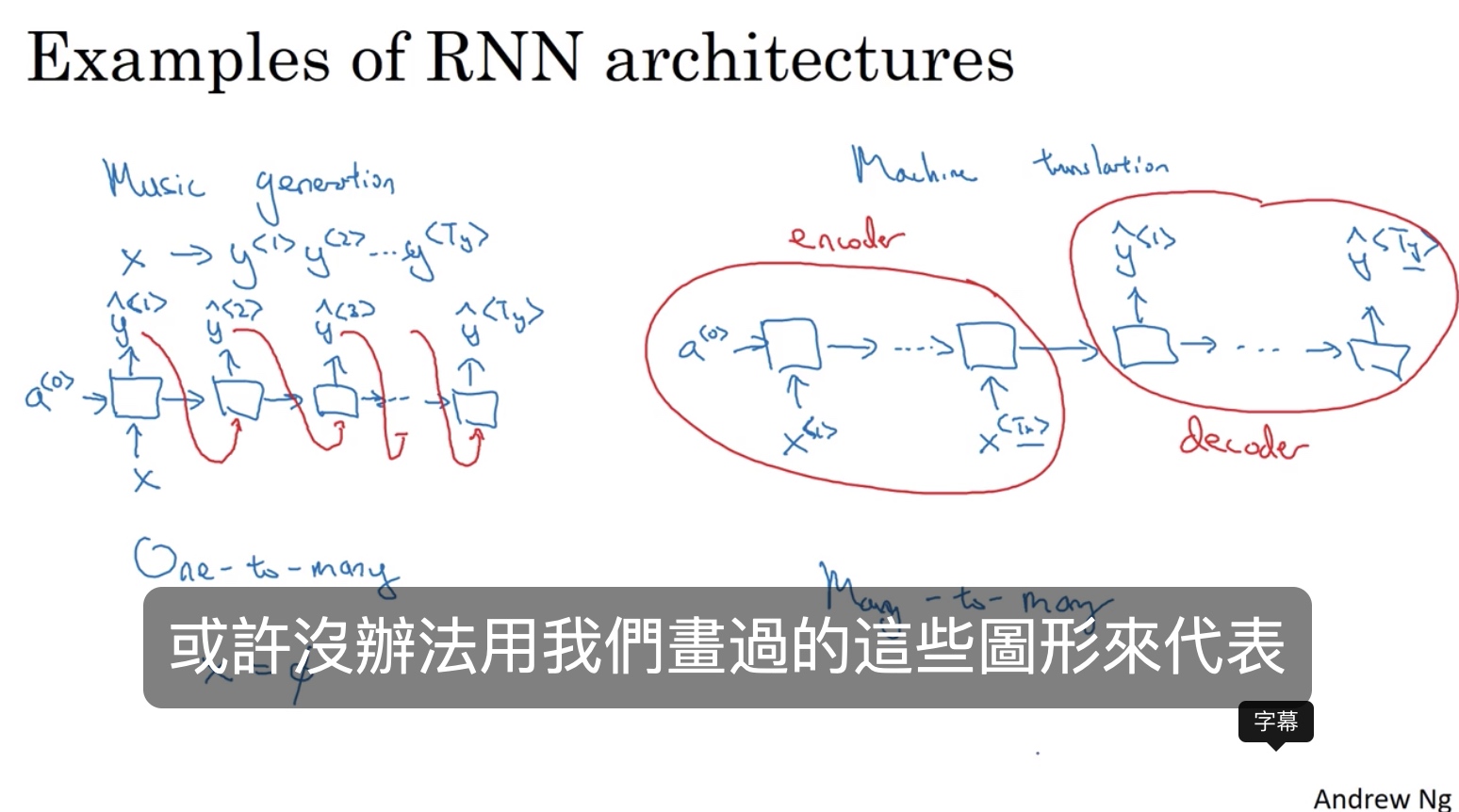
音乐生成、机器翻译
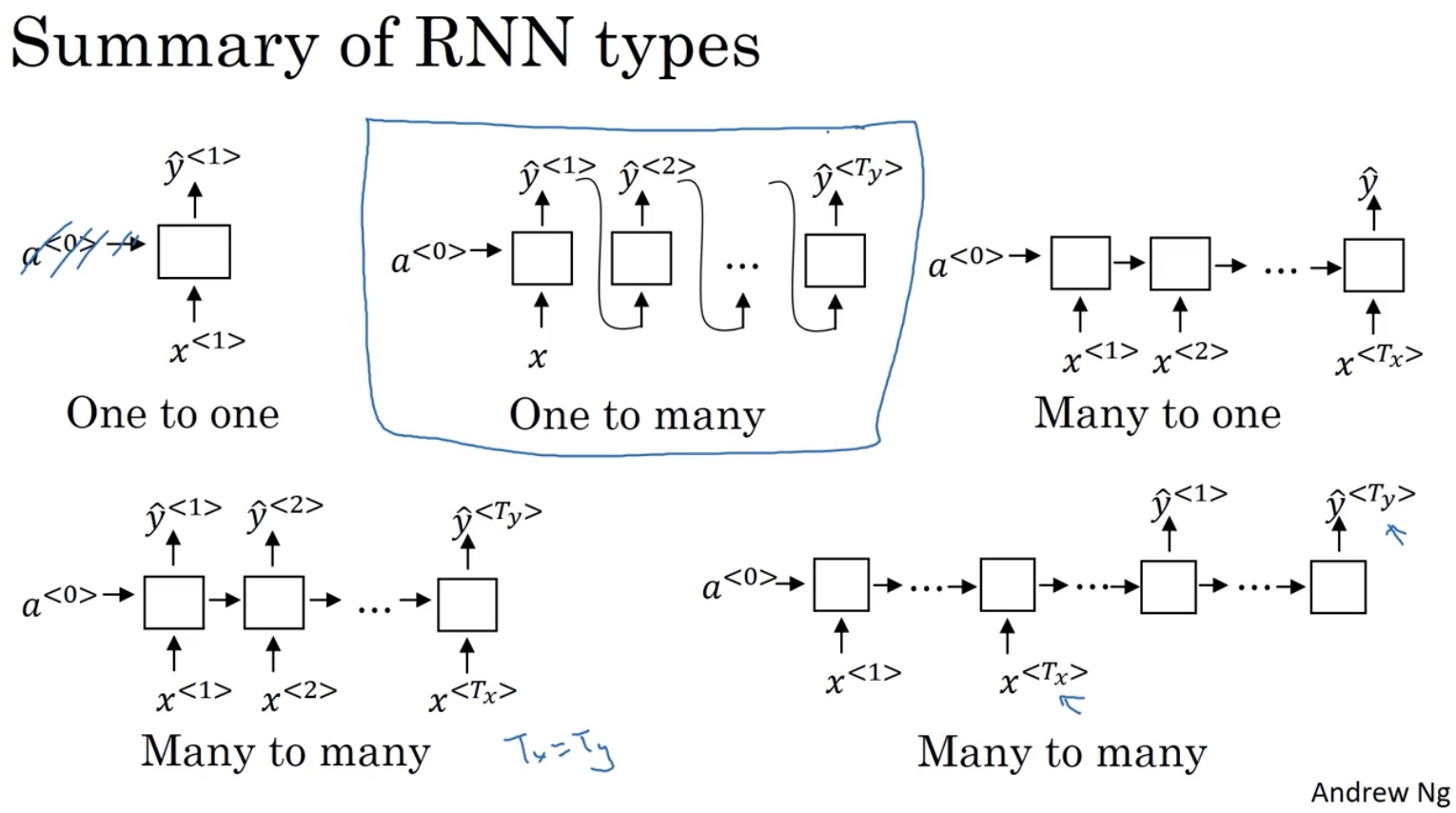
RNN类型总结
language model with RNN
输出P(sentence),并按照y(i)展开为字符串
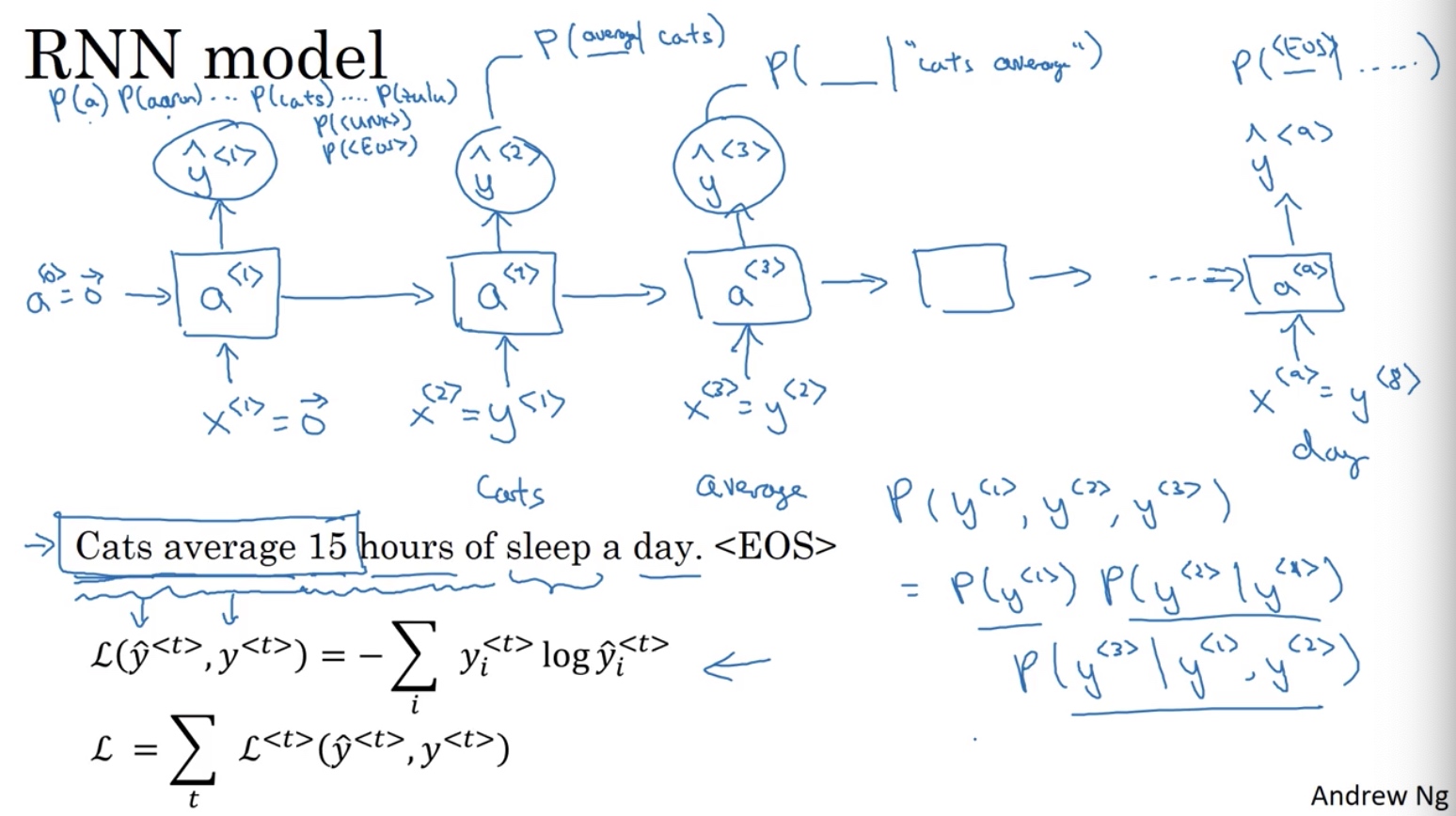
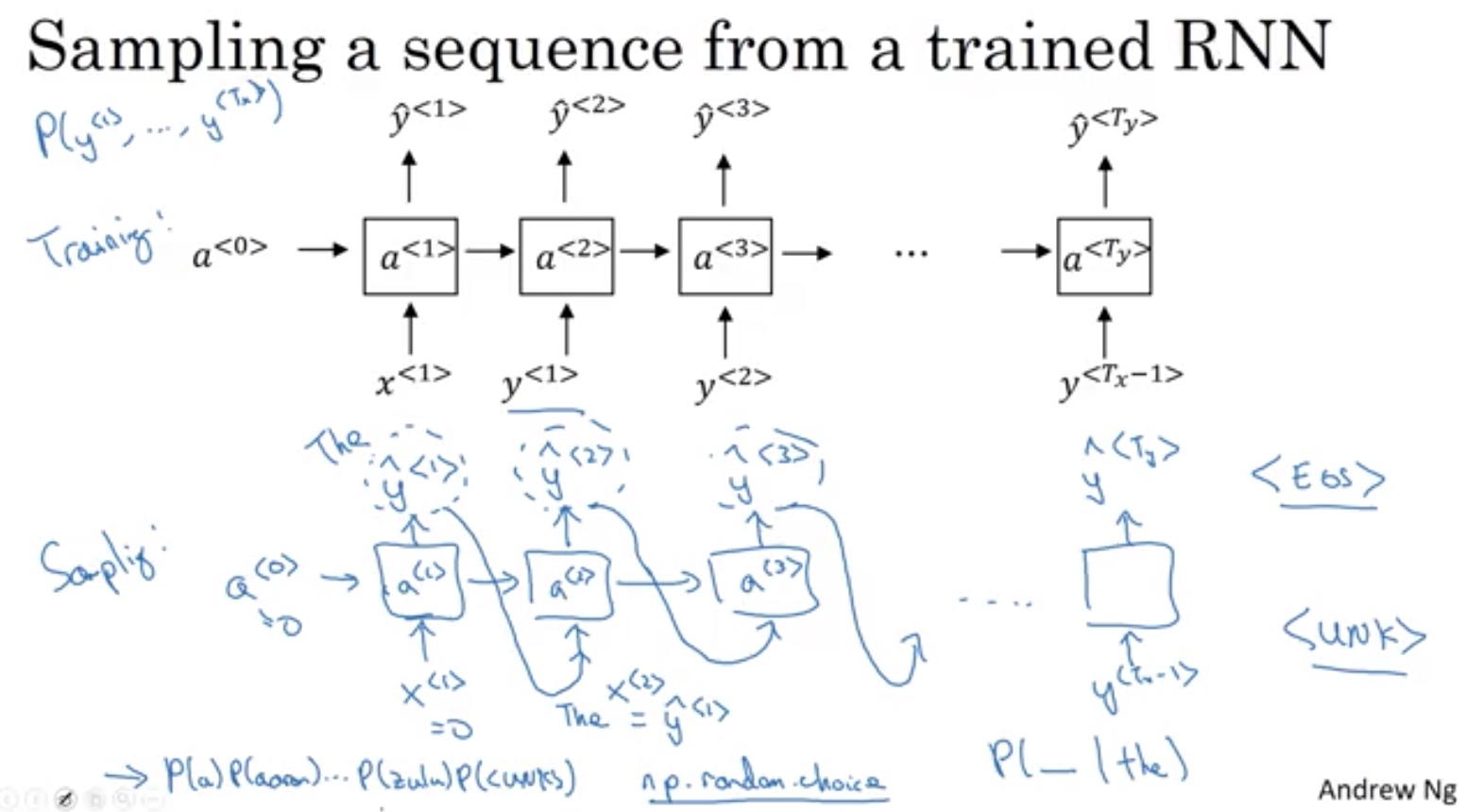
从训练模型采样
在训练过程中,结局梯度爆炸
