-
Jsoup代码解读之四-parser
作为Java世界最好的HTML 解析库,Jsoup的parser实现非常具有代表性。这部分也是Jsoup最复杂的部分,需要一些数据结构、状态机乃至编译器的知识。好在HTML语法不复杂,解析只是到DOM树为止,所以作为编译器入门倒是挺合适的。这一块不要指望囫囵吞枣,我们还是泡一杯咖啡,细细品味其中的奥妙吧。
基础知识
编译器
将计算机语言转化为另一种计算机语言(通常是更底层的语言,例如机器码、汇编、或者JVM字节码)的过程就叫做编译(compile)。编译器(Compiler)是计算机科学的一个重要领域,已经有很多年历史了,而最近各种通用语言层出不穷,加上跨语言编译的兴起、DSL概念的流行,都让编译器变成了一个很时髦的东西。
编译器领域相关有三本公认的经典书籍,龙书《Compilers: Principles, Techniques, and Tools 》,虎书《Modern Compiler Implementation in X (X表示各种语言)》,鲸书《Advanced Compiler Design and Implementation》。其中龙书是编译理论方面公认的不二之选,而后面两本则对实践更有指导意义。另外@装配脑袋有个很好的编译器入门系列博客:http://www.cnblogs.com/Ninputer/archive/2011/06/07/2074632.html
编译器的基本流程如下:
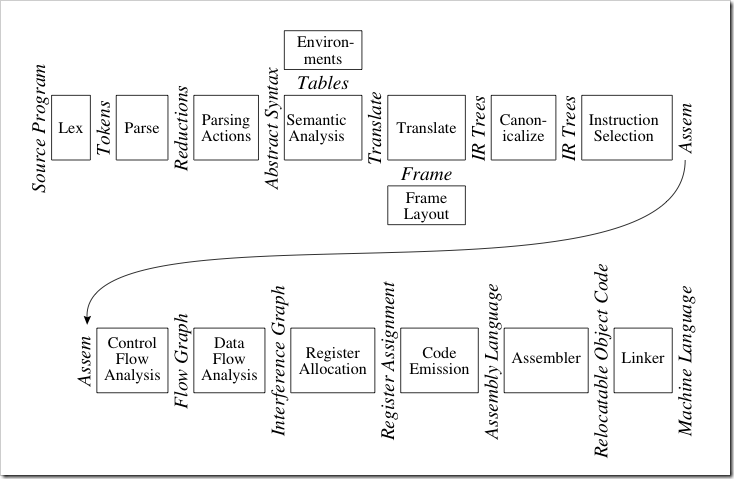
其中词法分析、语法分析、语义分析这部分又叫编译器的前端(front-end),而此后的中间代码生成直到目标生成、优化等属于编译器的后端(back-end)。编译器的前端技术已经很成熟了,也有yacc这样的工具来自动进行词法、语法分析(Java里也有一个类似的工具ANTLR),而后端技术更加复杂,也是目前编译器研究的重点。
说了这么多,回到咱们的HTML上来。HTML是一种声明式的语言,可以理解它的最终的输出是浏览器里图形化的页面,而并非可执行的目标语言,因此我将这里的Translate改为了Render。
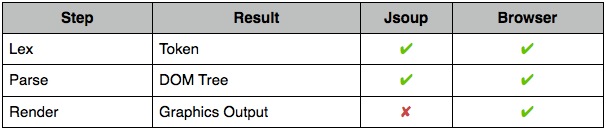
在Jsoup(包括类似的HTML parser)里,只做了Lex(词法分析)、Parse(语法分析)两步,而HTML parse最终产出结果,就是DOM树。至于HTML的语义解析以及渲染,不妨看看携程UED团队的这篇文章:《浏览器是怎样工作的:渲染引擎,HTML解析》。
状态机
Jsoup的词法分析和语法分析都用到了状态机。状态机可以理解为一个特殊的程序模型,例如经常跟我们打交道的正则表达式就是用状态机实现的。
它由状态(state)和转移(transition)两部分构成。根据状态转移的可能性,状态机又分为DFA(确定有限状态机)和NFA(非确定有限状态自动机)。这里拿一个最简单的正则表达式"a[b]*“作为例子,我们先把它映射到一个状态机DFA,大概是这样子:

状态机本身是一个编程模型,这里我们尝试用程序去实现它,那么最直接的方式大概是这样:
public void process(StringReader reader) throws StringReader.EOFException {
char ch;
switch (state) {
case Init:
ch = reader.read();
if (ch == 'a') {
state = State.AfterA;
accum.append(ch);
}
break;
case AfterA:
...
break;
case AfterB:
...
break;
case Accept:
...
break;
}
}
这样写简单的状态机倒没有问题,但是复杂情况下就有点难受了。还有一种标准的状态机解法,先建立状态转移表,然后使用这个表建立状态机。这个方法的问题就是,只能做纯状态转移,无法在代码级别操作输入输出。
Jsoup里则使用了状态模式来实现状态机,初次看到时,确实让人眼前一亮。状态模式是设计模式的一种,它将状态和对应的行为绑定在一起。而在状态机的实现过程中,使用它来实现状态转移时的处理再合适不过了。
“a[b]*“的例子的状态模式实现如下,这里采用了与Jsoup相同的方式,用到了枚举来实现状态模式:
public class StateModelABStateMachine implements ABStateMachine {
State state;
StringBuilder accum;
enum State {
Init {
@Override
public void process(StateModelABStateMachine stateModelABStateMachine, StringReader reader) throws StringReader.EOFException {
char ch = reader.read();
if (ch == 'a') {
stateModelABStateMachine.state = AfterA;
stateModelABStateMachine.accum.append(ch);
}
}
},
Accept {
...
