一般线性回归
线性回归模型虽然简单,但却非常的实用,许多非线性模型也都是建立在线性模型的基础之上的。
线性模型定义为由n个属性x=(x1,x2…xn),其中xi为x在第i个属性上的取值,线性模型通过这些属性的线性组合来建立预测函数:
f(x)=β0+β1X1+β2X2+…βnXn
写成向量形式为:f(x)=βX
因为估计我们想让f(x)尽可能的接近其真实值yi,所以求β向量的过程也就是求∑(f(xi)-yi)^2的最小值的过程,也就是最小二乘法。
R中实现线性回归的函数有:
(1)model1<-lm(fromula, data, subset, weights, na.action,method="qr", model=TRUE, x=FALSE, y=FALSE, qr=TRUE,...)
说明: formula 是显示回归模型, data 是数据框, subset 是样本观察的子集, weights 是用于拟合的加权向量,na.action 显示数据是否包含缺失值,method 是指出用于拟合的方法, model, x,y, qr 是逻辑表达式,如果是TRUE,应返回其值, 除了第一个选项formula 是必选项,其他都是可选项。
(2)summary(model1)可以返回拟合的结果。
(3)step(model1)输出逐步回归结果/addl()/dropl()
(4)anova(model1)计算方差分析表
(5)coefficients(model1)取模型系数
(6)deviance(model1)计算残差平方和
(7)formula(model1)提取模型公式
(8)plot(model1)绘制模型诊断图
(9)predict(model1,newdata=data.frame)预测
(10)print(model1)显示模型拟合的结果,一般只输入对象名输出结果
(11)residuals(model1)计算残差
(12)updata(old-model,new-formula)在new-formula中,其相应的名字由“.”组成,例如fm1<-lm(y~x1+x2+x3+x4+x5,data=X);fm2<-updata(fm1,.~.+x6); fm3<-updata(fm2,sqrt(.)~.)
(13)rstandard()标准化残差
画标准化残差图:y.rst<- rstandard(model1); y.fit<-predict(model1);plot(y.rst~y.fit)
(14)diffits(model1)DIFFITS准则
(15)cooks.distance ( model1, infl=lm.influence (model1, do.coef=F), res =weighted. Residuals ( model1) ) cook统计量越大,越可能存在异常值
(16)kappa(model1)判断多重共线性
(17)eigen(X)计算相关矩阵的特征值和特征向量
(18)model2<-glm()广义线性回归
0. 概述
线性回归应该是我们听过次数最多的机器学习算法了。在一般的统计学教科书中,最后都会提到这种方法。因此该算法也算是架起了数理统计与机器学习之间的桥梁。线性回归虽然常见,但是却并不简单。该算法中几乎包含了所有有监督机器学习算法的重要知识点,比如数据的表示、参数的训练、模型的评价、利用正则化防止过拟合等概念。所以说如果掌握了线性回归,可以为后面的学习打下坚实的基础。
1. 线性回归的基本形式
最简单的线性回归就是直接利用一条直线拟合二维平面上的一系列点,目的是利用这条直线概括所有训练集中样本的散布规律或趋势,最终用于新样本点的预测。二维平面上直线方程的一般形式为y=ax+by=ax+b,使用训练集中的数据以某种方式训练该模型后,就可以确定方程中的两个参数a,ba,b的最优值。后面如果观察到了新的样本xixi,就可以带入上面学习到的公式计算yy的值了。
在三维空间中,需要学习的是确定一个二维平面的参数;
以此类推,在nn维空间中,需要学习的是确定一个n−1n−1维的超平面的参数.
之所以称该方法为线性模型,是因为该模型是由所有特征的线性组合构成的,基本形式为:
- y^y^表示线性回归模型的预测值(相对于真实观察值);
- nn表示特征的数量;
- xixi表示第ii个特征的观察值;
- θjθj表示第jj个参数的值.
如果模型包括nn个特征,那么就会包括n+1n+1个参数,还包括常数项(还是被称为截距)。
式子(1-1)使用向量化形式可以表示为hθ=θT⋅xhθ=θT⋅x, 在多样本的情况下通常表示为:
- XX是m⋅(n+1)m⋅(n+1)的矩阵,其中mm表示样本的数量;
- θθ是包含所有参数的列向量,长度为n+1n+1.
