本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
最近在学习内核模块的框架,这里做个总结,知识太多了。
分段和分页
先看一幅图

也就是我们实际中编码时遇到的内存地址并不是对应于实际内存上的地址,我们编码中使用的地址是一个逻辑地址,会通过分段和分页这两个机制把它转为物理地址。而由于linux使用的分段机制有限,可以认为,linux下的逻辑地址=线性地址。也就是,我们编码使用的是线性地址,之后只需要经过一个分页机制就可以把这个地址转为物理地址了。所以我们更重要的可能是去说明一下linux的分页模型。
系统会将整个物理内存分为多个页框,每个页框大小一般是4K(硬件允许的扩展分页(PSE)情况下也可设置为4M,不过linux并不使用PSE,而可能使用PAE),也就是如果我们有1GB的物理内存,系统就会将这个物理内存分为262144个页框。当我们提供一个线性地址时,系统就会通过分页机制将这个线性地址转换为对应于某个物理页中的某个内存地址。下图是linux的分页模型
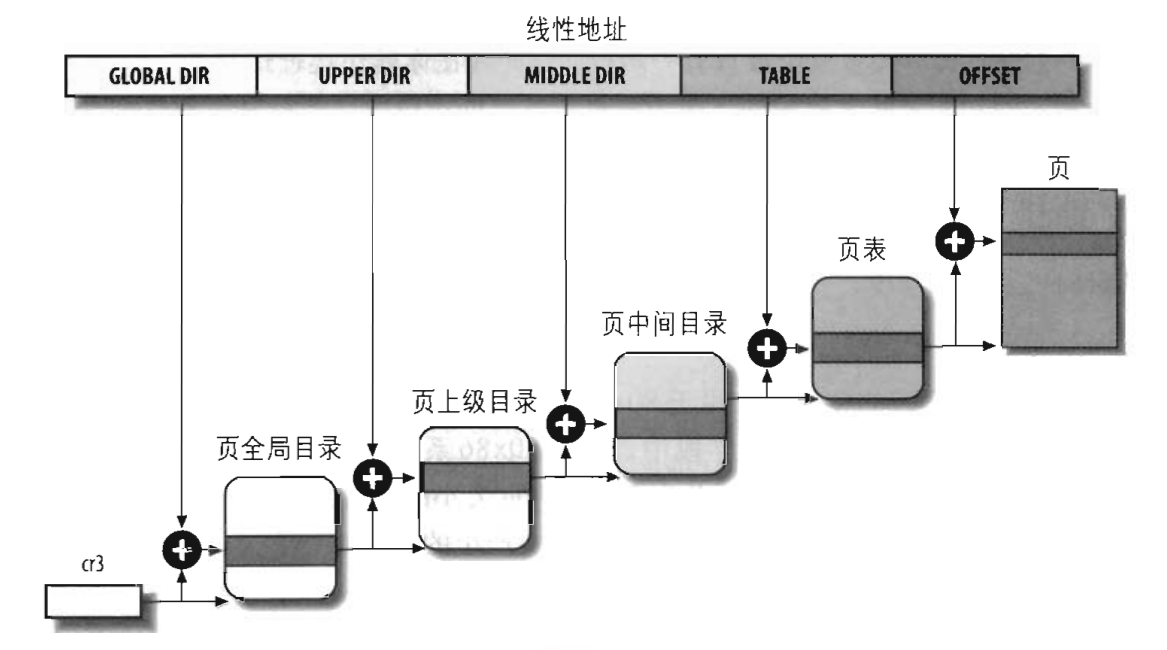
linux采用四级分页模型,这四种页表是:页全局目录(PGD)、页上级目录(PUD)、页中间目录(PMD)、页表(PTE)。这里的所有页全局目录、页上级目录、页中间目录、页表,它们的大小都是一个页。linux下各个硬件上并不一定都是使用四级目录的,当使用于没有启动物理地址扩展(PAE)的32位系统上时,只使用二级页表,linux会把页上级目录和页中间目录置空。而在启用了物理地址扩展的32位系统上时,linux使用的是三级页表,页上级目录被置空。而在64位系统上,linux根据硬件的情况会选择三级页表或者四级页表。这个整个由线性地址转换到物理地址的过程,是由CPU自动进行的。
每个进程都有它自己的页全局目录,当进程运行时,系统会将该进程的页全局目录基地址保存到cr3寄存器中;而当进程被换出时,会将这个cr3保存的页全局目录地址保存到进程描述符中。之后我们还会介绍一个cr2寄存器,用于缺页异常处理的。当进程运行时,它使用的是它自己的一套页表,当它通过系统调用或陷入内核态时,使用的是内核页表,实际上,对于所有的进程页表来说,它们的线性地址0xC0000000以上所涉及到的页表都是主内核页全局目录(保存在init_mm.pgd),它们的内容等于主内核页全局目录的相应表项,这样就实现了所有进程的进程空间相互隔离,但是内核空间相互共享的情况。当某个进程修改了内核页表的一些映射情况后,系统只会相应的修改主内核页全局目录中的表项(只能修改高端内存中非连续内存区的映射),当其他进程访问这些线性地址时,会出现缺页异常,然后修改该进程的页表项重新映射该地址。
因为说到每个进程都有它自己的页全局目录,如果有100个进程,内存中就要保存100个进程的整个页表集,看起来会耗费相当多的内存。实际上,只有进程使用到的情况下系统才会分配给进程一条路径,比如我们要求访问一个线性地址,但是这个地址可能对应的页上级目录、页中间目录、页表和页都不存在的,这时系统会产生一个缺页异常,在缺页异常处理中再给进程的这个线性地址分配页上级目录、页中间目录、页表和页所需的物理页框。
地址空间
一个线性地址经过分页机制转为一个对应的物理地址,我们称之为映射,比如我们的一个线性地址0x00000001经过分页机制处理后,对应的物理地址可能是0xffffff01。
在linux系统中分两个地址空间,一个是进程地址空间,一个是内核地址空间。对于每个进程来说,他们都有自己的大小为3G的进程地址空间,这些进程地址空间是相互隔离的,也就是进程A的0x00000001线性地址和进程B的0x00000001线性地址并不是同一个地址,进程A也不能通过自己的进程空间直接访问进程B的进程地址空间。而当线性地址大于3G时(也就是0xC0000000),这里的线性地址属于内核空间,内核地址空间的大小为1G,地址从0xC0000000到0xFFFFFFFF。在内核地址空间中,内核会把前896MB的线性地址直接与物理地址的前896MB进行映射,也就是说,内核地址空间的线性地址0xC0000001所对应的物理地址为0x00000001,它们之间相差一个0xC0000000。
linux内核会将物理内存分为3个管理区,分别是:
- ZONE_DMA:包含0MB~16MB之间的内存页框,可以由老式基于ISA的设备通过DMA使用,直接映射到内核的地址空间。
- ZONE_NORMAL:包含16MB~896MB之间的内存页框,常规页框,直接映射到内核的地址空间。
- ZONE_HIGHMEM:包含896MB以上的内存页框,不进行直接映射,可以通过永久映射和临时映射进行这部分内存页框的访问。