gradient clipping:梯度过大时,重新缩放梯度向量
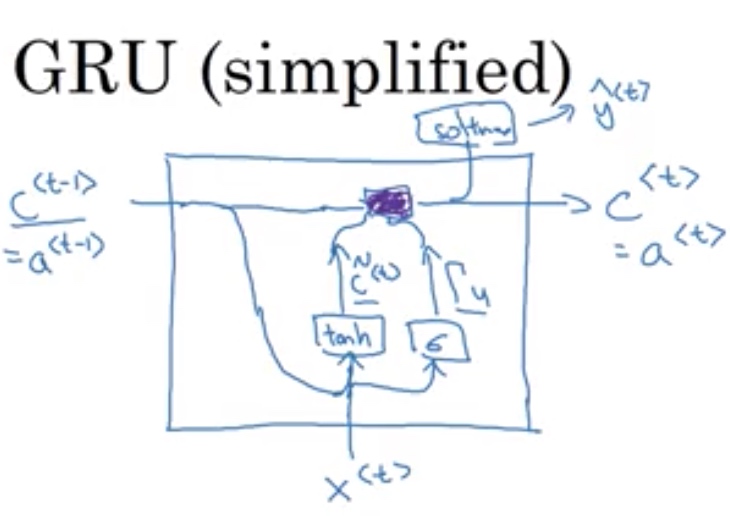
GRU gated recurrent unit
解决了梯度爆炸问题
新建c{
c的估计值
( ilde C^{<t>} = tanh(w_c[c^{<t-1>},x^{<t>}]+b_c))
Gata,门限值,0 or 1,选择是否记忆
(Gamma_u = sigma(w_u[c^{<t-1>},x^{<t>}]+b_u))$
c的实际值更新函数