式子(1-2)表示所有样本值的矩阵与对应参数向量的乘积,属于矩阵乘法((Matrix multiplication)。
具体可以参考我的另一篇博客【机器学习】一些基本概念及符号系统中的“4. 模型的表示”部分。
2. 线性回归的代价函数
假设现在有了训练数据和模型,那么要怎么开始训练呢?这时候就必须定义一个代价函数,代价函数量化了模型预测值与实际观察值之间的误差大小。有了代价函数就可以评价取当前参数时模型性能的好坏。
在选择一个恰当的代价函数后,整个模型的训练过程就是求代价函数最小值的过程。这个过程并不容易,可能会出现下面两种情况:
- 得到全局最优解:即代价函数的最小值;
- 得到局部最优解:由于很多原因我们可能仅仅只能求的代价函数在某个区间内的极小值.
如果代价函数是一个凸函数(convex function),那么从数学上可以保证肯定能求得全局最优解;如果代价函数是非凸函数,就无法从理论上保证最终能得到代价函数的全局最优解(NP-hard问题)。
对于线性回归算法,比较常用的代价函数是均方误差(Mean Square Error, MSE)函数:
- 上式表示所有模型的预测值与实际观察值之差的平方和,因此训练集中任何一个实际观察值与模型预测值之间的误差都包含在了这个公式中;
- 为了求导方便,添加了一个系数1212,实际的MSE的定义中是没有的;
- 该函数是一个凸函数.
关于代价函数的更多解释,可以参考另一篇博客【机器学习】代价函数(cost function)
2. 利用正规方程求解
先看一下正规方程的定义:
最小二乘法可以将误差方程转化为有确定解的代数方程组(其方程式数目正好等于未知数的个数),从而可求解出这些未知参数。这个有确定解的代数方程组称为最小二乘法估计的正规方程
就像利用“一阶导数等于0的点是极值点”的性质,可以非常容易求出一元二次方程的极值点一样,我们也可以采用代数的方法直接计算式子(2-1)的最小值点。实际上经过计算可以得到:
也就是说,不用经过训练就可以直接利用上面的公式计算出线性回归模型的最优解。既然有了这么方便的方法,为什么我们还需要其他的训练方法(例如梯度下降)呢?这是因为求一个矩阵的逆运算量非常大,例如求一个n⋅nn⋅n的矩阵的逆,其计算复杂度为O(n3)O(n3)。因此,在样本量非常大时利用梯度下降来训练模型所消耗的时间远远小于直接使用正规方程计算结果所消耗的时间。当然,在样本量非常小的情况下,利用该方法还是非常方便的。
3. 利用梯度下降训练模型
梯度下降几乎可以说是机器学习算法中,训练模型和调参最重要的方法了。梯度就是所有偏导数构成的向量。因为计算代价函数的梯度需要求导,这里应该是机器学习中使用微积分最多的地方了。微博上爱可可老师分享过一个“梯度下降算法演化史”的视频,链接在这里。
3.1 梯度下降的一般步骤
- 参数的初始化:通常所有参数都初始化为1;
- 确定学习率;
- 求代价函数的梯度(所有参数的偏导数);
- 所有参数都沿梯度方向移动一步,步长就是学习率的大小;
- 重复步骤4直到参数不再发生变化(此时取到极值点,梯度为0)或达到预先设定的迭代次数.
3.1.1 学习率
学习率一般用希腊字母αα表示,可能需要多尝试几次,才能找到合适的学习率。过大的学习率会导致梯度下降时越过代价函数的最小值点,随着训练步数的增加,代价函数不减反增;如果学习率太小,训练中的每一步参数的变化会非常小,这时可以看到代价函数的值在不断减小,但是需要非常大的迭代次数才能到达代价函数的最小值点。