},
AfterA {
...
},
AfterB {
...
};
public void process(StateModelABStateMachine stateModelABStateMachine, StringReader reader) throws StringReader.EOFException {
}
}
public void process(StringReader reader) throws StringReader.EOFException {
state.process(this, reader);
}
}
PS:我在github上fork了一份Jsoup的代码,把这系列文章提交了上去,并且给一些代码增加了中文注释,有兴趣的可以看看https://github.com/code4craft/jsoup-learning。本文中提到的几种状态机的完整实现在这个仓库的https://github.com/code4craft/jsoup-learning/tree/master/src/main/java/us/codecraft/learning路径下。
代码结构
先介绍以下parser包里的主要类:
-
ParserJsoup parser的入口facade,封装了常用的parse静态方法。可以设置
maxErrors,用于收集错误记录,默认是0,即不收集。与之相关的类有ParseError,ParseErrorList。基于这个功能,我写了一个PageErrorChecker来对页面做语法检查,并输出语法错误。 -
Token保存单个的词法分析结果。Token是一个抽象类,它的实现有
Doctype,StartTag,EndTag,Comment,Character,EOF6种,对应6种词法类型。 -
Tokeniser保存词法分析过程的状态及结果。比较重要的两个字段是
state和emitPending,前者保存状态,后者保存输出。其次还有tagPending/doctypePending/commentPending,保存还没有填充完整的Token。 -
CharacterReader对读取字符的逻辑的封装,用于Tokenize时候的字符输入。CharacterReader包含了类似NIO里ByteBuffer的
consume()、unconsume()、mark()、rewindToMark(),还有高级的consumeTo()这样的用法。 -
TokeniserState用枚举实现的词法分析状态机。
-
HtmlTreeBuilder语法分析,通过token构建DOM树的类。
-
HtmlTreeBuilderState语法分析状态机。
-
TokenQueue虽然披了个Token的马甲,其实是在query的时候用到,留到select部分再讲。
词法分析状态机
现在我们来讲讲HTML的词法分析过程。这里借用一下http://ued.ctrip.com/blog/?p=3295里的图,图中描述了一个Tag标签的状态转移过程,

这里忽略了HTML注释、实体以及属性,只保留基本的开始/结束标签,例如下面的HTML:
<div>test</div>
Jsoup里词法分析比较复杂,我从里面抽取出了对应的部分,就成了我们的miniSoupLexer(这里省略了部分代码,完整代码可以看这里MiniSoupTokeniserState):
enum MiniSoupTokeniserState implements ITokeniserState {
/**
* 什么层级都没有的状态
* ⬇
* <div>test</div>
* ⬇
* <div>test</div>
*/
Data {
// in data state, gather characters until a character reference or tag is found
public void read(Tokeniser t, CharacterReader r) {
switch (r.current()) {
case '<':
t.advanceTransition(TagOpen);
break;
case eof:
t.emit(new Token.EOF());
break;
default:
String data = r.consumeToAny('&', '<', nullChar);
t.emit(data);
break;
}
}
},
/**
* ⬇
* <div>test</div>
*/
TagOpen {
...
},
/**
* ⬇
* <div>test</div>
*/
EndTagOpen {
...
},
/**
* ⬇
* <div>test</div>
*/
TagName {
...
};
}
参考这个程序,可以看到Jsoup的词法分析的大致思路。分析器本身的编写是比较繁琐的过程,涉及属性值(区分单双引号)、DocType、注释、HTML实体,以及一些错误情况。不过了解了其思路,代码实现也是按部就班的过程。
最近生活上有点忙,女儿老是半夜不睡,精神状态也不是很好。工作上的事情也谈不上顺心,有很多想法但是没有几个被认可,有些事情也不是说代码写得好就行的。算了,还是端正态度,毕竟资历尚浅,我还是继续我的。
读Jsoup源码并非无聊,目的其实是为了将webmagic做的更好一点,毕竟parser也是爬虫的重要组成部分之一。读了代码后,收获也不少,对HTML的知识也更进一步了。
DOM树产生过程
这里单独将TreeBuilder部分抽出来叫做语法分析过程可能稍微不妥,其实就是根据Token生成DOM树的过程,不过我还是沿用这个编译器里的称呼了。
TreeBuilder同样是一个facade对象,真正进行语法解析的是以下一段代码:
protected void runParser() {
while (true) {
Token token = tokeniser.read();
process(token);
if (token.type == Token.TokenType.EOF)
break;
}
}
TreeBuilder有两个子类,HtmlTreeBuilder和XmlTreeBuilder。XmlTreeBuilder自然是构建XML树的类,实现颇为简单,基本上是维护一个栈,并根据不同Token插入节点即可:
@Override
protected boolean process(Token token) {
// start tag, end tag, doctype, comment, character, eof
switch (token.type) {
case StartTag:
insert(token.asStartTag());
break;
case EndTag:
popStackToClose(token.asEndTag());
break;
case Comment:
insert(token.asComment());
break;
case Character:
insert(token.asCharacter());
break;
case Doctype:
insert(token.asDoctype());
break;
case EOF: // could put some normalisation here if desired
break;
default:
Validate.fail("Unexpected token type: " + token.type);
}
return true;
}
insertNode的代码大致是这个样子(为了便于展示,对方法进行了一些整合):
Element insert(Token.StartTag startTag) {
Tag tag = Tag.valueOf(startTag.name());
Element el = new Element(tag, baseUri, startTag.attributes);
stack.getLast().appendChild(el);
if (startTag.isSelfClosing()) {
tokeniser.acknowledgeSelfClosingFlag();
if (!tag.isKnownTag()) // unknown tag, remember this is self closing for output. see above.