(c^{<t>} = Gamma_u * ilde c ^{<t>} + (1-Gamma_u) c^{<t-1>})
- GRU单元

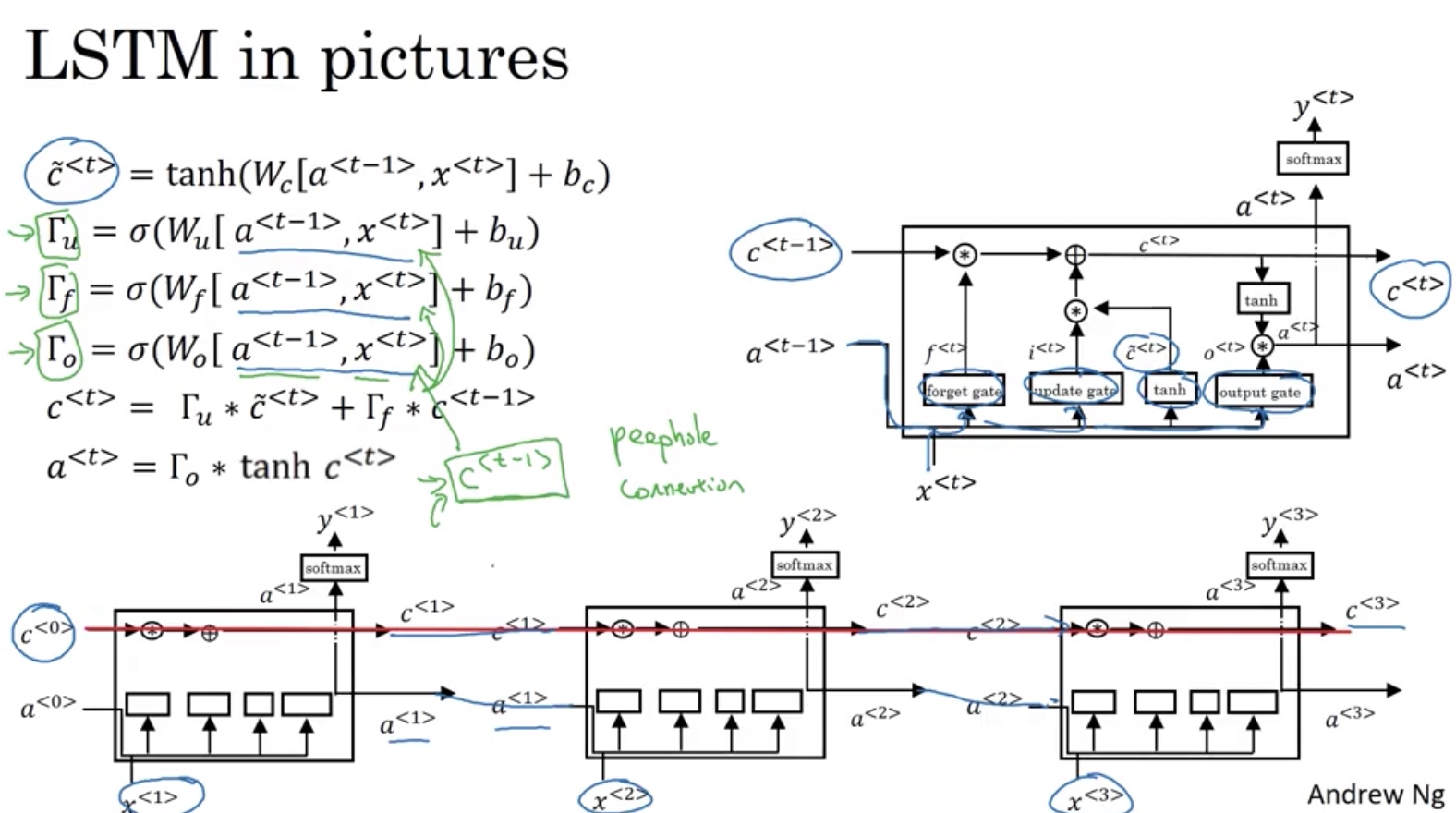
LSTM (Long Short Term Memory)

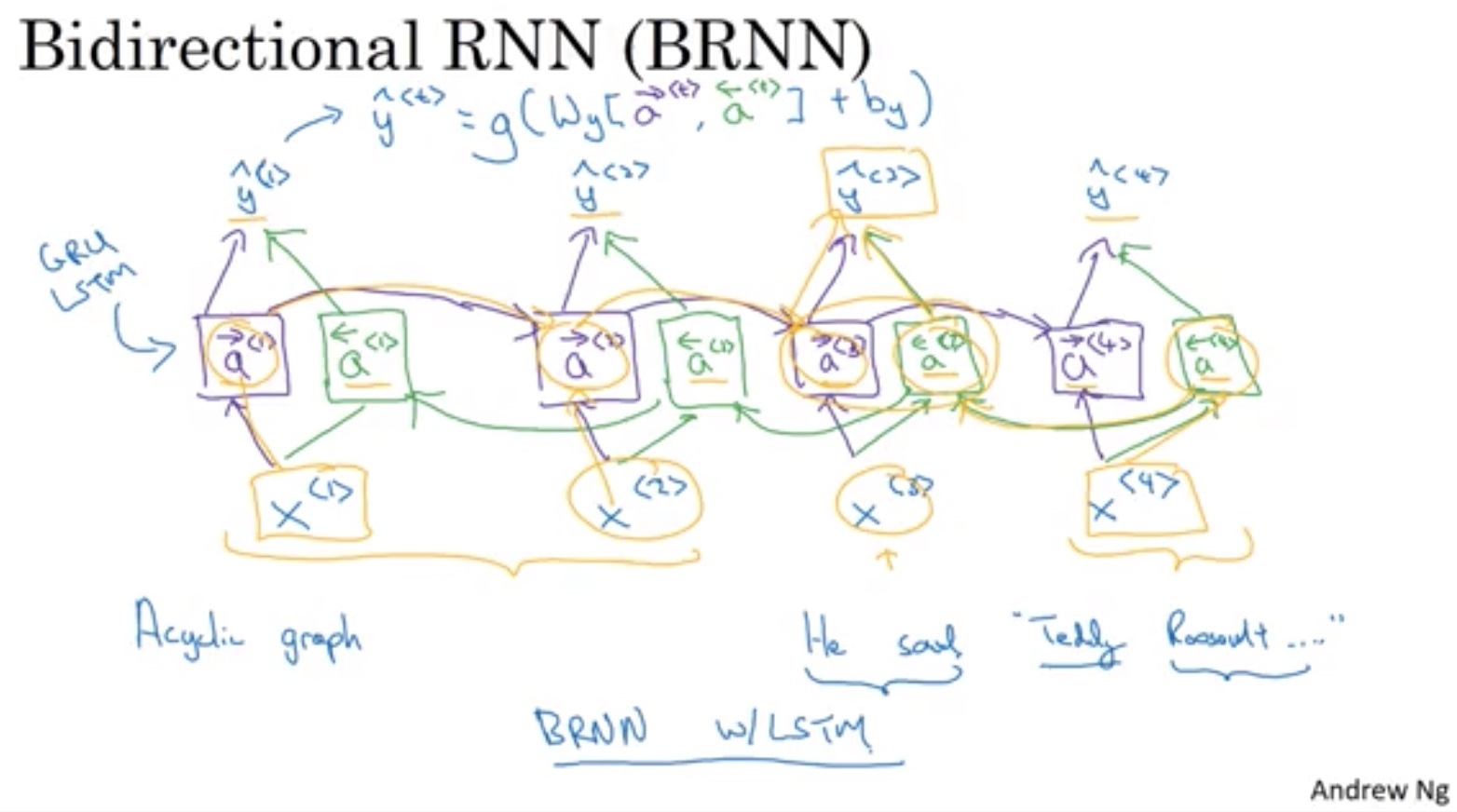
Bidirectional双向 RNN BRNN
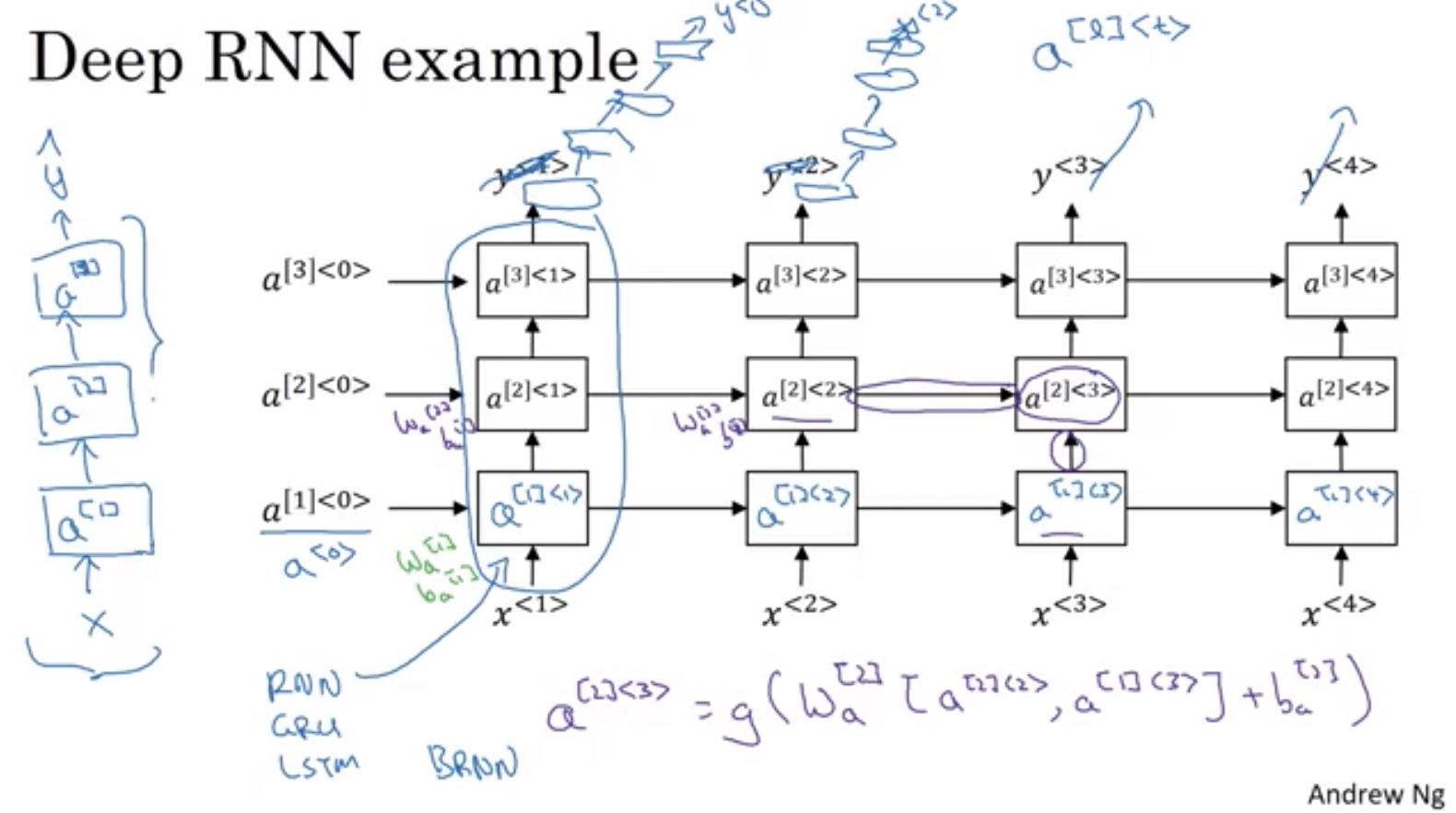
Deep RNN