整个结构如下图
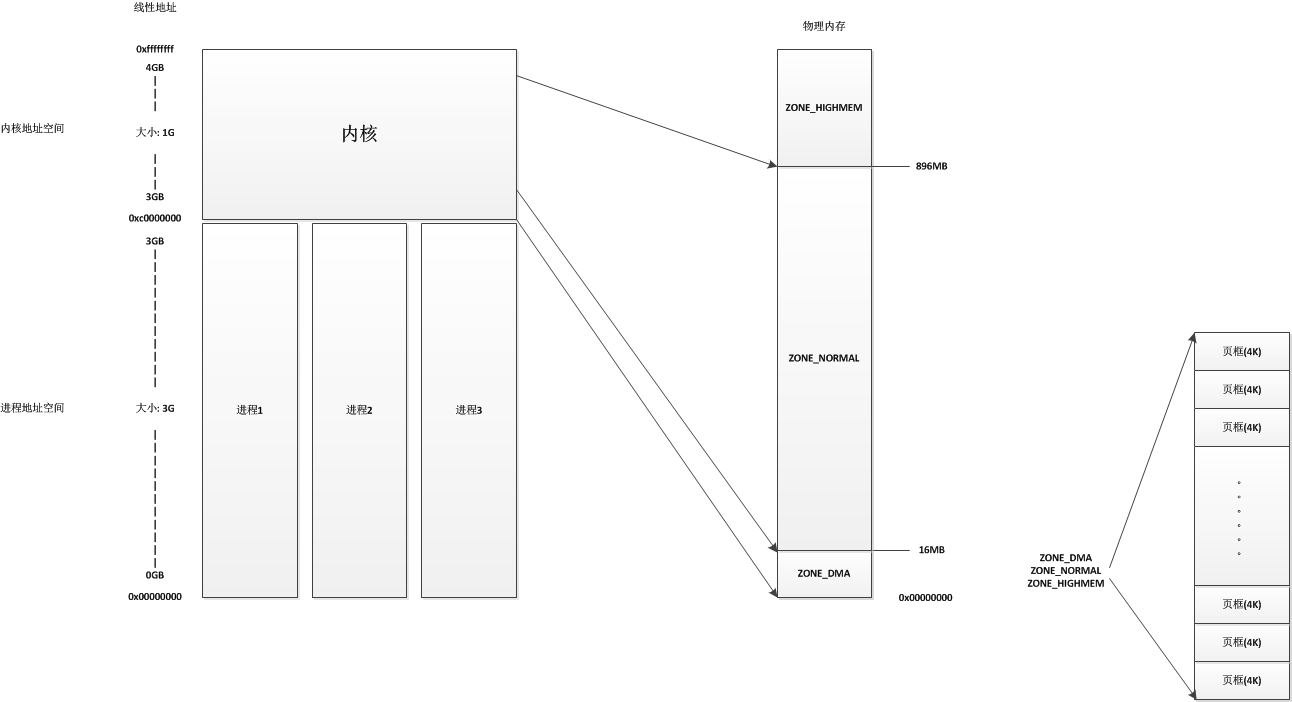
对于ZONE_DMA和ZONE_NORMAL这两个管理区,内核地址都是进行直接映射,只有ZONE_HIGHMEM管理区系统在默认情况下是不进行直接映射的,只有在需要使用的时候进行映射(临时映射或者永久映射)。
结点和管理区描述符
为了用于NUMA架构,使用了node用来描述一个地方的内存。对于我们PC来说,一台PC就是一个node。node用struct pglist_data结构表示:
/* 内存结点描述符,所有的结点描述符保存在 struct pglist_data *node_data[MAX_NUMNODES] 中 */ typedef struct pglist_data { /* 管理区描述符的数组 */ struct zone node_zones[MAX_NR_ZONES]; /* 页分配器使用的zonelist数据结构的数组,将所有结点的管理区按一定的关联链接成一个链表,分配内存时会按照此链表的顺序进行分配 */ struct zonelist node_zonelists[MAX_ZONELISTS]; /* 结点中管理区的个数 */ int nr_zones; #ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */ /* 结点中页描述符的数组,包含了此结点中所有页框描述符,实际分配是是一个指针数组 */ struct page *node_mem_map; #ifdef CONFIG_MEMCG /* 用于资源限制机制 */ struct page_cgroup *node_page_cgroup; #endif #endif #ifndef CONFIG_NO_BOOTMEM /* 用在内核初始化阶段 */ struct bootmem_data *bdata; #endif #ifdef CONFIG_MEMORY_HOTPLUG /* 自旋锁 */ spinlock_t node_size_lock; #endif /* 结点中第一个页框的下标,在numa系统中,页框会有两个序号,所有页框的一个序号,还有就是在此结点中的一个序号 * 比如结点2中的页框1,它在结点2中的序号是1,但是在所有页框中的序号是1001,这个变量就是保存这个结点首页框的序号1000,用于方便转换 */ unsigned long node_start_pfn; /* 内存结点的大小,不包括洞(以页框为单位) */ unsigned long node_present_pages; /* 结点的大小,包括洞(以页框为单位) */ unsigned long node_spanned_pages; /* 结点标识符 */ int node_id; /* kswaped页换出守护进程使用的等待队列 */ wait_queue_head_t kswapd_wait; wait_queue_head_t pfmemalloc_wait; /* 指针指向kswapd内核线程的进程描述符 */ struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() */ /* kswapd将要创建的空闲块大小取对数的值 */ int kswapd_max_order; enum zone_type classzone_idx; #ifdef CONFIG_NUMA_BALANCING /* 以下用于NUMA的负载均衡 */ /* Lock serializing the migrate rate limiting window */ spinlock_t numabalancing_migrate_lock; /* Rate limiting time interval */ unsigned long numabalancing_migrate_next_window; /* Number of pages migrated during the rate limiting time interval */ unsigned long numabalancing_migrate_nr_pages; #endif } pg_data_t;
系统中所有的结点描述符都保存在node_data这个数组中。在pg_data_t这个结点描述符中,node_zones数组中保存了这个结点中所有的管理区描述符,虽然系统将物理内存分为三个区,但是在逻辑上,系统分为了四个管理区,多出的一个是ZONE_MOVABLE,这个区是一个虚拟的管理区,它并没有对应于内存的某个区域,它的主要目的就是为了避免内存碎片化,它的内存要么全部来自ZONE_HIGHMEM区,要么全部来自ZONE_NORMAL区。这些我们在后面的初始化函数中将会看到。