按照吴恩达老师的建议,每次可以3倍放大或者3倍缩小来调整,直到找到合适的学习率。
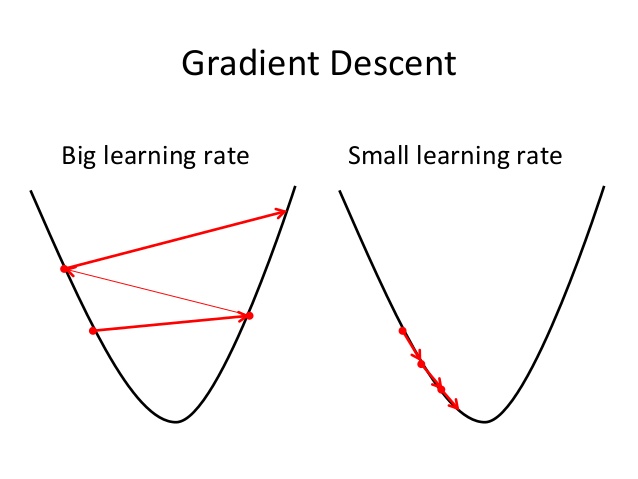
图3-1,学习率过大会导致参数的取值越过最小值点;学习率过小会导致参数变化缓慢
3.1.2 代价函数的梯度
在机器学习中,对代价函数包含的每一个参数求偏导数,这些偏导数组成的向量就是代价函数的梯度。
这个时候就要用到微积分中求导数的知识了。如果自己有兴趣可以在草稿纸上手动算一算;如果不想自己算,常见的代价函数的求导过程在网上很容易找到。
均方误差函数的梯度
为了简单起见,先考虑只有一个特征的直线方程:h(θ)=θ0+θ1x1h(θ)=θ0+θ1x1
令x0=1x0=1,则可得h(θ)=θ0x0+θ1x1h(θ)=θ0x0+θ1x1
参考MSE的公式,见式子(2-1),可得,
- J(θ)J(θ)对θ0θ0的偏导数:∂∂θ0J(θ)=1m∑mi=1[(hθ(x(i))−y(i))⋅x(i)0]⋯ (3−1)∂∂θ0J(θ)=1m∑i=1m[(hθ(x(i))−y(i))⋅x0(i)]⋯ (3−1);
- J(θ)J(θ)对θ1θ1的偏导数:∂∂θ1J(θ)=1m∑mi=1[(hθ(x(i))−y(i))⋅x(i)1]⋯ (3−2)∂∂θ1J(θ)=1m∑i=1m[(hθ(x(i))−y(i))⋅x1(i)]⋯ (3−2);
其中mm表示样本数量;yiyi表示第ii个样本的观察值;xi1x1i表示第ii个样本的第1个特征的观察值;式子中的点号⋅⋅表示普通乘法。
3.2 梯度下降的Python实现
3.2.1 方法1 - 原始实现
下面根据前面已经获得的信息,做一个简单的实现,首先利用直线方程生成一些数据(添加了一些随机误差)

1 import numpy as np 2 import matplotlib.pyplot as plt 3 m = 100 # 样本量 4 X = 2 * np.random.rand(m, 1) # 取大小在区间(0, 1)上的随机数,构成一个100*1的矩阵 5 y = 5 + 2 * X + np.random.rand(m, 1) 6 plt.plot(X, y, "b.") 7 plt.show()
显示如下,

图3-2,利用直线方程和随机误差生成的原始数据(训练集)
下面定义了计算代价函数的方法,并且利用梯度下降训练模型的参数。第16行对θ0θ0求偏导数,相当于式子(3-1);第17行对θ1θ1求偏导数,相当于式子(3-2).
1 # 计算代价函数 2 def L_theta(theta, X_x0, y): 3 delta = np.dot(X_x0, theta) - y # np.dot 表示矩阵乘法 4 L_theta = np.sum(np.multiply(delta, delta)) 5 return L_theta 6 7 T = 1000 # 迭代次数 8 theta = np.ones((2, 1)) # 参数的初始化 9 alpha = 0.06 # 学习率 10 X_x0 = np.c_[np.ones((100, 1)), X] # ADD X0 = 1 to each instance 11 12 13 for i in range(T): 14 theta_0 = theta[0, 0] 15 theta_1 = theta[1, 0] 16 