在系统中加入虚拟化层,对资源进行空间上的模拟、时间上的分割,虚拟化成多份资源,供上层使用。
1、cpu虚拟化
全虚拟化:在hypervisor中,对客户机的所有指令进行翻译,然后交给操作系统os执行。客户机机操作系统运行在ring1级别,宿主机操作系统运行在ring0级别。
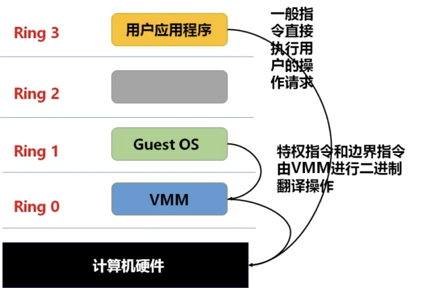
半虚拟化:只有特权指令、敏感指令在hypervisor进行翻译,调用宿主机操作系统指令;其他指令在hypervisor层调用hypercall返回对应在宿主机的结果。但是此操作需要改客户机OS代码,不通用,适配性不好。
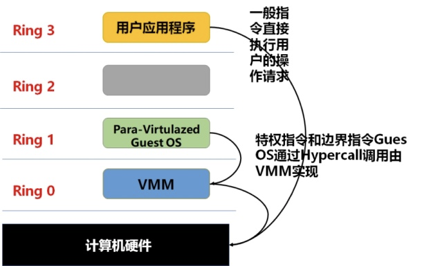
为解决此问题,inter提出VT-x 技术。引入根模式、非根模式;客户机运行在根模式,其对应ring0级别;宿主机运行在ring0以下级别
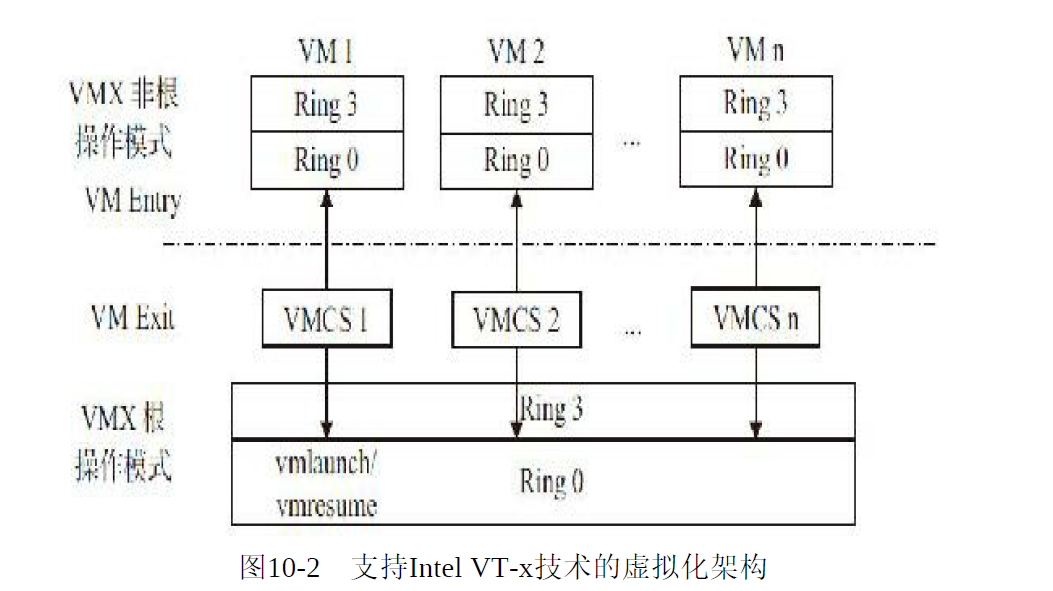
非根模式下敏感指令被重新定义,能不经过虚拟化就直接运行或通过在陷入模拟的方式来处理;根模式下处理方式没有变化。
非根模式下敏感指令引起的陷入称为:VM-EXIT;根模式切换为非根模式下称为:VM-ENTRY,此操作由宿主机发起调度某个客户机运行。
VMCS保存虚拟cpu相关的状态,如在根模式、非根模式下寄存器的值等。