每个结点都有一个内核线程kswapd,它的作用就是将进程或内核持有的,但是不常用的页交换到磁盘上,以腾出更多可用内存。
我们再看看管理区描述符:
/* 内存管理区描述符 */ struct zone { /* Read-mostly fields */ /* zone watermarks, access with *_wmark_pages(zone) macros */ /* 包括pages_min,pages_low,pages_high * pages_min: 管理区中保留页的数目 * pages_low: 回收页框使用的下界,同时也被管理区分配器作为阀值使用,一般这个数字是pages_min的5/4 * pages_high: 回收页框使用的上界,同时也被管理区分配器作为阀值使用,一般这个数字是pages_min的3/2 */ unsigned long watermark[NR_WMARK]; /* 指明在处理内存不足的临界情况下管理区必须保留的页框数目,同时也用于在中断或临界区发出的原子内存分配请求(就是禁止阻塞的内存分配请求) */ long lowmem_reserve[MAX_NR_ZONES]; #ifdef CONFIG_NUMA int node; #endif /* * The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on * this zone's LRU. Maintained by the pageout code. */ unsigned int inactive_ratio; /* 指向此管理区属于的结点 */ struct pglist_data *zone_pgdat; /* 实现每CPU页框高速缓存,里面包含每个CPU的单页框的链表 */ struct per_cpu_pageset __percpu *pageset; /* * This is a per-zone reserve of pages that should not be * considered dirtyable memory. */ unsigned long dirty_balance_reserve; #ifndef CONFIG_SPARSEMEM /* * Flags for a pageblock_nr_pages block. See pageblock-flags.h. * In SPARSEMEM, this map is stored in struct mem_section */ unsigned long *pageblock_flags; #endif /* CONFIG_SPARSEMEM */ #ifdef CONFIG_NUMA /* * zone reclaim becomes active if more unmapped pages exist. */ unsigned long min_unmapped_pages; unsigned long min_slab_pages; #endif /* CONFIG_NUMA */ /* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */ /* 管理区第一个页框下标 */ unsigned long zone_start_pfn; /* 所有正常情况下可用的页,总页数(不包括洞)减去保留的页数 */ unsigned long managed_pages; /* 管理区总大小(页为单位),包括洞 */ unsigned long spanned_pages; /* 管理区总大小(页为单位),不包括洞 */ unsigned long present_pages; /* 指向管理区的传统名称,"DMA" "NORMAL" "HighMem" */ const char *name; /* 对应于伙伴系统中MIGRATE_RESEVE链的页块的数量 */ int nr_migrate_reserve_block; #ifdef CONFIG_MEMORY_ISOLATION /* * Number of isolated pageblock. It is used to solve incorrect * freepage counting problem due to racy retrieving