theta_0 -= alpha*(1/m * np.sum(np.dot(X_x0, theta) - y)) 17 theta_1 -= alpha*(1/m * np.sum(np.dot(np.transpose(X), np.dot(X_x0, theta) - y))) 18 theta[0, 0] = theta_0 19 theta[1, 0] = theta_1 20 if i%100==0: 21 print(L_theta(theta, X_x0, y))
上面的代码中设置了总的迭代次数为1000次,并且每隔100次,计算当前参数下的代价函数值,输出如下:
2318.32226584 26.2317675878 10.6221201088 8.60799768785 8.3481142323 8.31458131008 8.31025453649 8.30969625023 8.30962421422 8.30961491936
从上面的输出可以看到,代价函数的值一直在减小,前面变化很大,后面变化的幅度非常小,说明后面的参数所在的位置已经非常接近代价函数的最小值点,这附近曲线比较平滑,梯度也比较小。
下面是训练完成后的参数θθ,即代码中变量theta的取值:
print(theta) # 训练结束后得到的最优参数值
输出结果如下:
array([[ 5.48119293],
[ 1.98150554]])
这个结果,与我们生成数据时设定的斜率和截距非常接近。有了参数,线性回归的方程就确定了,下面比较一下训练出来的直线与生成的数据之间的关系:
1 plt.plot(X, h, 'r-') 2 plt.plot(X, y, 'b.') 3 plt.axis([0, 2, 4, 12]) 4 plt.show()
结果如下,
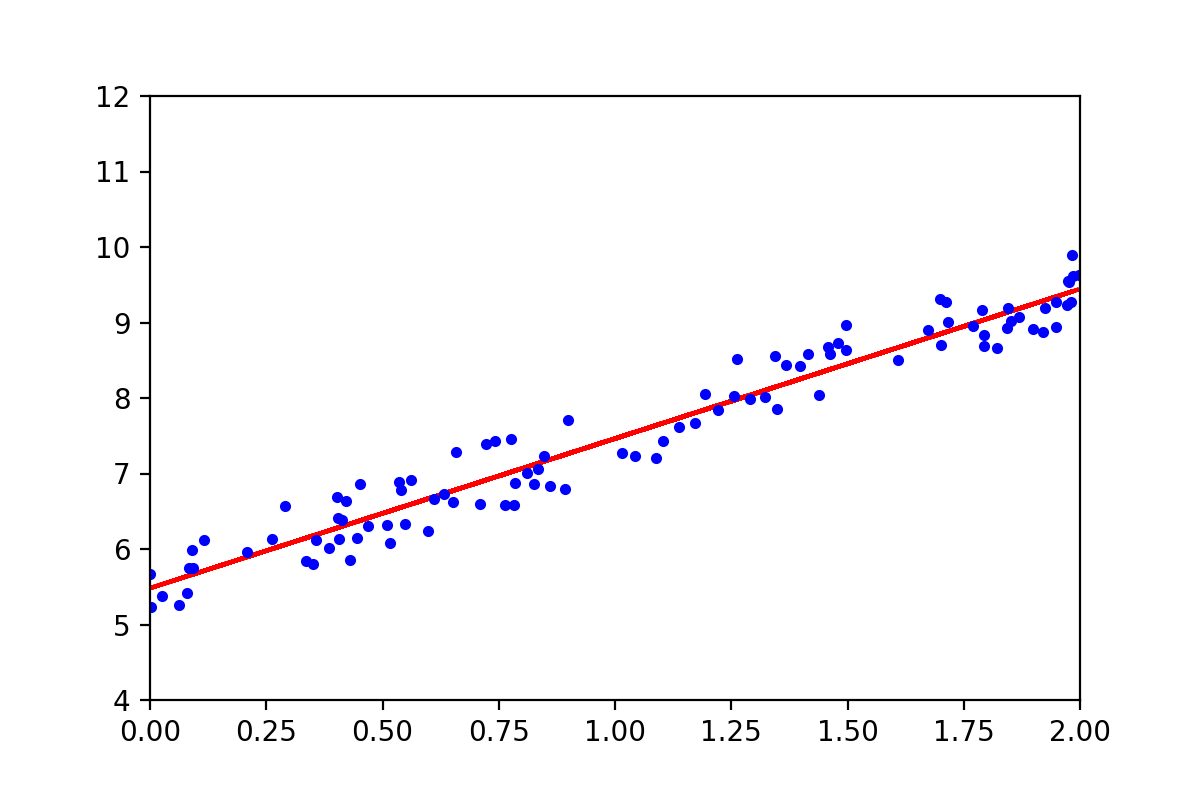
图3-3,训练出来的参数确定的直线方程与训练集中样本点的比较
图中红色的线是训练出来的参数确定的直线,蓝色点是原始数据。从上图可以看出来,训练出来的直线方程与前面生成的数据匹配的非常好。确定了直线方程,获得新的数据点后直接带入该直线方程,就可以得到相应的预测值(这也是很多时候我们做线性回归分析的最终目的):
1 X_new = np.array([[0.5], [1.8]]) 2 X_new_b = np.c_[np.ones((2, 1)), X_new] # add x0 = 1 to each instance 3 y_predict = X_new_b.dot(theta) 4 print(X_new) 5 print(y_predict)
输出结果如下:
[[ 0.5] [ 1.8]] [[ 6.4719457] [ 9.0479029]]
上面的结果说明,如果0.5和1.8也用同样的方式产生出来的话,那么可以以非常高的可信度预测它们对应的函数值hh大约为6.47和9.05。
3.2.2 方法2 - 梯度的向量化表示
上面的方法显得有点繁琐,在代码中对两个参数分别求偏导数,并且分别更新它们的值,假如有100个参数,就要重复100次几乎相同的步骤。因此这样的代码,可扩展性非常差。下面我们使用梯度和向量化的方式来重写梯度下降的实现过程。通过比较两个参数的偏导数,即式子(3-1)和(3-2),不难发现它们非常相似,如果把这些式子统一起来,所有参数的偏导数可以写成下面的样子: