1、 Distributed Cluster Demo Architecture
In reality, you need a fully-distributed configuration to fully test HBase and to use it in real-world scenarios. In a distributed configuration, the cluster contains multiple nodes, each of which runs one or more HBase daemon. These include primary and backup Master instances, multiple Zookeeper nodes, and multiple RegionServer nodes.
| Node Name | Master | ZooKeeper | RegionServer |
|---|---|---|---|
|
SY-0134 |
yes |
yes |
no |
|
SY-0133 |
backup |
yes |
yes |
|
SY-0132 |
no |
yes |
yes |
|
SY-0131 |
no |
yes |
yes |
|
SY-0130 |
no |
yes |
yes |
2、各节点间配置SSH免密码登录
3、SY-0134 Master节点配置
SY-0134 will run your primary master and ZooKeeper processes, but no RegionServers. .
-
Edit conf/regionservers and remove the line which contains
localhost. Add lines with the hostnames or IP addresses for SY-0133, SY-0132,SY-0131,SY-0130. -
Configure HBase to use SY-0131 as a backup master.
Create a new file in conf/ called backup-masters, and add a new line to it with the hostname for SY-0131. In this demonstration, the hostname is SY-0131.
-
Configure ZooKeeper
In reality, you should carefully consider your ZooKeeper configuration.
Zookeeper环境在《Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的》有介绍。
Hadoop环境在《Hadoop2.6集群环境搭建(HDFS HA+YARN)原来4G内存也能任性一次.》有介绍。
On SY-0134, edit conf/hbase-site.xml and add the following properties.
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://SY-0130:8020/hbase</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>SY-0134,SY-0133,SY-0132,SY-0131,SY-0130</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/labsp/zookeeper-3.4.6/data</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> </configuration>hbase.rootdir :设置hbase数据库存放数据的目录 hbase.zookeeper.quorum :指定zookeeper集群节点名 hbase.zookeeper.property.dataDir :指zookeeper集群data目录 hbase.cluster.distributed :打开hbase分布模式Using existing ZooKeeper ensemble
设置独立运行的Zookeeper集群,修改配置 conf/hbase-env.sh
config1:
export JAVA_HOME=/lab/jdk1.7/
config2:
To point HBase at an existing ZooKeeper cluster, one that is not managed by HBase, set HBASE_MANAGES_ZK in conf/hbase-env.sh to false ... # Tell HBase whether it should manage its own instance of Zookeeper or not. export HBASE_MANAGES_ZK=falseNote that you can use HBase in this manner to spin up a ZooKeeper cluster, unrelated to HBase. Just make sure to set
HBASE_MANAGES_ZKtofalseif you want it to stay up across HBase restarts so that when HBase shuts down, it doesn’t take ZooKeeper down with it.
4、SY-0130,SY-0131,SY-0132,SY-0133配置
将SY-0134目录中的hbase0.98目录,使用scp命令远程复制到sy-0130,sy-0131,sy-0132,sy-0133对应目录结构。
[hadoop@SY-0134 hbase0.98]$ pwd
/lab/hbase0.98
5、启动与测试集群
首先要保证Hadoop集群已经启动,各节点zookeeper已经启动。其次 Be sure HBase is not running on any node.
If you forgot to stop HBase from previous testing, you will have errors. Check to see whether HBase is running on any of your nodes by using the jps command. Look for the processes HMaster, HRegionServer, andHQuorumPeer. If they exist, kill them.
Start the cluster. 启动Hbase集群
On SY-0134, issue the start-hbase.sh command. Your output will be similar to that below.
[hadoop@SY-0134 hbase0.98]$ bin/start-hbase.sh
starting master, logging to /lab/hbase0.98/bin/../logs/hbase-hadoop-master-SY-0134.out
SY-0130: starting regionserver, logging to /lab/hbase0.98/bin/../logs/hbase-hadoop-regionserver-SY-0130.out
SY-0132: starting regionserver, logging to /lab/hbase0.98/bin/../logs/hbase-hadoop-regionserver-SY-0132.out
SY-0133: starting regionserver, logging to /lab/hbase0.98/bin/../logs/hbase-hadoop-regionserver-SY-0133.out
SY-0131: starting regionserver, logging to /lab/hbase0.98/bin/../logs/hbase-hadoop-regionserver-SY-0131.out
SY-0131: starting master, logging to /lab/hbase0.98/bin/../logs/hbase-hadoop-master-SY-0131.out
ZooKeeper starts first, followed by the master, then the RegionServers, and finally the backup masters
Verify that the processes are running.
On each node of the cluster, run the jps command and verify that the correct processes are running on each server. You may see additional Java processes running on your servers as well, if they are used for other purposes.
SY-0134 JPS 输出 :
[hadoop@SY-0134 hbase0.98]$ jps
7240 HMaster
6340 QuorumPeerMain
7509 Jps
SY-0133 JPS 输出 :
[hadoop@SY-0133 bin]$ jps
6128 Jps
5317 QuorumPeerMain
5849 HRegionServer
5088 DataNode
4990 JournalNode
SY-0132 JPS 输出 :
[hadoop@SY-0132 ~]$ jps
2543 DataNode
3218 HRegionServer
3479 Jps
2435 JournalNode
2738 QuorumPeerMain
SY-0131 JPS 输出 :
[hadoop@SY-0131 zookeeper-3.4.6]$ jps
8860 NameNode
8755 JournalNode
10859 HRegionServer
9020 DataNode
9933 QuorumPeerMain
11526 Jps
10948 HMaster
SY-0130 JPS 输出 :
[hadoop@SY-0130 conf]$ jps
6636 NameNode
7803 HRegionServer
7292 QuorumPeerMain
8165 Jps
6562 JournalNode
Hbase集群启动后,Hdfs中自动创建了对应hbase目录
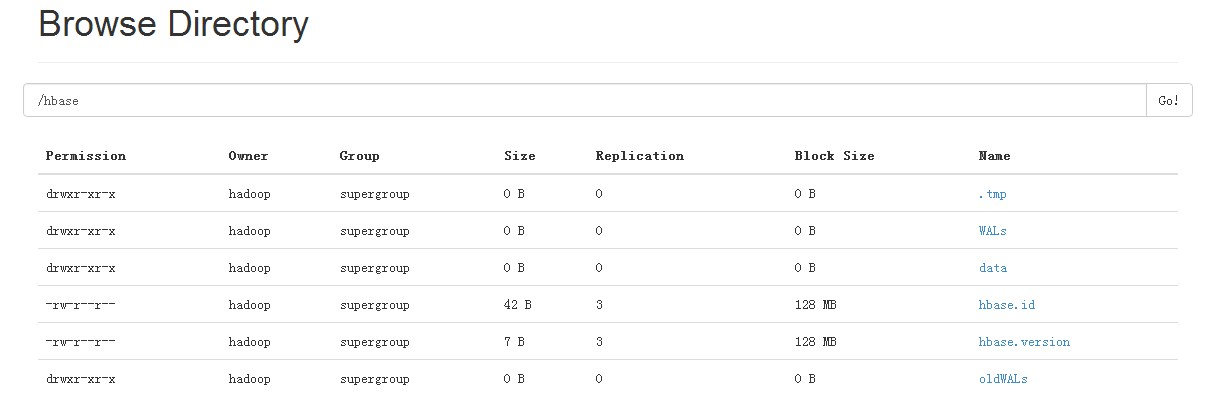
6、Browse to the Web UI.
If everything is set up correctly, you should be able to connect to the UI for the Master http://192.168.249.134:60010/ or the secondary master at http://192.168.249.131:60010 for the secondary master, using a web browser.
In HBase newer than 0.98.x, the HTTP ports used by the HBase Web UI changed from 60010 for the Master and 60030 for each RegionServer to 16610 for the Master and 16030 for the RegionServer.
0.98.x的之后的版本,不包括0.98.x,访问端口有变更。