migratetype * of pageblock. Protected by zone->lock. */ /* 在内存隔离中表示隔离的页框块数量 */ unsigned long nr_isolate_pageblock; #endif #ifdef CONFIG_MEMORY_HOTPLUG /* see spanned/present_pages for more description */ seqlock_t span_seqlock; #endif /* 进程等待队列的hash表,这些进程在等待管理区中的某页 */ wait_queue_head_t *wait_table; /* 等待队列散列表的大小 */ unsigned long wait_table_hash_nr_entries; /* 等待队列散列表数组大小 */ unsigned long wait_table_bits; ZONE_PADDING(_pad1_) /* Write-intensive fields used from the page allocator */ /* 保护该描述符的自旋锁 */ spinlock_t lock; /* free areas of different sizes */ /* 标识出管理区中的空闲页框块,用于伙伴系统 */ /* MAX_ORDER为11,分别代表包含大小为1,2,4,8,16,32,64,128,256,512,1024个连续页框的链表 */ struct free_area free_area[MAX_ORDER]; /* zone flags, see below */ /* 管理区标识 */ unsigned long flags; ZONE_PADDING(_pad2_) /* Fields commonly accessed by the page reclaim scanner */ /* 活动及非活动链表使用的自旋锁 */ spinlock_t lru_lock; struct lruvec lruvec; /* Evictions & activations on the inactive file list */ atomic_long_t inactive_age; /* * When free pages are below this point, additional steps are taken * when reading the number of free pages to avoid per-cpu counter * drift allowing watermarks to be breached */ unsigned long percpu_drift_mark; #if defined CONFIG_COMPACTION || defined CONFIG_CMA /* pfn where compaction free scanner should start */ unsigned long compact_cached_free_pfn; /* pfn where async and sync compaction migration scanner should start */ unsigned long compact_cached_migrate_pfn[2]; #endif #ifdef CONFIG_COMPACTION /* * On compaction failure, 1<<compact_defer_shift compactions * are skipped before trying again. The number attempted since * last failure is tracked with compact_considered. */ unsigned int compact_considered; unsigned int compact_defer_shift; int compact_order_failed; #endif #if defined CONFIG_COMPACTION || defined CONFIG_CMA /* Set to true when the PG_migrate_skip bits should be cleared */ bool compact_blockskip_flush; #endif ZONE_PADDING(_pad3_) /* 管理区的一些统计数据 */ atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; } ____cacheline_internodealigned_in_smp;
此管理区描述符中的实际把所有属于该管理区的页框保存在两个地方:struct free_area free_area[MAX_ORDER]和struct per_cpu_pageset __percpu * pageset。free_area是这个管理区的伙伴系统,而pageset是这个区的每CPU页框高速缓存。对管理区的理解需要结合伙伴系统和每CPU页框高速缓存
管理区页框分配器(管理所有物理内存页框)
ZONE_NORMAL和ZONE_DMA的地址直接映射到了内核地址空间,但是也不代表内核的代码可以随心所欲的通过线性地址直接访问物理地址。内核通过一个管理区页框分配器管理着物理内存上所有的页框,在管理区分配器里的核心系统就是伙伴系统和每CPU页框高速缓存(不是硬件上的高速缓存,只是名称一样)。在linux系统中,管理区页框分配器管理着所有物理内存,无论你是内核还是进程,需要将一些内存占为己有时,都需要请求管理区页框分配器,这时才会分配给你应该获得的物理内存页框。当你所拥有的页框不再使用时,你必须释放这些页框,让这些页框回到管理区页框分配器当中。特别的,对于高端内存,即使从管理区页框分配器中获得了相应的页框,我们还需要进行映射才能够使用。
有时候目标管理区不一定有足够的页框去满足分配,这时候系统会从另外两个管理区中获取要求的页框,但这是按照一定规则去执行的,如下:
- 如果要求从DMA区中获取,就只能从ZONE_DMA区中获取。
- 如果没有规定从哪个区获取,就按照顺序从 ZONE_NORMAL -> ZONE_DMA 获取。
- 如果规定从HIGHMEM区获取,就按照顺序从 ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA 获取。
注意系统是不允许在一次分配中从不同的两个管理区获取页框的,并且当请求多个页框时,从伙伴系统中分配给目标的页框是连续的,并且请求的页数必须是2的次方个数。
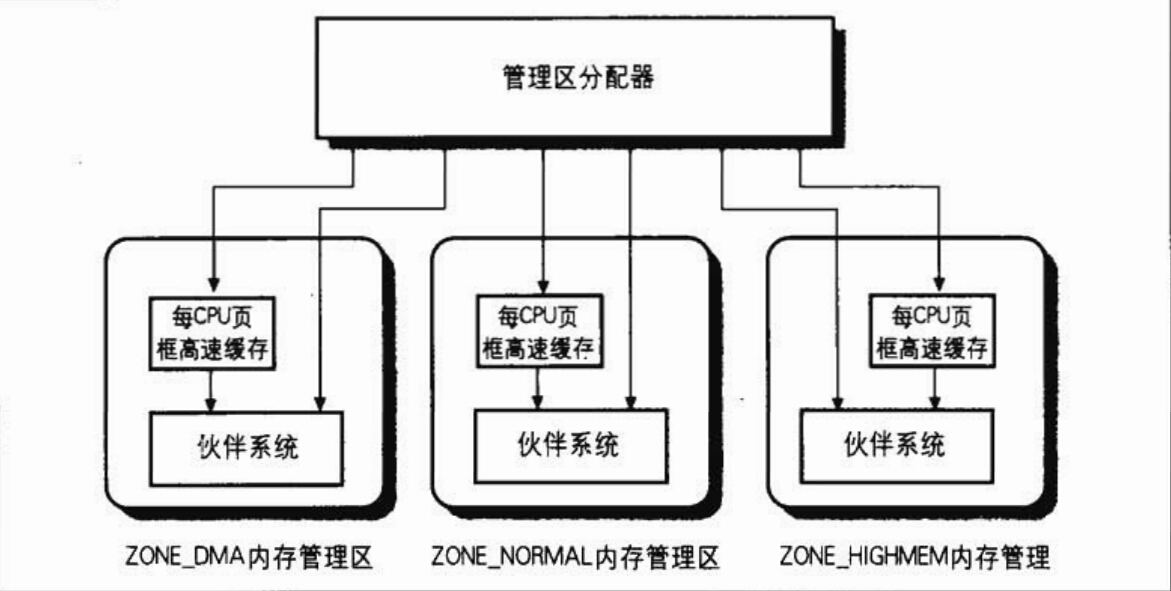
管理区分配器主要做的事情就是将页框通过伙伴系统或者每CPU页框高速缓存分配出去,这里涉及到三个结构,页描述符,伙伴系统,每CPU高速缓存。
我们先说说页描述符,页描述符实际上并不专属于描述页框,它还用于描述一个SLAB分配器和SLUB分配器,这个之后再说,我们先说关于页的:
/* 页描述符,描述一个页框,也会用于描述一个SLAB,相当于同时是页描述符,也是SLAB描述符 */ struct page { /* First double word block */ /* 用于页描述符,一组标志(如PG_locked、PG_error),也对页框所在的管理区和node进行编号 */ unsigned long flags; /* Atomic flags, some possibly * updated asynchronously */ union { /* 用于页描述符,当页被插入页高速缓存中时使用,或者当页属于匿名区时使用 */ struct address_space *mapping; /* 用于SLAB描述符,用于执行第一个对象的地址 */ void *s_mem; /* slab first object */ }; /* Second double word */ struct { union { /* 作为不同的含义被几种内核成分使用。例如,它在页磁盘映像或匿名区中标识存放在页框中的数据的位置,或者它存放一个换出页标识符 */ pgoff_t index; /* Our offset within mapping. */ /* 用于SLAB描述符,指向第一个空闲对象地址 */ void *freelist; /* 当管理区页框分配器压力过大时,设置这个标志就确保这个页框专门用于系统释放其他页框时使用 */ bool pfmemalloc; }; union { #if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE) /* SLUB使用 */ unsigned long counters; #else /* SLUB使用 */ unsigned counters; #endif struct { union { /* 页框中的页表项计数,如果没有为-1,如果为PAGE_BUDDY_MAPCOUNT_VALUE(-128),说明此页及其后的一共2的private次方个数页框处于伙伴系统中,正在使用时应该是0 */ atomic_t _mapcount; struct { /* SLUB使用 */ unsigned inuse:16; unsigned objects:15; unsigned frozen:1; }; int units; /* SLOB */ }; /* 页框的引用计数,如果为-1,则此页框空闲,并可分配给任一进程或内核;如果大于或等于0,则说明页框被分配给了一个或多个进程,或用于存放内核数据。page_count()返回_count加1的值,也就是该页的使用者数目 */ atomic_t _count; /* Usage count, see below. */ }; /* 用于SLAB描述符 */ unsigned int active; /* SLAB */ }; }; /* Third double word block */ union { /* 包含到页的最近最少使用(LRU)双向链表的指针,用于插入伙伴系统的空闲链表中,只有块中头页框要被插入 */ struct list_head lru;
/* SLAB使用 */ struct { /* slub per cpu partial pages */ struct page *next; /* Next partial slab */ #ifdef CONFIG_64BIT int pages; /* Nr of partial slabs left */ int pobjects; /* Approximate # of objects */ #else short int pages; short int pobjects; #endif }; struct slab *slab_page; /* slab fields */ struct rcu_head rcu_head;
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS pgtable_t pmd_huge_pte; /* protected by page->ptl */ #endif }; /* Remainder is not double word aligned */ union { /* 可用于正在使用页的内核成分(例如: 在缓冲页的情况下它是一个缓冲器头指针,如果页是空闲的,则该字段由伙伴系统使用,在给伙伴系统使用时,表明的是块的2的次方数,只有块的第一个页框会使用) */ unsigned long private; #if USE_SPLIT_PTE_PTLOCKS #if ALLOC_SPLIT_PTLOCKS spinlock_t *ptl; #else spinlock_t ptl; #endif #endif /* SLAB描述符使用,指向SLAB的高速缓存 */ struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */ struct page *first_page; /* Compound tail pages */ }; #if defined(WANT_PAGE_VIRTUAL) /* 此页框第一个物理地址对应的线性地址,如果是没有映射的高端内存的页框,则为空 */ void *virtual; #endif /* WANT_PAGE_VIRTUAL */ #ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS unsigned long debug_flags; /* Use atomic bitops on this */ #endif #ifdef CONFIG_KMEMCHECK void *shadow; #endif #ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS int _last_cpupid; #endif }
在struct page描述一个页框时,我们比较关注的成员变量有unsigned long flags、struct list_head lru和atomic_t _count。
- flags:包含有很多信息,包括此页框属于的node结点号,此页框属于的zone号和此页框的属性。
- lru:用于将此页描述符放入相应的链表,比如伙伴系统或者每CPU页框高速缓存。
- _count:代表页框的引用计数,-1代表此页框空闲,大于0代表此页框分配给了多少个进程使用(共享)。
linux为了防止内存中产生过多的碎片,一般把页的类型分为三种:
- 不可移动页:在内存中有固定位置,不能移动到其他地方。内核中使用的页大部分是属于这种类型。
