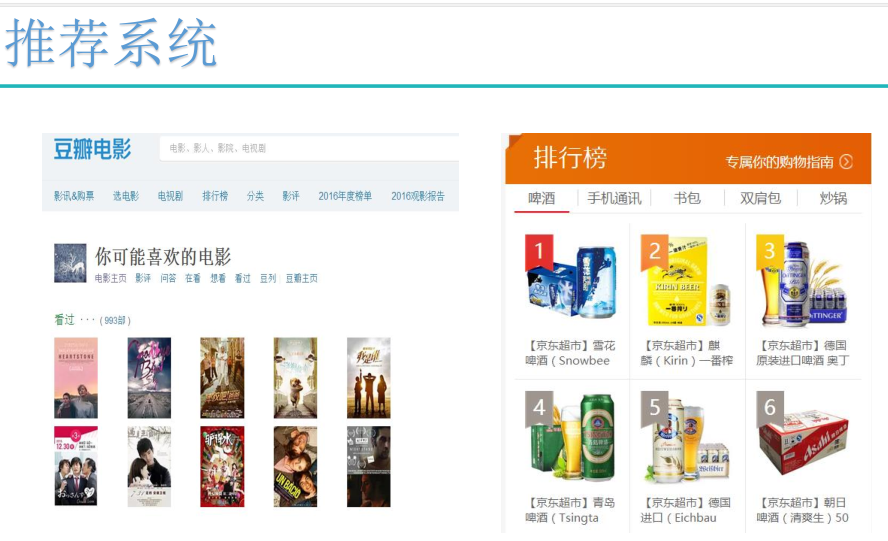
推荐系统的应用



推荐系统要完成的任务:







pearson相似度与欧式距离相似度的最大区别在于它比欧式距离更重视数据集的整体性;因为pearson相似度计算的是相对距离,欧式距离计算的是绝对距离。
就实际应用来说,有不同量纲和单位的数据集适合使用pearson相似度来计算,相同量纲和单位的数据集适合使用欧氏距离。

 第三个中文名是余弦相似度
第三个中文名是余弦相似度
补充:
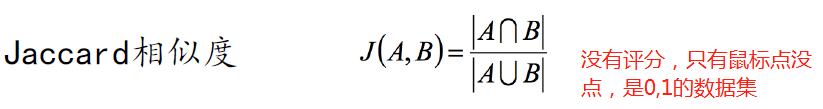
皮尔逊相关系数是目前推荐系统中用的最多的。

协同过滤分为两种:基于用户的协同过滤和基于物品的协同过滤。
基于用户的协同过滤:

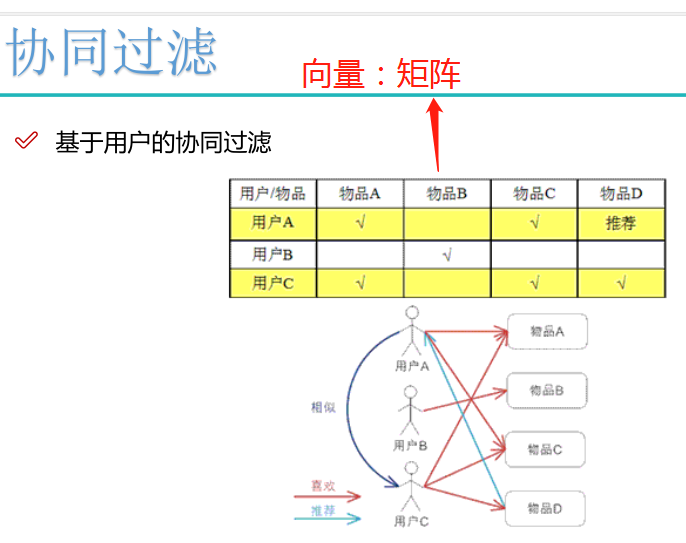




基于物品的协同过滤:





注:计算相似度前减去均值,是为了消除差异化(有的人对电影打分整体就高,有的人整体就低,不同人标准不同),是结果更客观。


推荐排行榜单是最简单的解决冷启动的问题,因为大众心理,大部分人喜欢什么,自己也会去关注下。



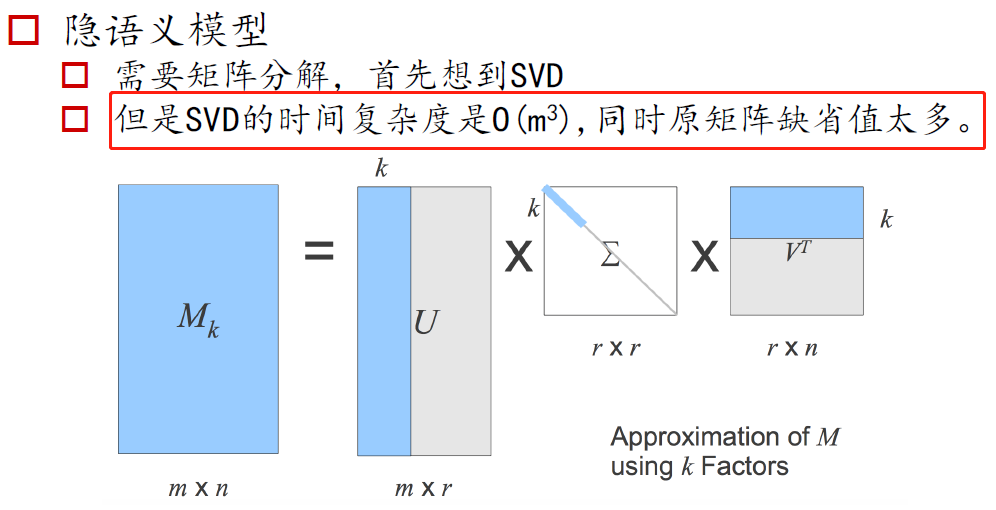
隐语义模型:



 注:损失函数就是目标函数。
注:损失函数就是目标函数。
 注:步长就是学习率α。
注:步长就是学习率α。



隐语义模型的基本思想
隐语义模型是近年来推荐系统领域较为热门的话题,它主要是根据隐含特征将用户与物品联系起来,可以算到用户和隐含特征的关系以及物品和隐含特征的关系,有了隐含特征就可以还原回去,即便原来是很稀疏的矩阵,还原回去之后每个位置就有值了,就可以知道对这个东西的喜好程度,然后就可以做个性化推荐了。
现从简单例子出发介绍隐语义模型的基本思想。假设用户A喜欢《数据挖掘导论》,用户B喜欢《三个火枪手》,现在小编要对用户A和用户B推荐其他书籍。基于 UserCF(基于用户的协同过滤),找到与他们偏好相似的用户,将相似用户偏好的书籍推荐给他们;基于ItemCF(基于物品的协同过滤),找到与他们 当前偏好书籍相似的其他书籍,推荐给他们。其实还有一种思路,就是根据用户的当前偏好信息,得到用户的兴趣偏好,将该类兴趣对应的物品推荐给当前用户。比 如,用户A喜欢的《数据挖掘导论》属于计算机类的书籍,那我们可以将其他的计算机类书籍推荐给用户A;用户B喜欢的是文学类数据,可将《巴黎圣母院》等这 类文字作品推荐给用户B。这就是隐语义模型,依据“兴趣”这一隐含特征将用户与物品进行连接,需要说明的是此处的“兴趣”其实是对物品类型的一个分类而 已。
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域中,并得到了不错的应用效果。
为什么隐语义之后可以再加协同过滤?为了提高用户体验舒适度,因为协同过滤可以给出推荐的原因。

模型评估标准:
如何对推荐系统推荐系统进行评价呢?由于推荐引擎建好后既没有预测的目标值,也没有用户来调查他们对推荐的满意程度,所以常常将某些已知的评分值去掉,然后对它们进行预测,计算预测值和真实值之间的差异通常用于推荐引擎评价的指标是最小均方根误差(Root Mean Squared Error,RMSE),先计算均方误差的平均值,在取平方根。如果评级在1~5星级,我们得到的RMSE为1,则和真实评价差了1个星级。


注:1.覆盖率:主要是推荐系统希望消除马太效应(两极分化现象),只推荐最热门的,别推荐冷门。2.多样性中满意度解释不正确,多样性表示推荐列表中物品两两之间的不相似性。设分子s(i,j)表示物品i和j之间的相似度,R(u)表示推荐商品的个数,分母为推荐的类别数为Cn2=1/2|R(u)|(|R(U)|-1)
补充:




评估标准是千变万化的,比如可以设个广告收益作为一个标准,可以自己指定,不同的任务可以设置不同的评价标准。

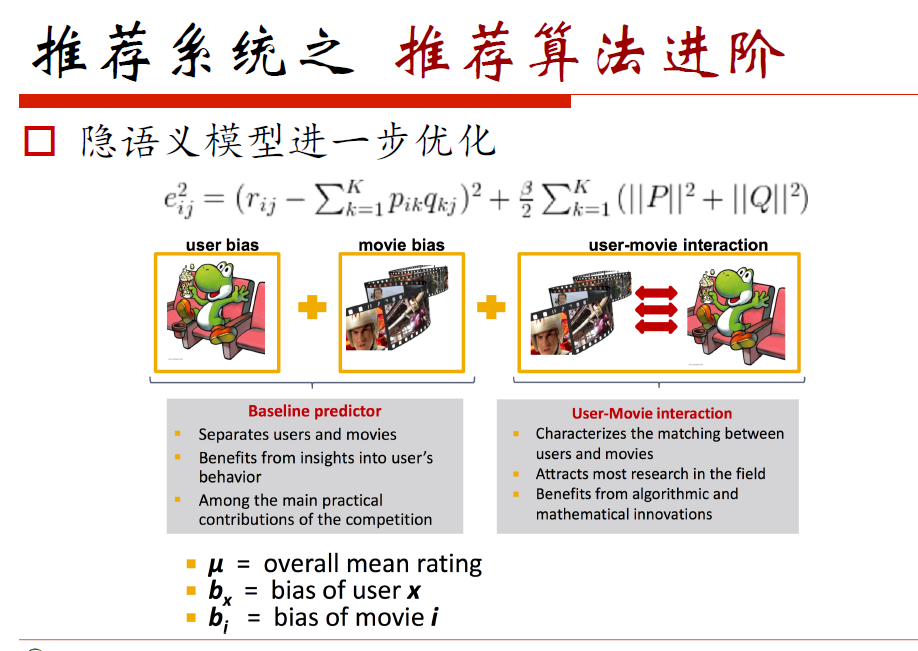




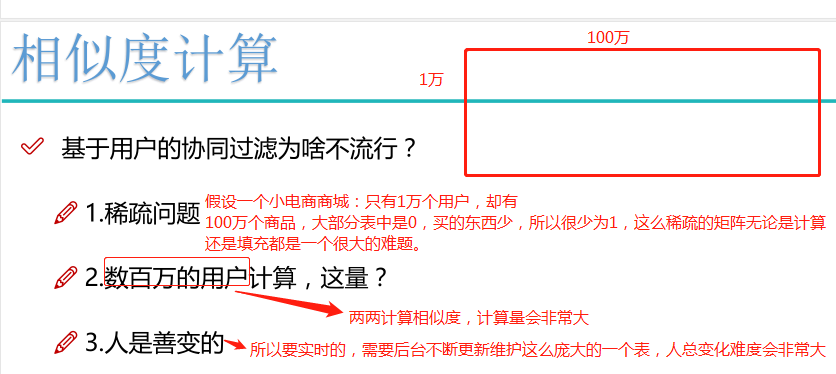
推荐系统两大难点:计算量怎么解决,推荐模型的好坏怎么去评估和更新。
补充:
推荐系统系列之隐语义模型
一、隐语义模型的基本思想
隐语义模型是近年来推荐系统领域较为热门的话题,它主要是根据隐含特征将用户与物品联系起来。
现从简单例子出发介绍隐语义模型的基本思想。假设用户A喜欢《数据挖掘导论》,用户B喜欢《三个火枪手》,现在小编要对用户A和用户B推荐其他书籍。基于 UserCF(基于用户的协同过滤),找到与他们偏好相似的用户,将相似用户偏好的书籍推荐给他们;基于ItemCF(基于物品的协同过滤),找到与他们 当前偏好书籍相似的其他书籍,推荐给他们。其实还有一种思路,就是根据用户的当前偏好信息,得到用户的兴趣偏好,将该类兴趣对应的物品推荐给当前用户。比 如,用户A喜欢的《数据挖掘导论》属于计算机类的书籍,那我们可以将其他的计算机类书籍推荐给用户A;用户B喜欢的是文学类数据,可将《巴黎圣母院》等这 类文字作品推荐给用户B。这就是隐语义模型,依据“兴趣”这一隐含特征将用户与物品进行连接,需要说明的是此处的“兴趣”其实是对物品类型的一个分类而 已。
二、隐语义模型的数学理解
我们从数学角度来理解隐语义模型。如下图所示,R矩阵是用户对物品的偏好信息(Rij表示的是user i对item j的兴趣度),P矩阵是用户对各物品类别的一个偏好信息(Pij表示的是user i对class j的兴趣度),Q矩阵是各物品所归属的的物品类别的信息(Qij表示的是item j在class i中的权重)。隐语义模型就是要将矩阵R分解为矩阵P和矩阵Q的乘积,即通过矩阵中的物品类别(class)将用户user和物品item联系起来。实际 上我们需要根据用户当前的物品偏好信息R进行计算,从而得到对应的矩阵P和矩阵Q。
三、隐语义模型所解决的问题
从上面的陈述我们可以知道,要想实现隐语义模型,我们需解决以下问题:
如何对物品进行分类,分成几类?
如何确定用户对哪些物品类别有兴趣,兴趣程度如何?
对于一个给定的类,选择这个类中的哪些物品进行推荐,如何确定物品在某个类别中的权重?
对于第一个问题,就是找对应的编辑人进行人工分类,但是人工分类会存在以下问题:
当前的人工分类不能代表用户的意见:比如一本《数据挖掘导论》,从编辑人员的角度看会属于计算机类,但从用户来看,可能会归到数学类;
难以把握分类的粒度:仍以《数据挖掘导论》为例,可分类得粗一点,属于计算机类,也可分得再细一点,属于计算机类别中的数据挖掘类;
难以给一个物品多个类别:一本小说可归为文学类,或言情类等;
难以给出多维度的分类:对物品的分类可从多个角度进行,比如一本书可从内容进行分类,也可从作者角度进行分类;
难以确定一个物品在某一分类中的权重:一个物品可能属于多个类别,但是权重不同;
基于以上局限性,显然我们不能靠由个人的主观想法建立起来的分类标准对整个平台用户喜好进行标准化。隐语义模型是从用户的偏好数据出发进行个性推荐的,即基于用户的行为统计进行自动聚类,所以能解决以上提到的5个问题:
隐语义模型是基于用户的行为数据进行自动聚类的,能反应用户对物品的分类意见;
我们可以指定将物品聚类的类别数k,k越大,则粒度越细;
隐语义模型能计算出物品在各个类别中的权重,这是根据用户的行为数据统计的,不会只将其归到一类中;
隐语义模型得到的物品类别不是基于同一个维度的,维度是由用户的共同兴趣决定的;
四、隐语义模型的样本问题
隐语义模型在显性反馈数据(也就是评分数据)上能解决评分预测问题并达到了很好的精度。不过推荐系统主要讨论的是隐性反馈数据集,这种数据集的特点 是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣)。那么,在隐性反馈数据集上应用隐语义模型解决推荐的第一个关键问题就是如何 给每个用户生成负样本。我们发现对负样本采样时应该 遵循以下原则:
对每个用户,要保证正负样本的平衡(数目相似);
每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品:一般认为,很热门而用户却没有行为更加代表用户对这个物品不感兴趣。因为对于冷门的物 品,用户可能是压根没在网站中发现这个物品,所以谈不上是否感兴趣;
五、隐语义模型的推导思路
隐语义模型是根据如下公式来计算用户U对物品I的兴趣度。
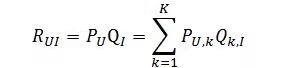
其中,隐语义模型会把物品分成K个类型,这个是我们根据经验和业务知识进行反复尝试决定的,p(u,k)表示用户u对于第k个分类的喜爱程度(1 < k <= K),q(k, i)表示物品i属于第k个分类的权重(1 < k <= K)。
现在我们讨论下如何计算矩阵P和矩阵Q中的参数值。一般做法就是最优化损失函数来求参数。
损失函数如下所示:
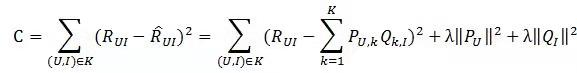
上式中的
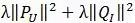
是用来防止过拟合的正则化项,λ需要根据具体应用场景反复实验得到。损失函数的意义是用户u对物品i的真实喜爱程度与推算出来的喜爱程度的均方根误差,通俗 来说就是真实的喜爱程度与推算的喜爱程度的误差,要使模型最合理当然就是使这个误差达到最小值。公式中最后两项是惩罚因子,用来防止分类数取得过大而使误 差减少的不合理做法的发生,λ参数是一个常数,需要根据经验和业务知识进行反复尝试决定的。
损失函数的优化使用随机梯度下降算法:
1)对两组未知数求偏导数

2)根据随机梯度下降法得到递推公式
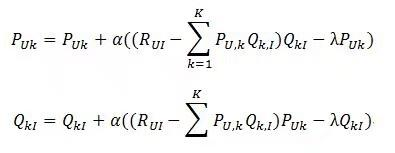
其中α是在梯度下降的过程中的步长(也可以称作学习速率),这个值不宜过大也不宜过小,过大会产生震荡而导致很难求得最小值,过小会造成计算速度下降,需 要经过试验得到最合适的值。最终会求得每个用户对于每个隐分类的喜爱程度矩阵P和每个物品与每个隐分类的匹配程度矩阵Q。在用户对物品的偏好信息矩阵R 中,通过迭代可以求得每个用户对每个物品的喜爱程度,选取喜爱程度最高而且用户没有反馈过的物品进行推荐。
在隐语义模型中,重要的参数有以下4个:
1)隐分类的个数F;
2)梯度下降过程中的步长(学习速率)α;
3)损失函数中的惩罚因子λ;
4)正反馈样本数和负反馈样本数的比例ratio;
这四项参数需要在试验过程中获得最合适的值.1)3)4)这三项需要根据推荐系统的准确率、召回率、覆盖率及流行度作为参考, 而2)步长α要参考模型的训练效率。
六、优缺点分析
隐语义模型在实际使用中有一个困难,那就是它很难实现实时推荐。经典的隐语义模型每次训练时都需要扫描所有的用户行为记录,这样才能计算出用户对于 每个隐分类的喜爱程度矩阵P和每个物品与每个隐分类的匹配程度矩阵Q。而且隐语义模型的训练需要在用户行为记录上反复迭代才能获得比较好的性能,因此 LFM的每次训练都很耗时,一般在实际应用中只能每天训练一次,并且计算出所有用户的推荐结果。从而隐语义模型不能因为用户行为的变化实时地调整推荐结果 来满足用户最近的行为。
数据集中行代表用户user,列代表物品item,其中的值代表用户对物品的打分。基于SVD的优势在于:用户的评分数据是稀疏矩阵,可以用SVD将原始数据映射到低维空间中,然后计算物品item之间的相似度,可以节省计算资源。
整体思路:先找到用户没有评分的物品,然后再经过SVD“压缩”后的低维空间中,计算未评分物品与其他物品的相似性,得到一个预测打分,再对这些物品的评分从高到低进行排序,返回前N个物品推荐给用户。
具体代码如下,主要分为5部分:
第1部分:加载测试数据集;
第2部分:定义三种计算相似度的方法;
第3部分:通过计算奇异值平方和的百分比来确定将数据降到多少维才合适,返回需要降到的维度;
第4部分:在已经降维的数据中,基于SVD对用户未打分的物品进行评分预测,返回未打分物品的预测评分值;
第5部分:产生前N个评分值高的物品,返回物品编号以及预测评分值。
优势在于:用户的评分数据是稀疏矩阵,可以用SVD将数据映射到低维空间,然后计算低维空间中的item之间的相似度,对用户未评分的item进行评分预测,最后将预测评分高的item推荐给用户。
参考:https://www.cnblogs.com/lzllovesyl/p/5243370.html