tag.setSelfClosing();
} else {
stack.add(el);
}
return el;
}
HTML解析状态机
相比XmlTreeBuilder,HtmlTreeBuilder则实现较为复杂,除了类似的栈结构以外,还用到了HtmlTreeBuilderState来构建了一个状态机来分析HTML。这是为什么呢?不妨看看HtmlTreeBuilderState到底用到了哪些状态吧(在代码中中用 标明状态):
<!-- State: Initial -->
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<!-- State: BeforeHtml -->
<html lang='zh-CN' xml:lang='zh-CN' xmlns='http://www.w3.org/1999/xhtml'>
<!-- State: BeforeHead -->
<head>
<!-- State: InHead -->
<script type="text/javascript">
//<!-- State: Text -->
function xx(){
}
</script>
<noscript>
<!-- State: InHeadNoscript -->
Your browser does not support JavaScript!
</noscript>
</head>
<!-- State: AfterHead -->
<body>
<!-- State: InBody -->
<textarea>
<!-- State: Text -->
xxx
</textarea>
<table>
<!-- State: InTable -->
<!-- State: InTableText -->
xxx
<tbody>
<!-- State: InTableBody -->
</tbody>
<tr>
<!-- State: InRow -->
<td>
<!-- State: InCell -->
</td>
</tr>
</table>
</html>
这里可以看到,HTML标签是有嵌套要求的,例如<tr>,<td>需要组合<table>来使用。根据Jsoup的代码,可以发现,HtmlTreeBuilderState做了以下一些事情:
-
语法检查
例如
tr没有嵌套在table标签内,则是一个语法错误。当InBody状态直接出现以下tag时,则出错。Jsoup里遇到这种错误,会发现这个Token的解析并记录错误,然后继续解析下面内容,并不会直接退出。InBody { boolean process(Token t, HtmlTreeBuilder tb) { if (StringUtil.in(name, "caption", "col", "colgroup", "frame", "head", "tbody", "td", "tfoot", "th", "thead", "tr")) { tb.error(this); return false; } } -
标签补全
例如
head标签没有闭合,就写入了一些只有body内才允许出现的标签,则自动闭合</head>。HtmlTreeBuilderState有的方法anythingElse()就提供了自动补全标签,例如InHead状态的自动闭合代码如下:private boolean anythingElse(Token t, TreeBuilder tb) { tb.process(new Token.EndTag("head")); return tb.process(t); }还有一种标签闭合方式,例如下面的代码:
private void closeCell(HtmlTreeBuilder tb) { if (tb.inTableScope("td")) tb.process(new Token.EndTag("td")); else tb.process(new Token.EndTag("th")); // only here if th or td in scope }
实例研究
缺少标签时,会发生什么事?
好了,看了这么多parser的源码,不妨回到我们的日常应用上来。我们知道,在页面里多写一个两个未闭合的标签是很正常的事,那么它们会被怎么解析呢?
就拿<div>标签为例:
-
漏写了开始标签,只写了结束标签
case EndTag: if (StringUtil.in(name,"div","dl", "fieldset", "figcaption", "figure", "footer", "header", "pre", "section", "summary", "ul")) { if (!tb.inScope(name)) { tb.error(this); return false; } }恭喜你,这个
</div>会被当做错误处理掉,于是你的页面就毫无疑问的乱掉了!当然,如果单纯多写了一个</div>,好像也不会有什么影响哦?(记得有人跟我讲过为了防止标签未闭合,而在页面底部多写了几个</div>的故事) -
写了开始标签,漏写了结束标签
这个情况分析起来更复杂一点。如果是无法在内部嵌套内容的标签,那么在遇到不可接受的标签时,会进行闭合。而
<div>标签可以包括大多数标签,这种情况下,其作用域会持续到HTML结束。
好了,parser系列算是分析结束了,其间学到不少HTML及状态机内容,但是离实际使用比较远。下面开始select部分,这部分可能对日常使用更有意义一点。