- 可回收页:不能直接移动,但可以删除,页中的内容可以从某些源中重新生成。例如,页内容是映射到文件数据的页就属于这种类型。对于这种类型,在内存短缺(分配失败)时,会发起内存回收,将这类型页进行回写释放。
- 可移动页:可随意移动,用户空间的进程使用的没有映射具体磁盘文件的页就属于这种类型(比如堆、栈、shmem共享内存、匿名mmap共享内存),它们是通过进程页表映射的,把这些页复制到新位置时,只要更新进程页表就可以了。一般这些页是从高端内存管理区获取。
伙伴系统
伙伴系统的主要作用就是减少物理内存的外部碎片(SLAB/SLUB减少页框的内部碎片),它实际上是一个struct free_area的数组,数组长度是MAX_ORDER,也就是11,代表着每个数组元素中链表上保存的连续页框长度是2的order次方。free_area[0]中链表保存的是长度为1的页框,free_area[1]中链表上保存的是物理上连续的两个页框的首页框链表,free_area[2]中链表上保存的是物理上连续4个页框的首页框链表,free_area[10]中链表上保存的是物理上连续1024个页框的首页框链表,所以整个伙伴系统中将管理区中的页框分为连续的1,2,4,8,16,32,64,128,256,512,1024页框放入不同链表中保存起来。而因为伙伴系统中每个链表保存的页框都是连续的,所以只有第一个页框会加入到链表中,因为有order,也可以知道此页框之后的多少个页框是属于这一小块连续页框的。当需要在普通内存区申请4个页框大小的内存时,系统会到普通内存管理区的伙伴系统中的free_area[2]中的第一个链表结点,这个结点的页框及其之后3个页框都是空闲的,然后把首页框返回给申请者。
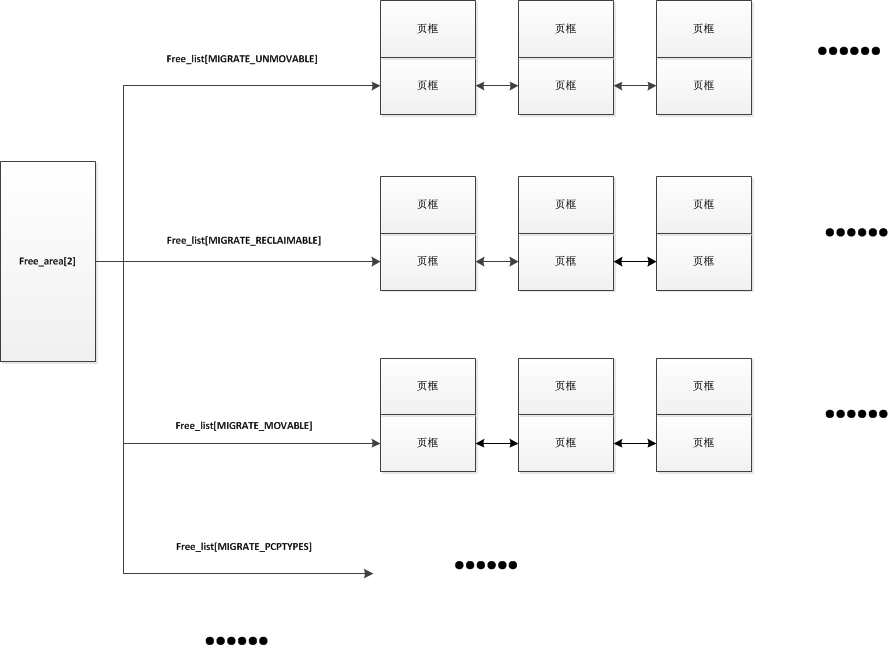
/* 伙伴系统的一个块,描述1,2,4,8,16,32,64,128,256,512或1024个连续页框的块 */ struct free_area { /* 指向这个块中所有空闲小块的第一个页描述符,这些小块会按照MIGRATE_TYPES类型存放在不同指针里 */ struct list_head free_list[MIGRATE_TYPES]; /* 空闲小块的个数 */ unsigned long nr_free; };
在伙伴系统中,因为页的分类关系,在每种长度相同的连续页框中又会分出多个不同类型的链表,如下,
enum { MIGRATE_UNMOVABLE, /* 不可移动页 */ MIGRATE_RECLAIMABLE, /* 可回收页 */ MIGRATE_MOVABLE, /* 可移动页 */ MIGRATE_PCPTYPES, /* 用来表示每CPU页框高速缓存的数据结构中的链表的可移动类型数目 */ MIGRATE_RESERVE = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* 不能从这个链表分配页框,因为这个链表专门用于NUMA结点移动物理内存页,将物理内存页移动到使用这个页最频繁的CPU */ #endif MIGRATE_TYPES };
保存连续2个页框的free_area[2]的结构如下:
在从伙伴系统中申请页框时,有可能会遇到一种情况,就是当前需求的连续页框链表上没有可用的空闲页框,这时后,伙伴系统会从下一级获取一个连续长度的页框块,将其拆分放入这级列表;当然在拥有者释放连续页框时伙伴系统也会适当地进行连续页框的合并,并放入下一级中。比如:我需要申请4个页框,但是长度为4个连续页框块链表没有空闲的页框块,伙伴系统会从连续8个页框块的链表获取一个,并将其拆分为两个连续4个页框块,放入连续4个页框块的链表中。释放时道理也一样,会检查释放的这几个页框的之前和之后的物理页框是否空闲,并且能否组成下一级长度的块。
每CPU页框高速缓存
每CPU页框高速缓存也是一个分配器,配合着伙伴系统进行使用,这个分配器是专门用于分配单个页框的,它维护一个单页框的双向链表,为什么需要这个分配器,原因主要有两点:
- 因为每个CPU都有自己的硬件高速缓存,当对一个页进行读取写入时,首先会把这个页装入硬件高速缓存,而如果进程对这个处于硬件高速缓存的页进行操作后立即释放掉,这个页有可能还保存在硬件高速缓存中,这样我另一个进程需要请求一个页并立即写入数据的话,分配器将这个处于硬件高速缓存中的页分配给它,系统效率会大大增加。
- 减少锁的竞争,假设单页框都是使用free_area来管理,那么多个CPU同时频繁访问时,每次都是只能单CPU获取到页框,其他CPU等待,这会造成大量的锁竞争,导致分配效率降低。
在每CPU页框高速缓存中用一个链表来维护一个单页框的双向链表,每个CPU都有自己的链表(因为每个CPU有自己的硬件高速缓存),那些比较可能处于硬件高速缓存中的页被称为“热页”,比较不可能处于硬件高速缓存中的页称为“冷页”。其实系统判断是否为热页还是冷页很简单,越最近释放的页就比较可能是热页,所以在双向链表中,从链表头插入可能是热页的单页框,在链表尾插入可能是冷页的单页框。分配时热页就从链表头获取,冷页就从链表尾获取。
在每CPU页框高速缓存中也可能会遇到没有空闲的页框(被分配完了),这时候每CPU页框高速缓存会从伙伴系统中拿出页框放入每CPU页框高速缓存中,相反,如果每CPU页框高速缓存中页框过多,也会将一些页框放回伙伴系统。
在内核中使用struct per_cpu_pageset结构描述一个每CPU页框高速缓存,其中的struct per_cpu_pages是核心结构体,如下:
/* 描述一个CPU页框高速缓存 */ struct per_cpu_pageset { /* 高速缓存页框结构 */ struct per_cpu_pages pcp; #ifdef CONFIG_NUMA s8 expire; #endif #ifdef CONFIG_SMP s8 stat_threshold; s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS]; #endif }; struct per_cpu_pages { /* 当前CPU高速缓存中页框个数 */ int count; /* number of pages in the list */ /* 上界,当此CPU高速缓存中页框个数大于high,则会将batch个页框放回伙伴系统 */ int high; /* high watermark, emptying needed */ /* 在高速缓存中将要添加或被删去的页框个数 */ int batch; /* chunk size for buddy add/remove */ /* Lists of pages, one per migrate type stored on the pcp-lists */ /* 页框的链表,如果需要冷高速缓存,从链表尾开始获取页框,如果需要热高速缓存,从链表头开始获取页框 */ struct list_head lists[MIGRATE_PCPTYPES]; };
关于页框回收
内存中并非所有物理页面都是可以进行回收的,内核占用的页不会被换出,只有与用户空间建立了映射关系的物理页面才会被换出。总的来说,以下这些种物理页面可以被 Linux 操作系统回收:
- 进程映射所占的页面,包括代码段,数据段,堆栈以及动态分配的“存储堆”(malloc分配的)。
- 用户空间中通过mmap()把文件内容映射到内存所占的页面。
- 匿名页面(没有映射到文件的都是匿名映射,用户空间的堆和栈):进程用户模式下的堆栈以及是使用 mmap 匿名映射的内存区(共享内存区)。注:堆栈所占页面一般不被换出。
- 特殊的用于 slab 分配器的缓存,比如用于缓存文件目录结构 dentry 的 cache,以及用于缓存索引节点 inode 的 cache
- tmpfs文件系统使用的页。
Linux 操作系统使用如下这两种机制检查系统内存的使用情况,从而确定可用的内存是否太少从而需要进行页面回收。
- 周期性的检查:这是由后台运行的守护进程 kswapd 完成的。该进程定期检查当前系统的内存使用情况,当发现系统内空闲的物理页面数目少于特定的阈值时,该进程就会发起页面回收的操作。
- “内存严重不足”事件的触发:在某些情况下,比如,操作系统忽然需要通过伙伴系统为用户进程分配一大块内存,或者需要创建一个很大的缓冲区,而当时系统中 的内存没有办法提供足够多的物理内存以满足这种内存请求,这时候,操作系统就必须尽快进行页面回收操作,以便释放出一些内存空间从而满足上述的内存请求。 这种页面回收方式也被称作“直接页面回收”。
如果操作系统在进行了内存回收操作之后仍然无法回收到足够多的页面以满足上述内存要求,那么操作系统只有最后一个选择,那就是使用 OOM( out of memory )killer,它从系统中挑选一个最合适的进程杀死它,并释放该进程所占用的所有页面。
结尾
下篇再说slab了,内容太多。到这里,记住对于物理内存来说,系统都是以页框作为最小的分配单位,而分配时必定是要通过管理区分配器进行分配的,在管理区分配器中又必定是通过伙伴系统或每CPU页框分配器进行分配的,而我们编程使用到的malloc或者内核中使用的分配小额内存的情况,是使用slab实现的,slab的作用就是将一个页框细分为多个小块内存。