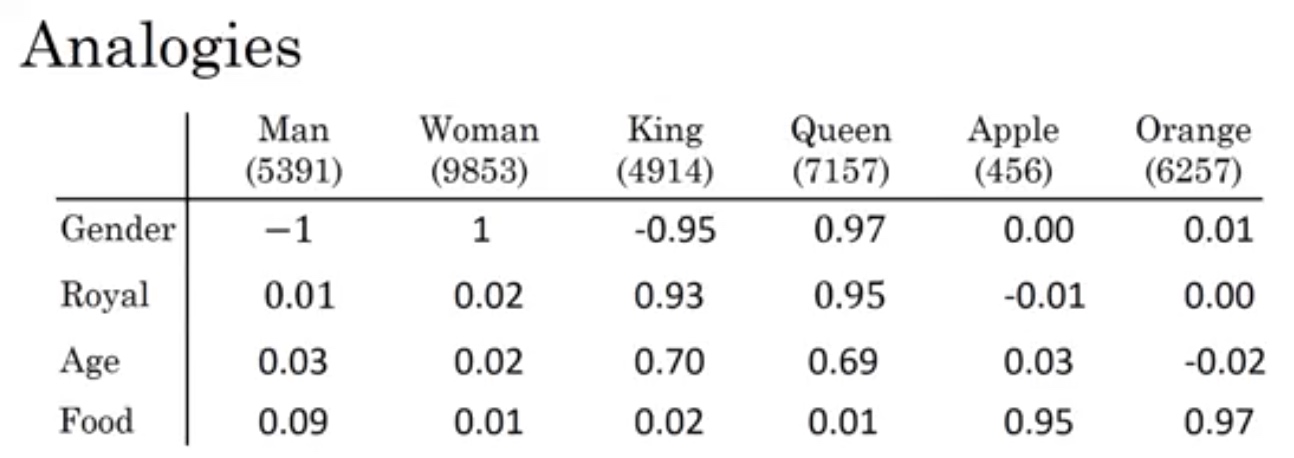
word representation
只用 one-hot,无法表征单词之间的关系
点积为0
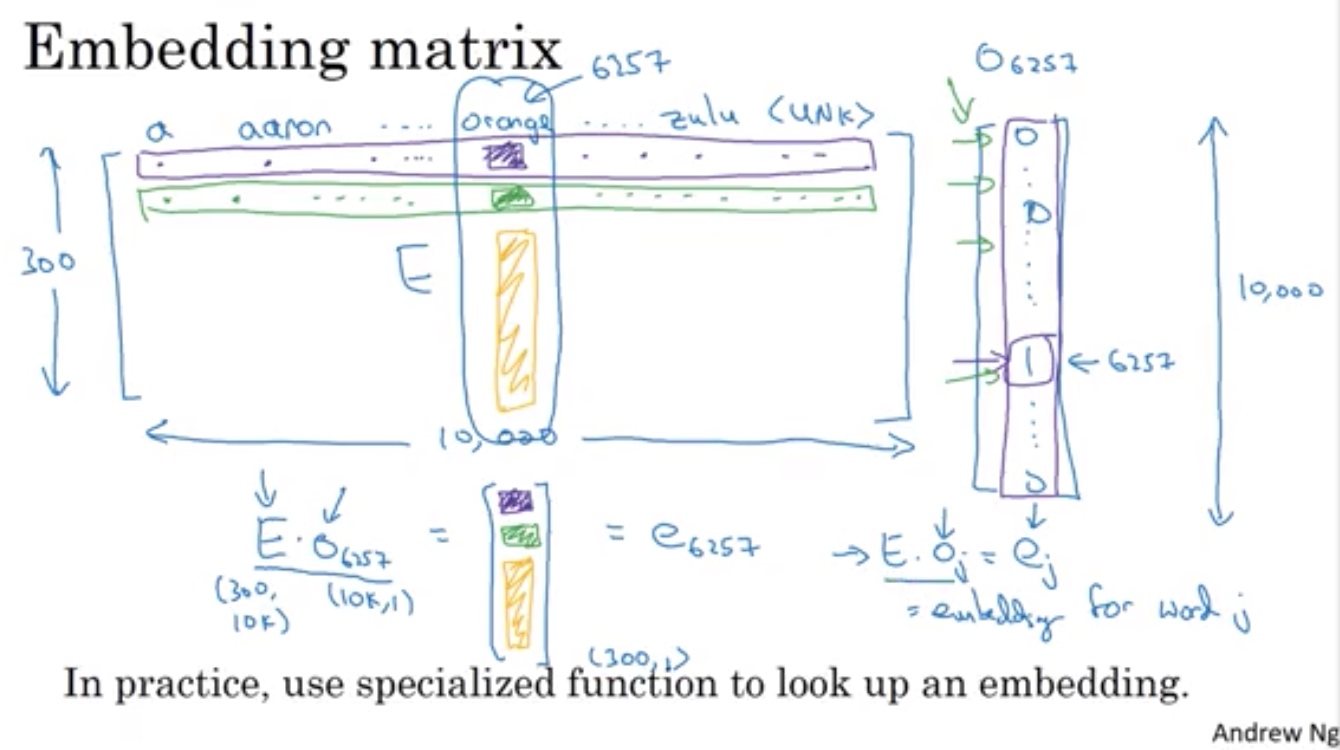
构建词向量 word vec

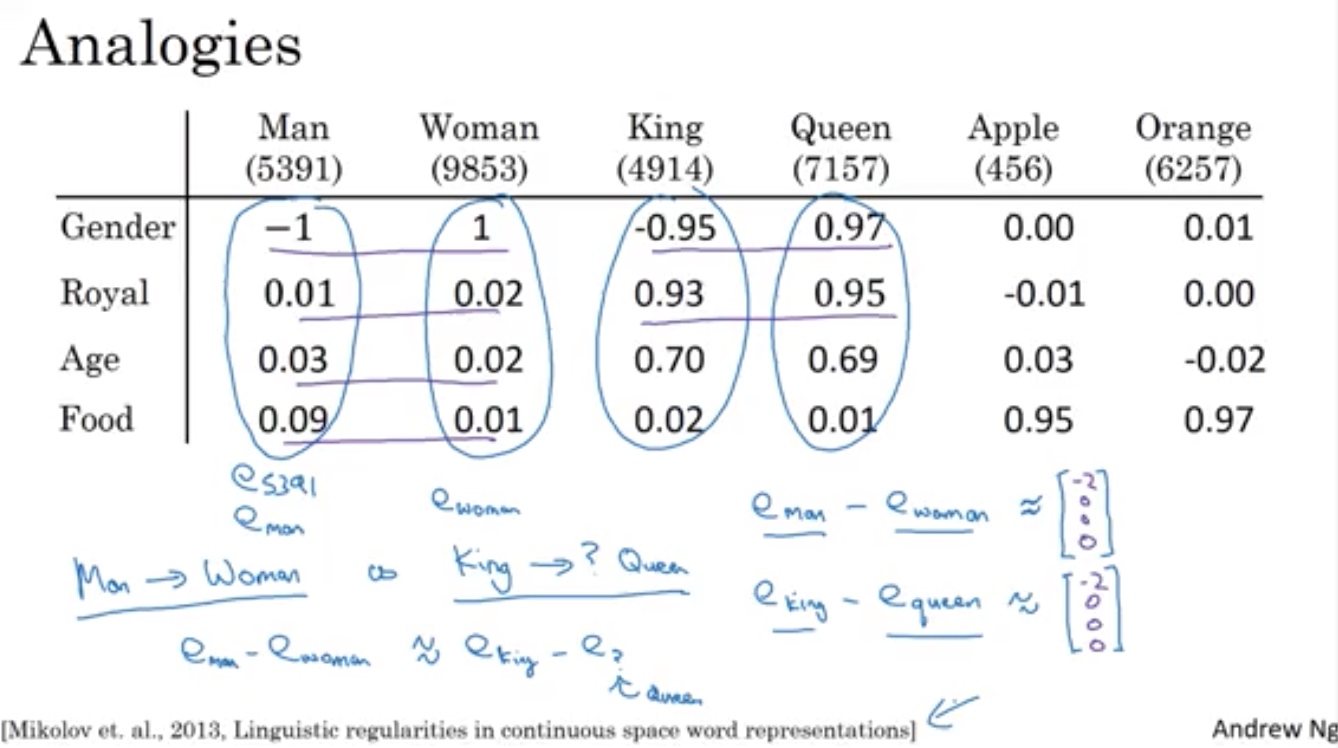
man - women
king - queen
词向量库 E 泛化negligible不错
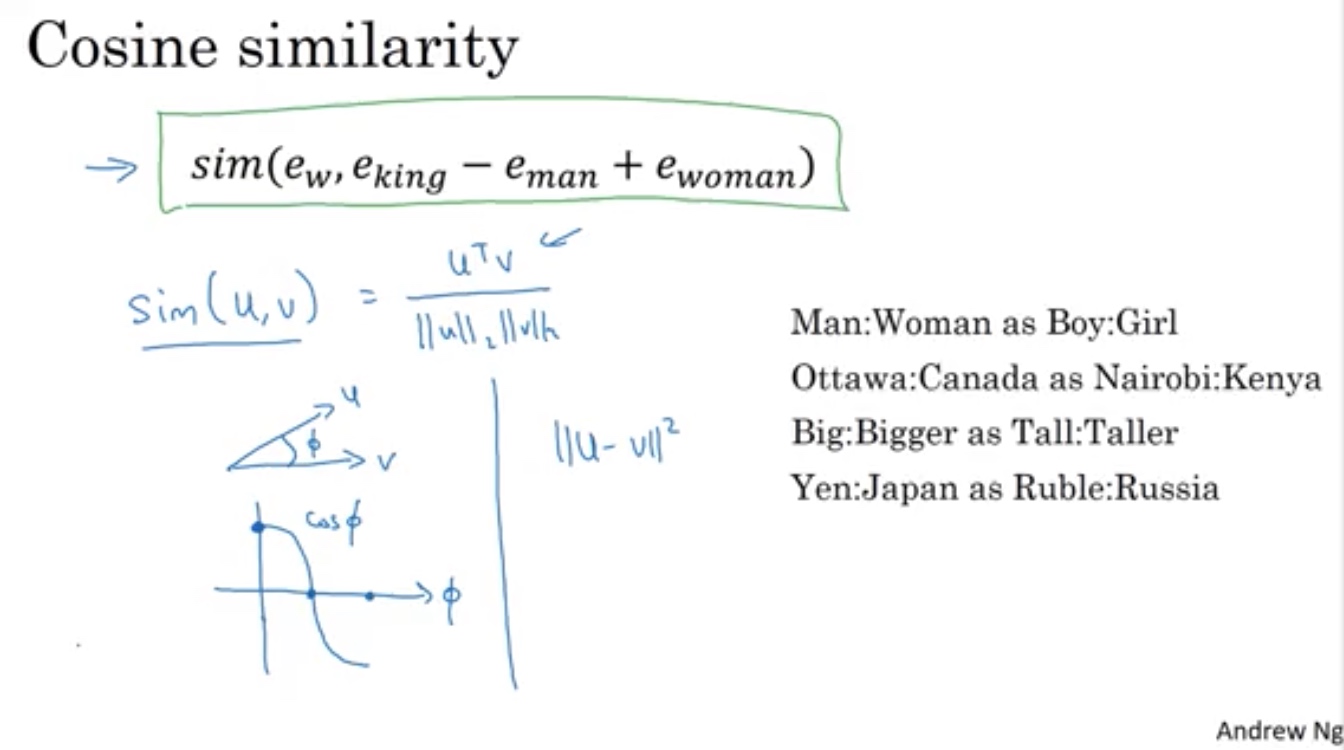
相似度函数
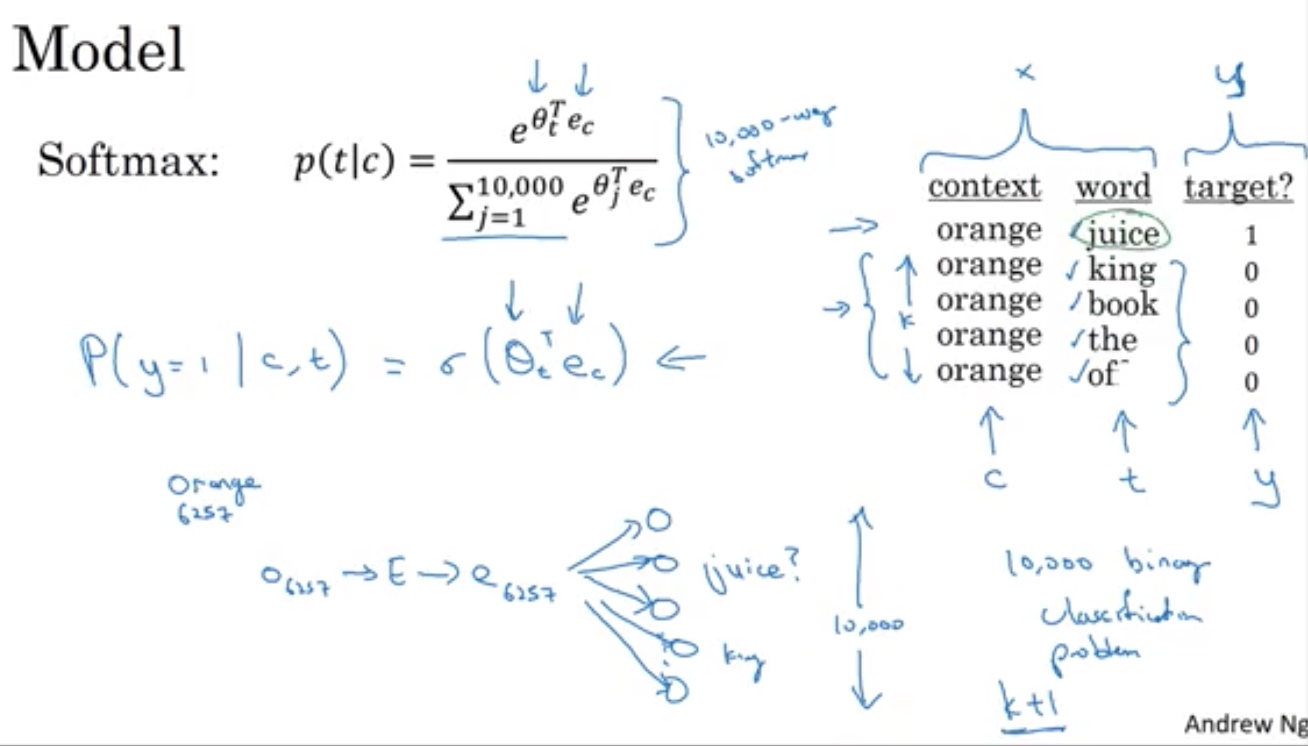
应对大词典的softmax运算慢问题,构建二叉树数据结构,常用的放上面,不用每次计算概率

平衡P(t|c),避免the of 等 词频繁运算出现
负采样法Negative sampling
Glove global vectors for word representation
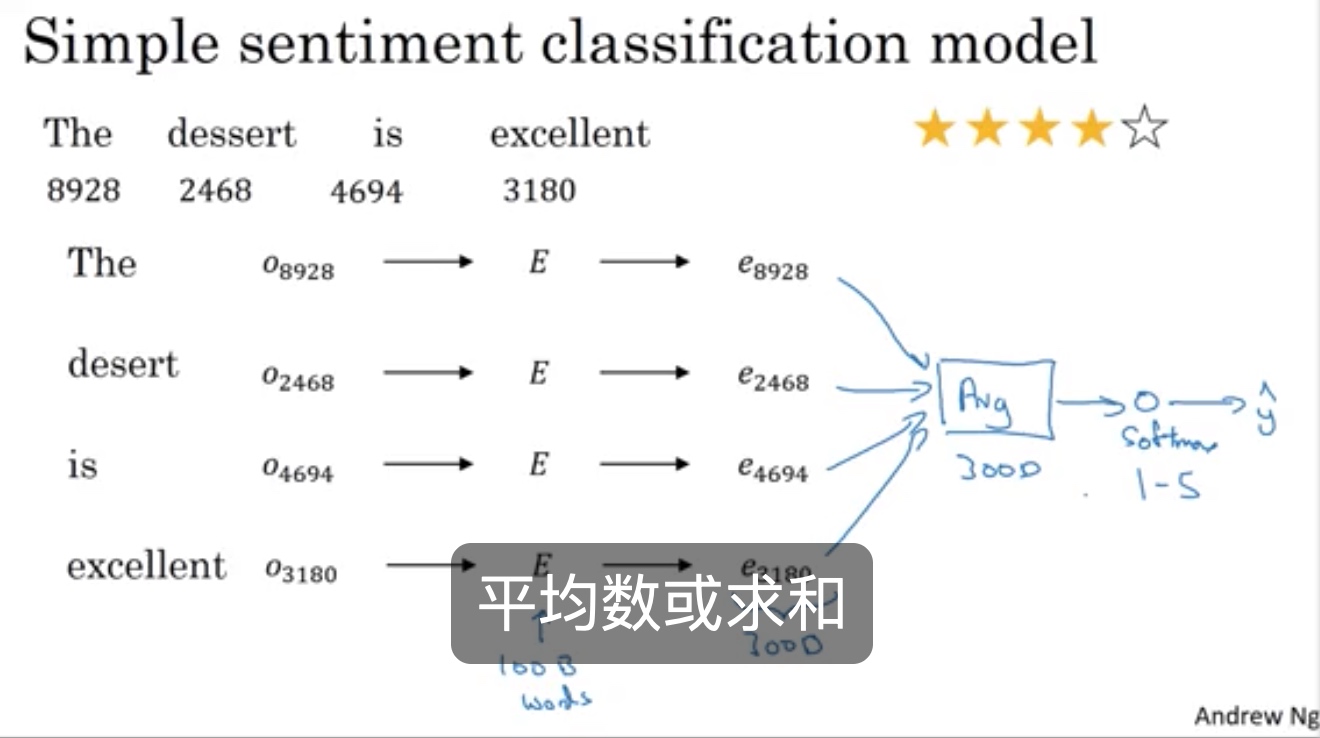
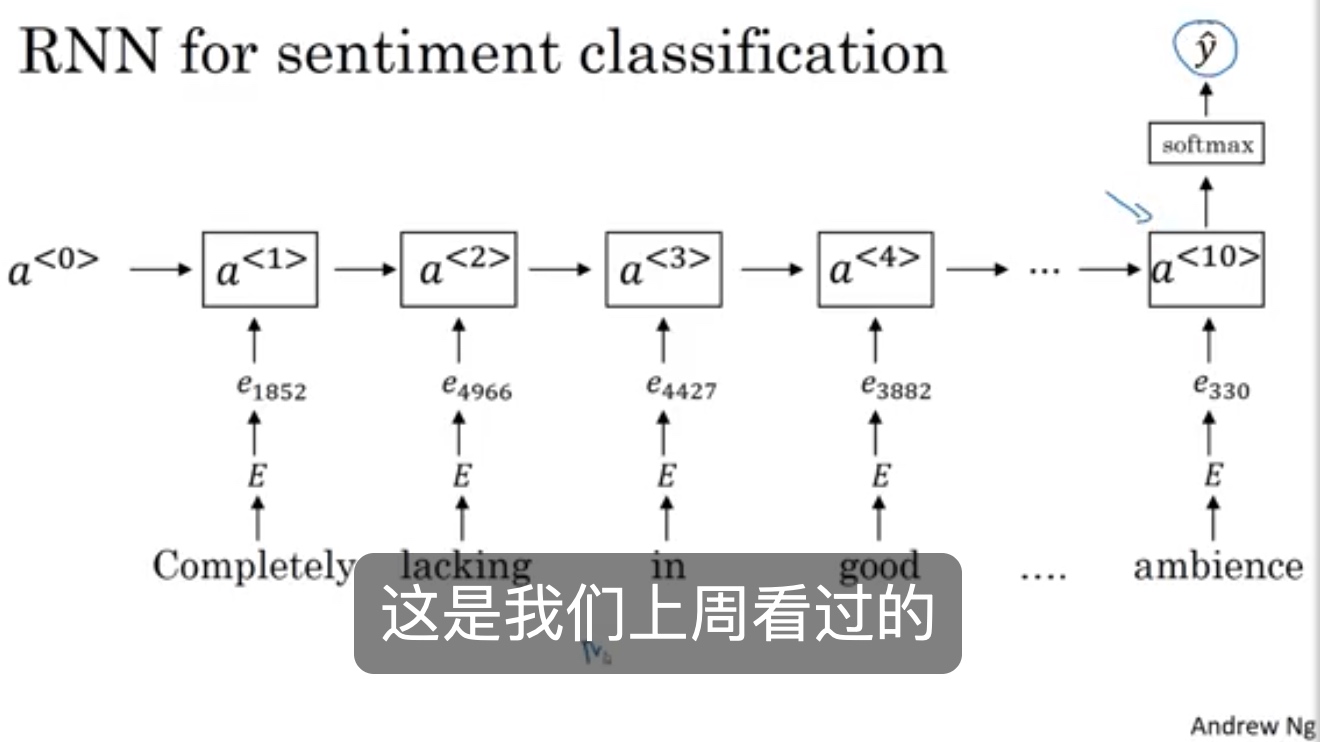
情感分类sentiment classification
问题描述:

平均数 词向量分类
词编码向量的偏差消除

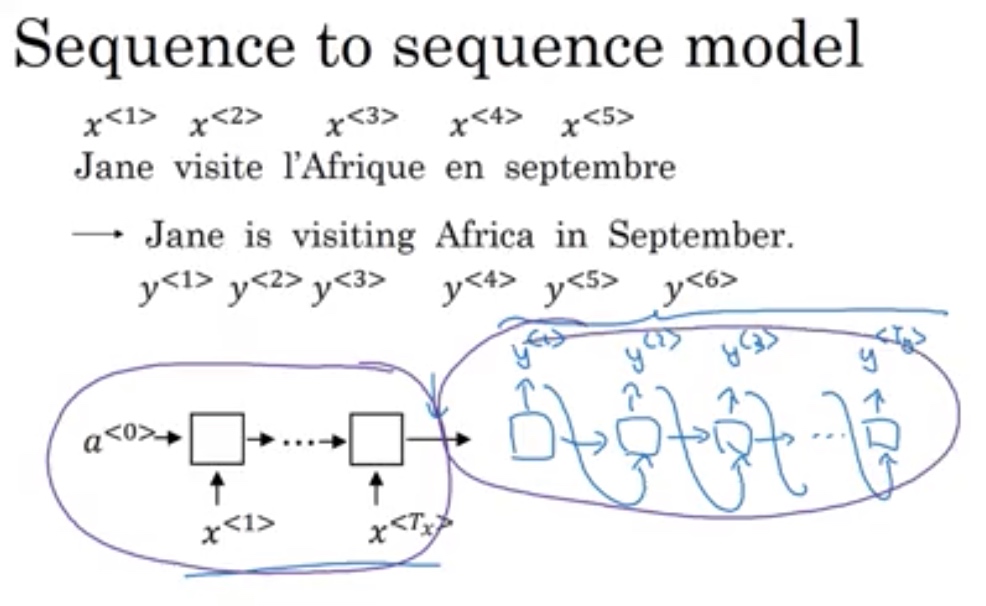
变输入输出架构
主要应用在语言识别和机器翻译
架构:编码器 + 解码器各用了一个
Beam search
对于翻译算法来说,一次得到整个句子的最优概率对应翻译,搜索量太大,而贪心算法,每次只选一个,随机误差太大,效果差,因此引入Beam search 算法
每次考虑2步,第一步选B个,第二部全选n个,从B x n个中寻优
概率估计值数值稳定性
- 概率(in [0,1]),连乘,数值稳定性差
- 转化为log函数求和,越加越小
- 平均值,比求和好
- 用(frac{1}{T_y^alpha})

Error analysis

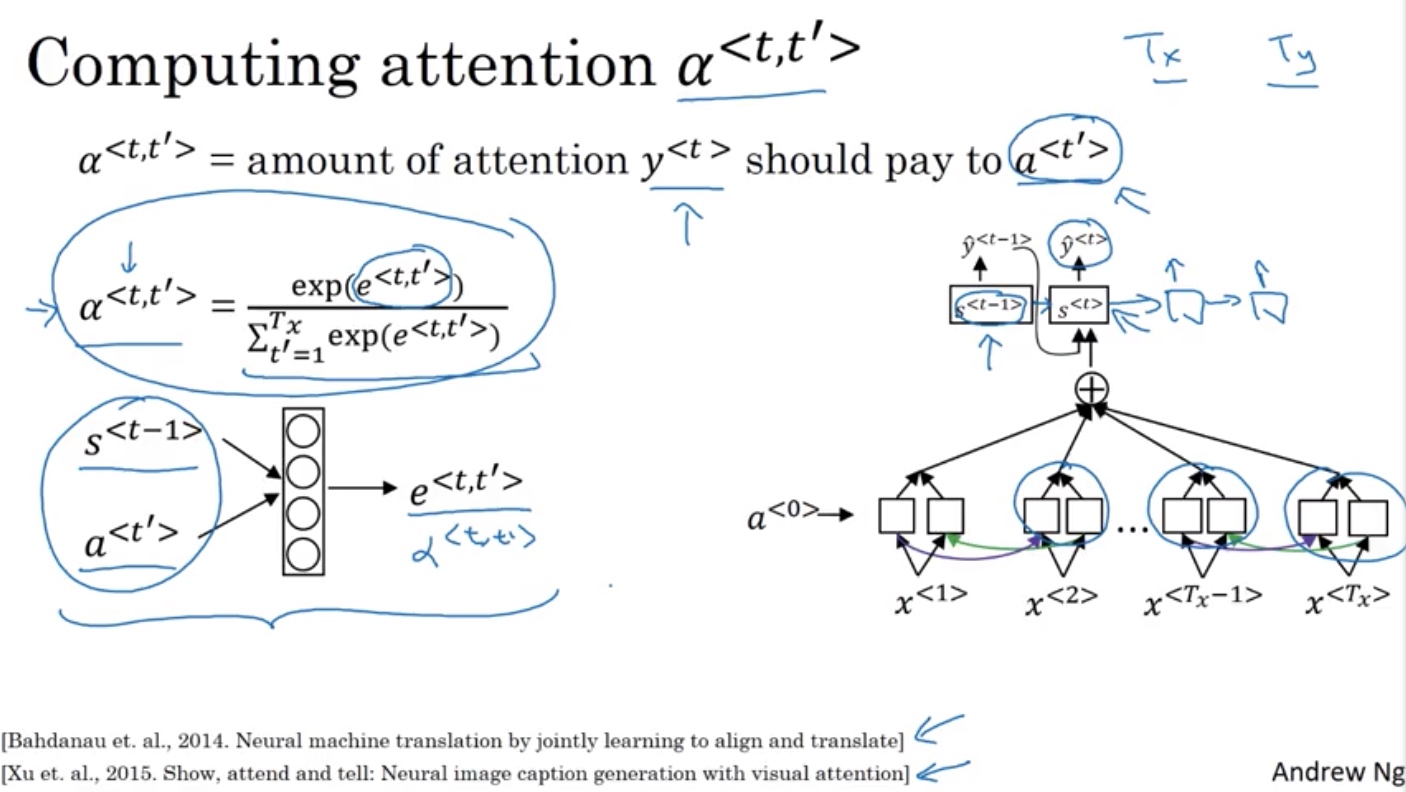
注意力集中 Attention model intution
- 长序列模型的问题
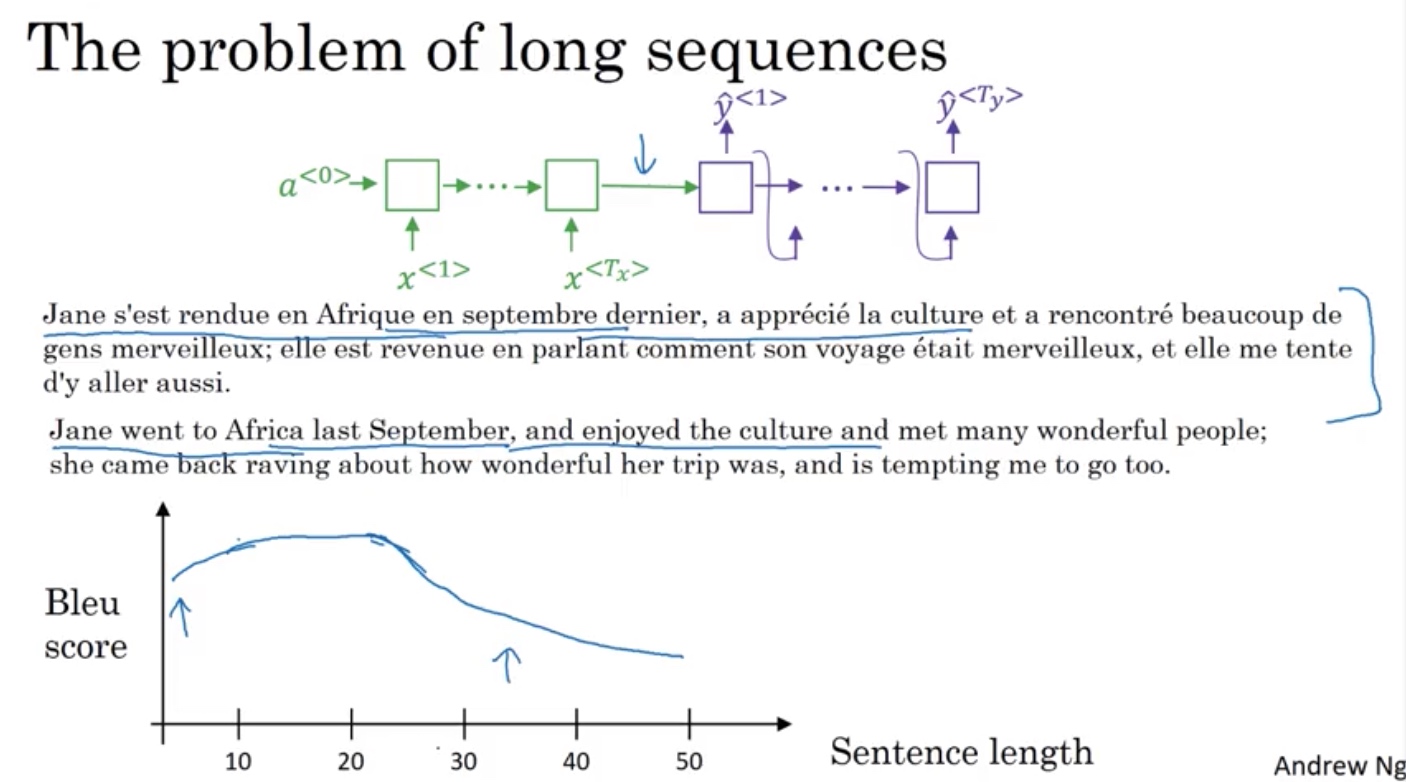 without 注意力模型,(y^{<t>}) 取决于 (a^{<t>})
without 注意力模型,(y^{<t>}) 取决于 (a^{<t>})
带有注意力的系统,将权重,分散给其他的几个激活值(a^{<t>})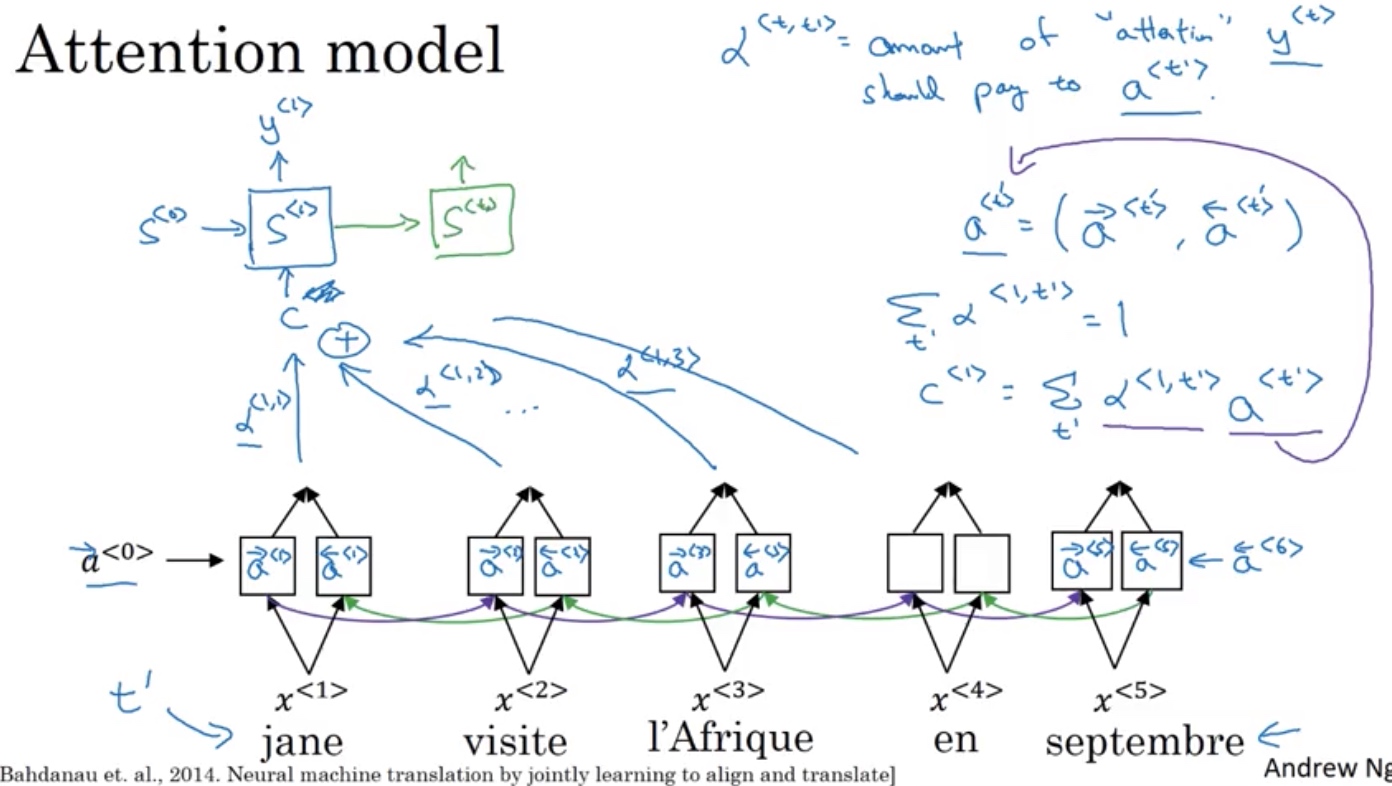
注意力权重计算
用softmax保证和为1
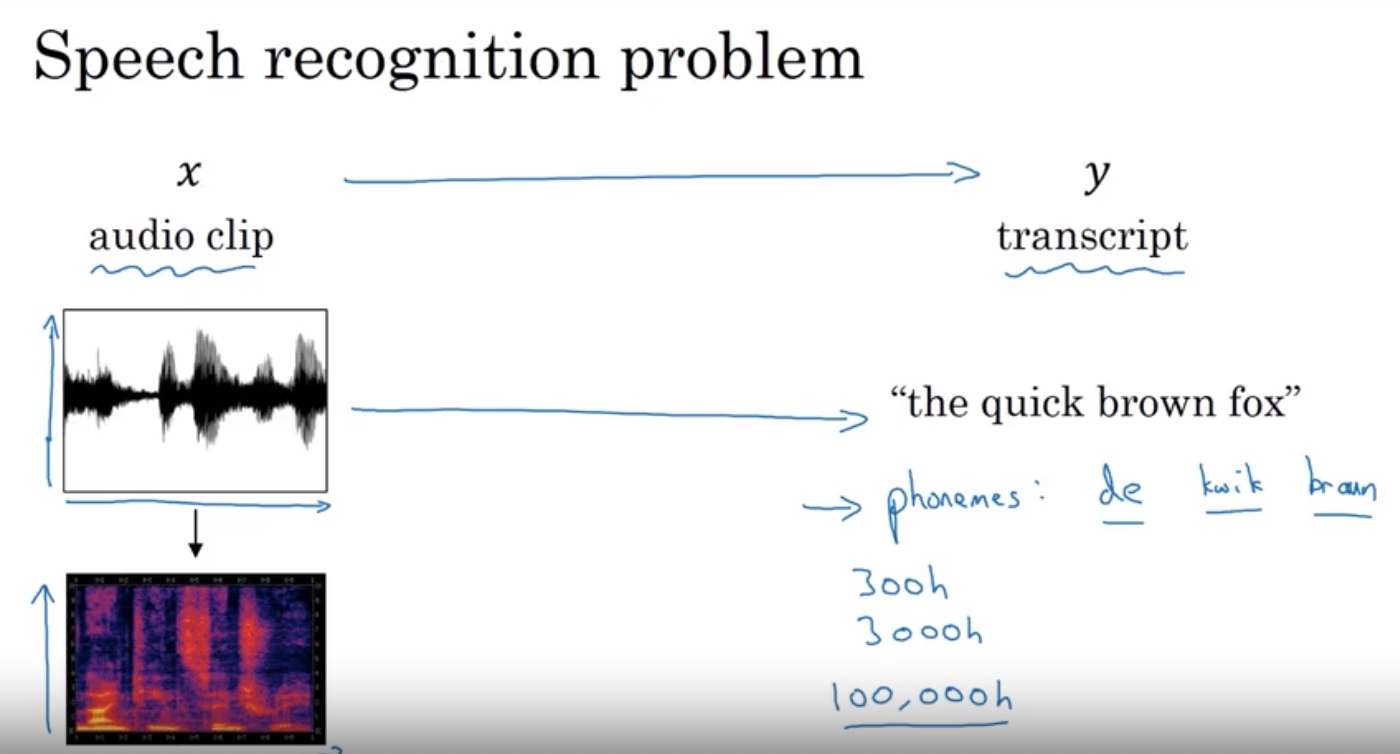
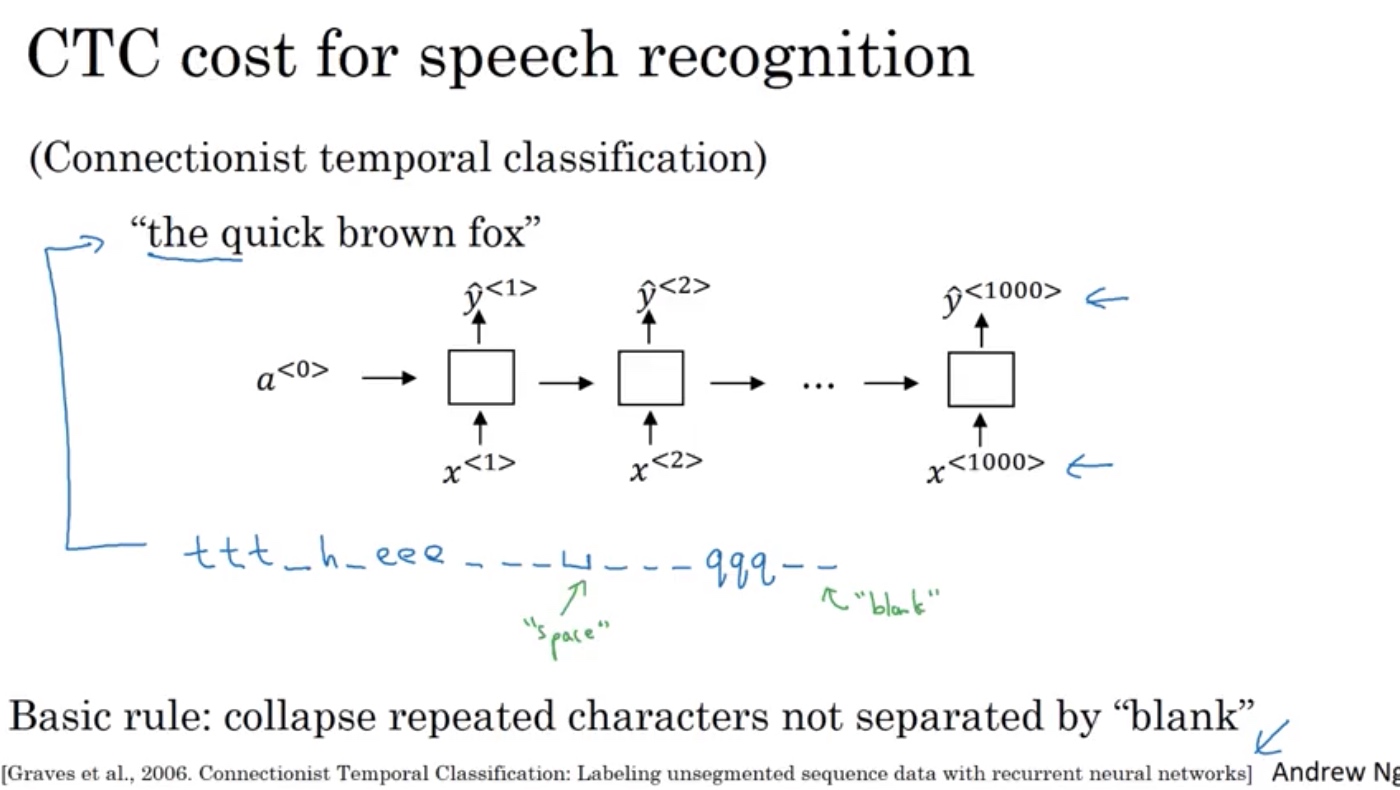
语音识别
声音预处理,频谱