2、内存虚拟化
对地址空间虚拟化,引入了客户机物理地址空间,需两次内存地址进行转换。GVA->VPA->HPA。客户机虚拟地址到客户机物理地址的转换是客户机操作系统通过客户机状态与CR3指向的页表决定;客户机物理地址到宿主机物理地址的转换是通过宿主机来决定,在物理内存分配给客户机时就决定的。
3、I/O虚拟化
传统的io虚拟化
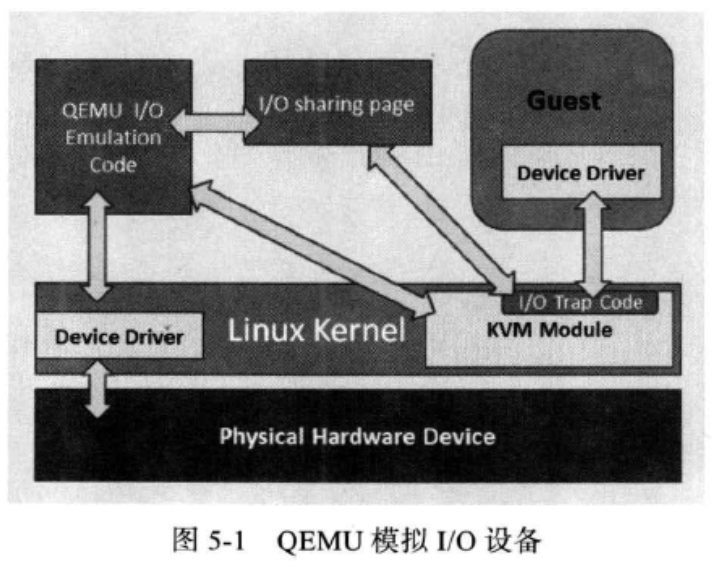
在io虚拟化时,kvm使用的是传统的qume来做io虚拟化。当客户机设备发起io请求后,kvm模块io操作捕捉代码拦截本次io请求,然后将本次io请求的信息放入io共享页中,并通知用户进程qume来处理本次io请求,qume获取到io操作的具体信息后,交由硬件模拟代码模拟本次io请求,然后将结果放入共享页中,通知kvm io操作模拟完成,kvm取得模拟结果返回给客户机。也可以通过dma操作直接把io模拟结果送到客户机内存空间中,让kvm告诉客户机io操作完成。
由于传统的qume模拟io操作有较多的vmentry,vmexit,需要多次上下文切换,需要多次数据复制,所以性能较差。因此引出了io半虚拟化
io半虚拟化
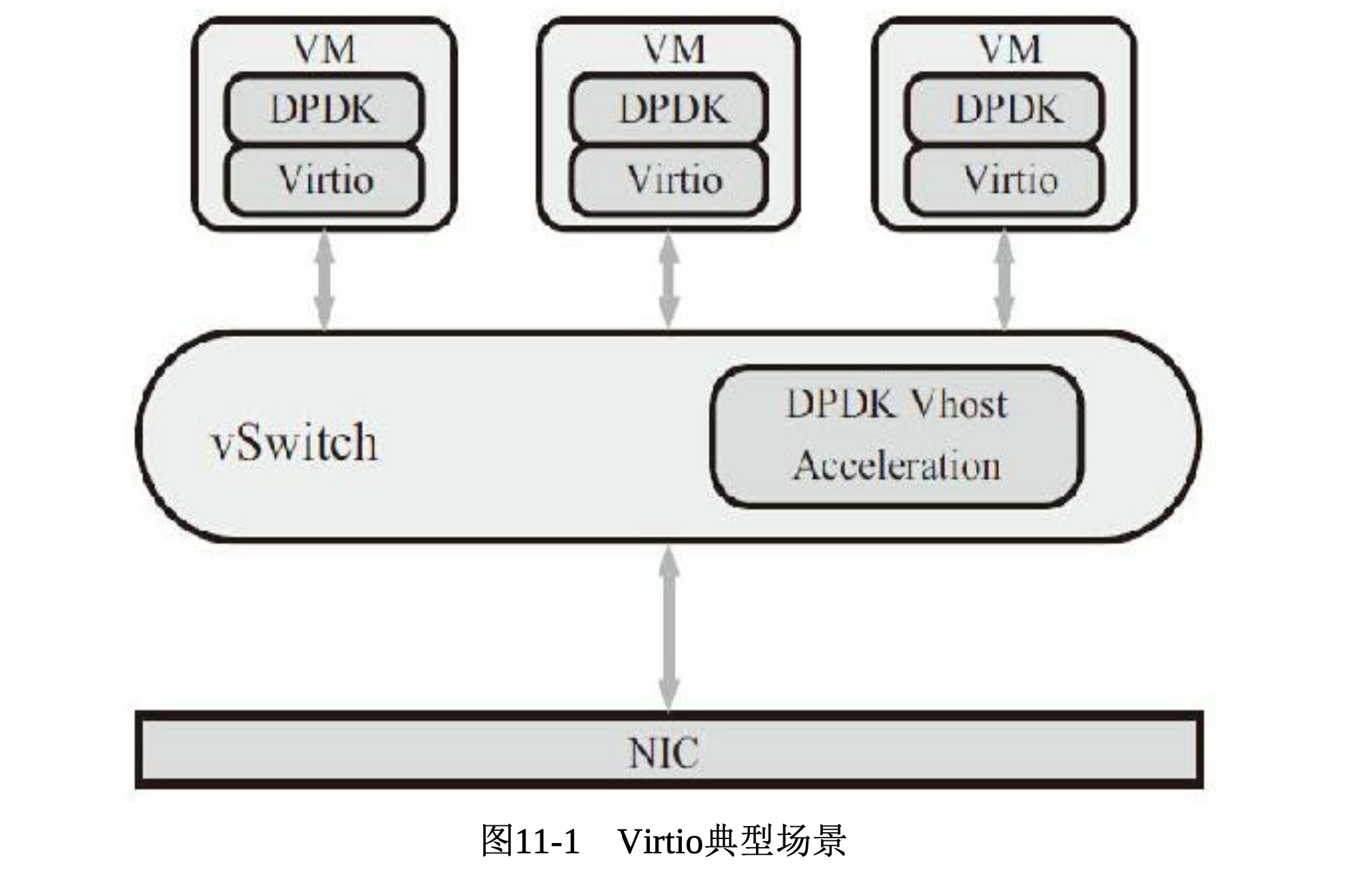
宿主机使用虚拟交换机连接虚拟机,虚拟交换机中安装dpdk vhost后端,虚拟机中有dpdk virtio前端程序。前后端通过virtio的虚拟队列通信,由虚拟机发送的报文到虚拟交换机,由转发逻辑
到物理网卡中。
virtio在pci层上定义了virtqueue,用于连接前后端程序。可以配置一个或多个队列;virtio使用两个队列:发送队列和接受队列。
传统网卡队列:前端指针(virtio驱动使用)和后端指针(设备代表virtio后端驱动,如vhost)初始化都为0;当前段驱动要发送n个数据包时,填充到前端指针描述符中,网卡能看到前端指针的变化来更新后端指针的描述符,后端指针更新完毕后,网卡数据处理完成,等待下次任务到来。这种模式消费者依赖于生产者完成,生产者没有完成时消费者无法跟新。
双网卡队列中描述符只能顺序执行,前一个描述符没有处理完,后一个描述符只能等待。virtio虚拟队列不存在这个限制,图如下:
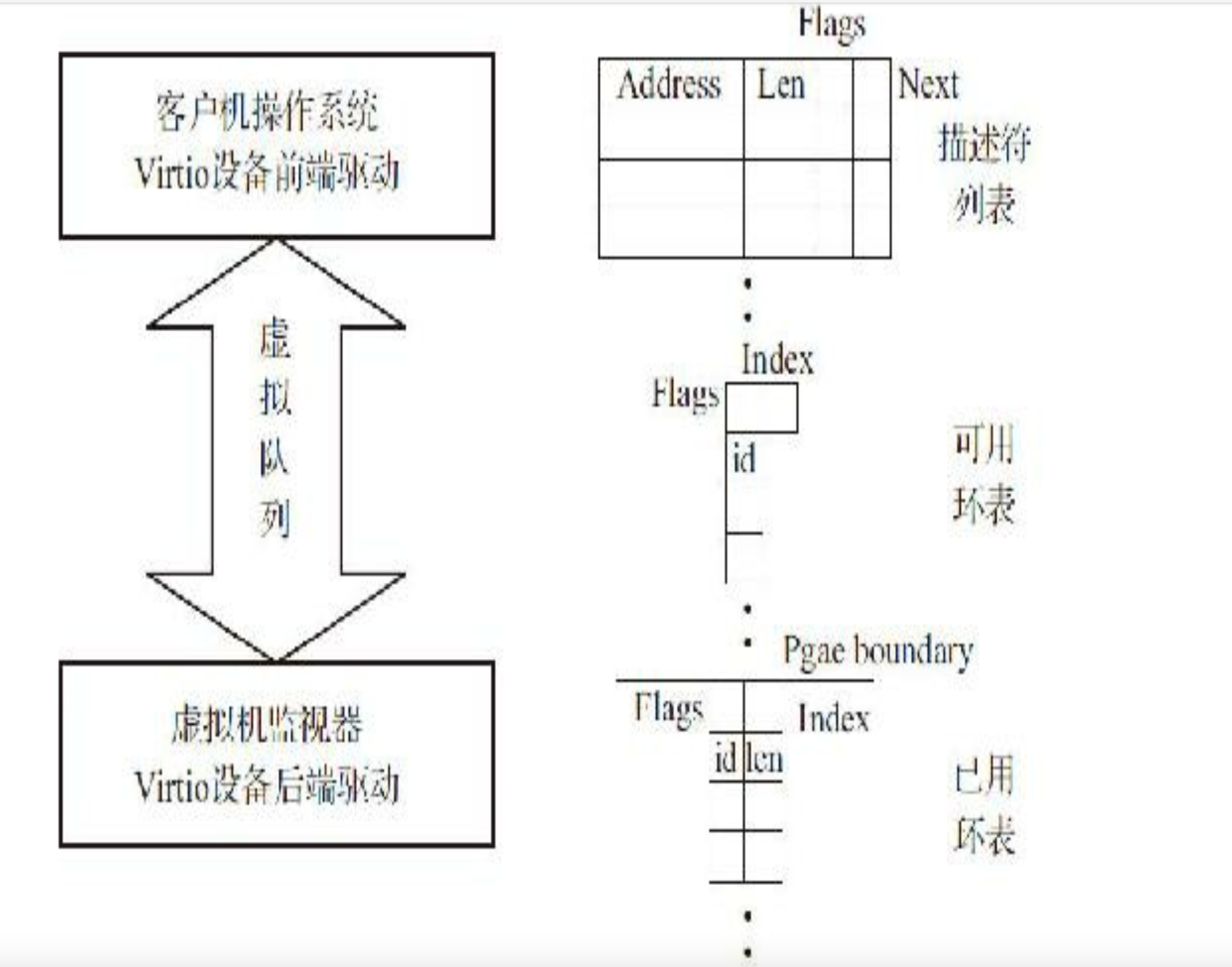
虚拟队列初始化和设备初始化紧邻,使用设备寄存器地址空间。
- 选择虚拟机队列写入队列选择寄存器
- 读取队列容量寄存器,获取队列大小,0表示设备不可用
- 分配队列需要的内存,把物理地址写入寄存器
- 用一个向量处理队列中断,把向量号写入中断寄存器
描述符列表:客户端一侧的数据缓冲区,共客户机和宿主机之间数据传递。当客户机发送的数据过大描述符列表装不下时,通过描述符链串起来。
可用环表:由驱动写入、设备读出;设备取出环表中的描述符后,当缓冲区为可读时表示客户机有数据发出(驱动发送数据到设备);当缓冲区可写时表示有数据接受。
已用环表:设备写入,驱动读出;设备使用完可用环表描述符后放入用环表,通知驱动回收描述符
驱动通过描述符列表和可用表环列表给设备使用,设备使用完后通过已用表环通知驱动回收描述符。
单数据帧发送优化:前段驱动和后端驱动运行在不同的core上,前段驱动更新和后端驱动读取可用表环会触发不同core之间可用环表的cache迁移,为解决这一问题,dpdk固定可用环表和描述符表项的映射。可用环表的跟新只需要更新环表自身指针,固定的环表可避免不同core之间的cache迁移。
virtio-net三要素:虚拟队列机制(用于前后端数据交互)、消息通知机制(客户机到宿主机消息通知)、中断机制(宿主机到客户机中断请求--收包)
虚拟机利用qume、kvm通信

qume利用kvm模拟整个系统运行环境,包括处理器、外设等;tap是内核中的虚拟以太网设备。
客户机发包时,通过消息通知机制通知kvm,并退出到qume,有其对tap设备读写。宿主机、客户机、qume来回切换,cpu指令级切换带来性能开销,主要集中在消息通知机制和数据通道
- 数据从tap拷贝到qume和从qume拷贝到客户机;
- 报文到达tap设备时内核发出并送到qume,qume利用ioctl想kvm请求中断,kvm发送中断到客户机。
内核态vhost
qume不再负责virtio-net的虚拟队列工作,由vhost在内核态来负责及报文送达消息通知的中断
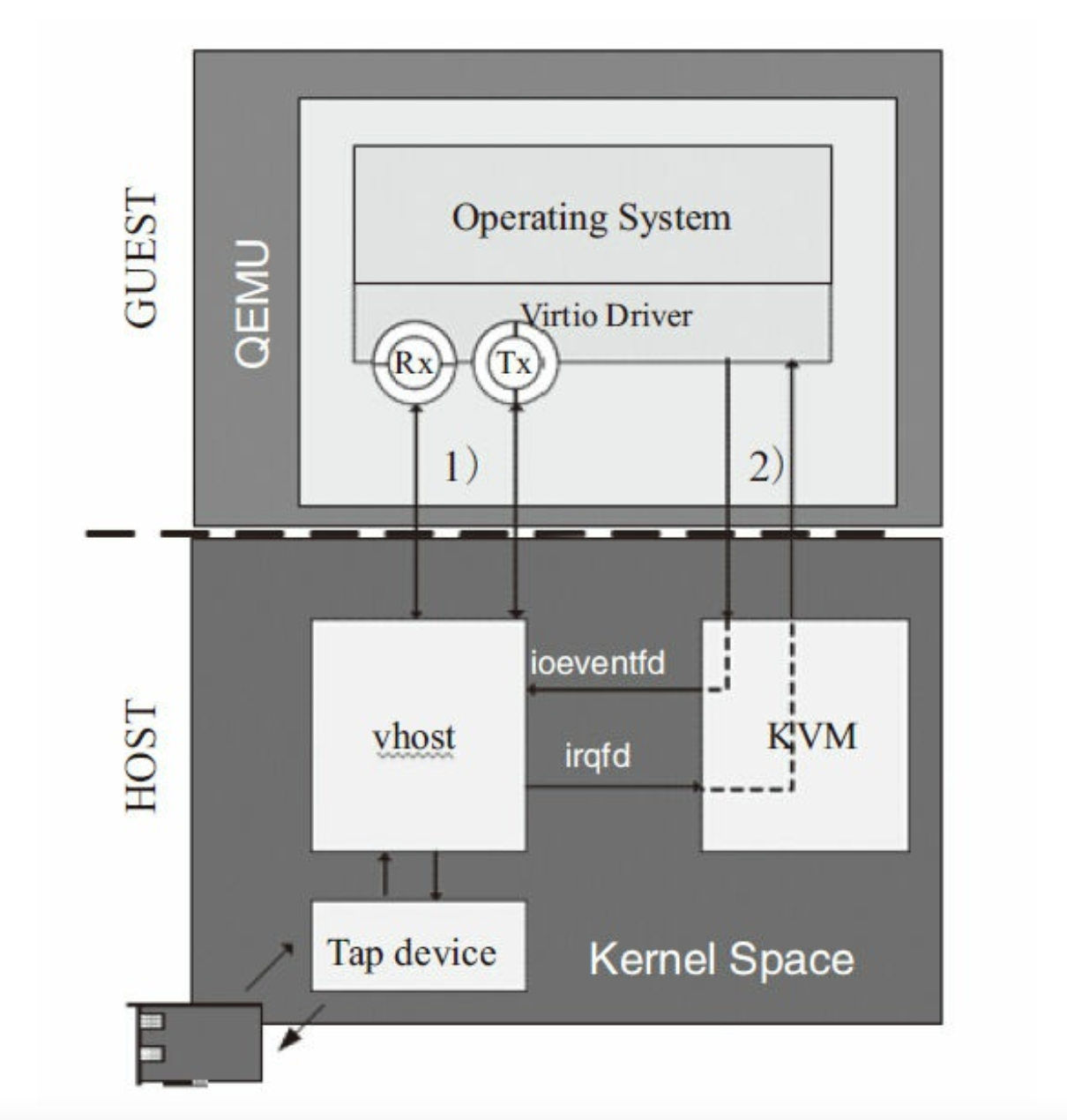
- 从tap收到报文,vhost-net把报文送到虚拟队列的数据区,客户机接受报文
- 报文从tap到达vhost-net时,通过kvm向客户机发送中断,通知其接受报文
如上操作前提时qume要共享如下信息:
- qume共享客户机内存布局,host-net可以得到客户机的物理地址到宿主机的物理地址转换
- qume共享虚拟队列地址,host-net要对虚拟队列直接进行读写操作
- qume共享kvm向客户机上virtio-net发送中断的描述符,host-net收到报文后通知客户机取走报文
- qume共享kvm向客户机virtio-net pci设备空间的读写描述符,当客户机有数据要发送时,pci设备上写描述符被触发,host-net可收包
vhost-user
卸载vhost-net在内核中处理报文,迁移至用户态。vhost-user为每个vm创建一个端口,实现virtio后端逻辑:虚拟机的收发报请求、数据拷贝等;每个vm运行于qume进程内,qume整合了kvm的通信逻辑,成为vm主进程,包含vcpu等线程。vhost-user和qume都是用户态进程,在数据拷贝时候必须由内存共享。
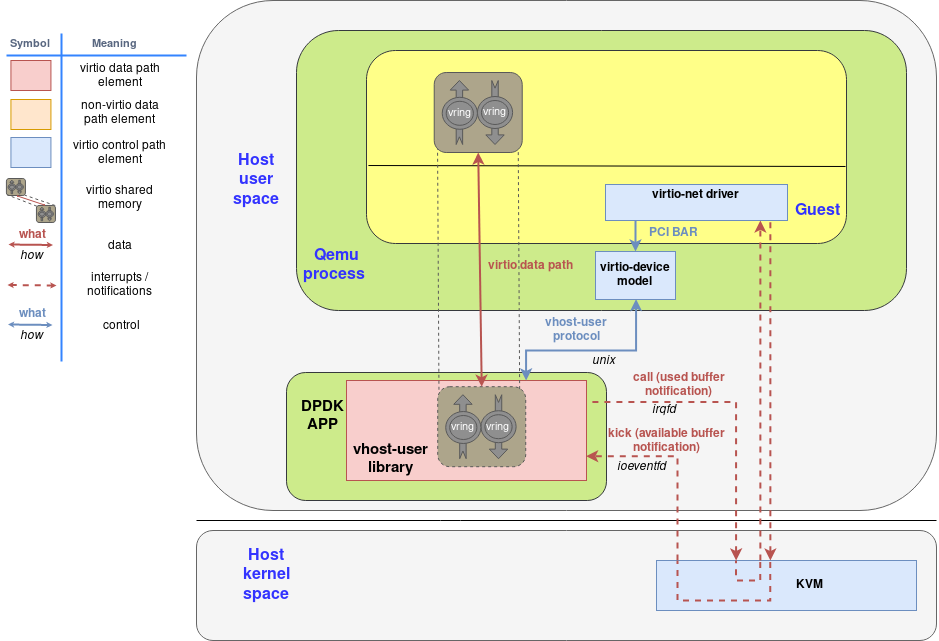
发包:vm要发送报文时,qume发送ioeventfd给kvm,使其通知vhost-user拷贝数据。当由数据包到vhost-user后(dpdk旁路内核直接收包到应用进程dpdk空间:vfio、igb_uio),通过irqfd通知kvm,使其通知guest收报文。
pci设备直接分配
传统io虚拟化:平台依赖性低,不需要宿主机、客户机额外的支持,兼容性高;缺点:io路径长,有较多的vm-entry、exit切换,性能差,适用于性能不高的场景遗留的旧设备
io半虚拟化:减少了vm-entry、exit的次数,效率高;缺点:兼容性不好,需要客户机virtio相关驱动支持,io频繁时cpu使用率高
VT-d技术允许宿主机中的pci设备直接分配给客户机使用,很少需要kvm的参与,只能分配给一个客户机使用,为了使多个客户机能够共享一个物理设备,并且达到设备直接分配的性能,pci 设备支持了SR-IOV(单根io虚拟化),分为pf,vf
pf:包含物理网卡的所有功能,可以管理和配置单根io虚拟化,就是一个普通的pci设备,可以管理其他vf
vf:包含数据传输的最小资源,独立的内存空间、中断、dma,不需要hypervisor的介入(kvm)就可以传输数据
https://www.sdnlab.com/24470.html
https://www.jianshu.com/p/ae54cb57e608
kvm
kvm只支持硬件虚拟化,它的目的是打开并初始化硬件以支持虚拟机的运行。kvm模块为内核模块的一部分;当内核模块被加载时,kvm模块先初始化内部数据结构,然后打开CPU中的cr4寄存器虚拟化模式开关,执行VMXON将宿主机(包含kvm模块本身)至于虚拟化根模式中,之后kvm模块创建/dev/kvm设备文件等待用户空间命令。
它只有cpu、内存虚拟化;用户空间在准备好的虚拟机在kvm支持下处于非根模式下执行二进制指令;非根模式下所有敏感的二进制指令会被处理器捕捉到,保存现场后切换到根模式由kvm决定下一步处理。
在kvm架构中,通过ioctl操作/dev/kvm文件,最重要的调用是"创建虚拟机"(创建内核数据结构并初始化),kvm返回一个文件句柄代表“创建的虚拟机”,通过该句柄对虚拟机进行管理。每个客户机都是一个标准的Linux进程(qume进程),每个vcpu是宿主机中qume进程派生的一个线程,多个vcpu就是qume中的多个线程