原文地址:http://www.c-sharpcorner.com/UploadFile/rmcochran/csharp_memory01122006130034PM/csharp_memory.aspx
虽然在.NET framework中,我们没有必要过多的担心内存管理和垃圾回收(GC),但是,为了优化我们的应用程序,我们还是需要记住这内存管理和垃圾回收的。同时,对内存管理是如何工作的有一个基本的了解之后,将有助于理解我们所写的程序中的变量的行为。在这篇文章里,我将描述heap(堆)和stack(栈)的基本知识,变量的类型以及变量的工作原理。
.NET framework中,当我们执行代码的时候,有2个地方来存储数据:heap和stack。堆和栈帮助我们执行代码。他们位于我们机器的内存,同时包含程序运行所需的信息。
Stack vs Heap,两者有什么区别?
栈,记录我们的代码中什么正在被执行(或者什么被”调用”)
堆,记录我们的对象(大部分,是数据)
我们可以把栈想象成自下而上堆积起来的箱子。每当我们调用一个方法的时候,我们就在顶部放一个箱子,用来记录我们应用程序所发生的事情。我们只能使用栈顶部的箱子。当我们处理完顶部的那个箱子(即方法执行完毕),我们就将其扔掉,然后处理顶部箱子的下一个箱子。
堆大抵是类似,只不过他是用来记录信息的(而不像栈,大部分情况都是用来记录执行状态的),因此,任何时候,堆中的任何东西都是可以被访问的。与栈只能访问顶部的箱子不一样,对堆的访问时没有限制的。
堆,就像是放在床上的一堆未经收拾的干净的衣服,我们可以很快的拿到我们想要的衣服。栈就像放在壁橱里的一叠鞋盒,为了拿到下面的鞋盒,我们必须先移除顶部的。
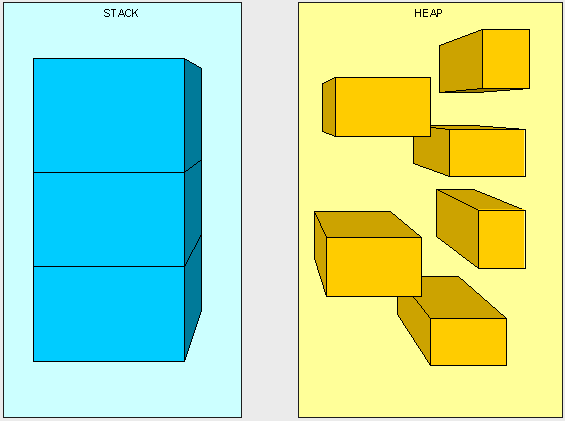
上图虽然不能代表内存的真实情况,但是有助于我们区别栈和堆。
栈是自我管理的(self-maintaining),意思也就是说,它基本上管理着自己的内存。当顶部的箱子没用了之后,就会被扔掉。
相反的,堆,就需要考虑垃圾的回收,从而保持堆上是干净的。
栈和堆上都发生了些什么?
当我们的代码执行的时候,主要有四种类型的东西会放到栈和堆中:值类型(Value Types),引用类型(Reference Types),指针(Pointers)和指令(Instructions)。
值类型:
在C#中,声明为以下类型的东西都是值类型(因为他们都继承自System.ValueType):
- bool
- byte
- char
- decimal
- double
- enum
- float
- int
- long
- sbyte
- short
- struct
- uint
- ulong
- ushort
引用类型:
声明为以下类型的都是引用类型:
- class
- interface
- delegate
- object
- string
指针:
第三种被列入内存管理模式的是作为一个类型的引用。引用,也通常被称为指针。我们不明确的使用指针,他们是被CLR管理的。指针和引用类型是不同的,当我们说a是一个引用类型的时候,指的是,我们可以通过指针找到它。指针是指向另一块内存空间的一块内存空间。指针就像放在堆和栈的其他东西一样占据着一块空间,而且,他的值是一块内存地址或者null。
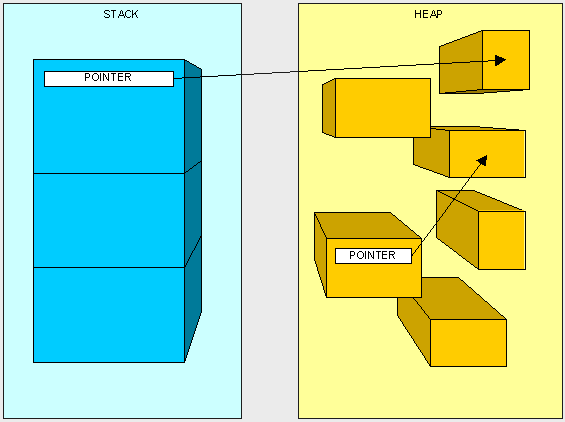
指令:
本章的后面部分将介绍指令时如何工作的。
如何决定哪些东西应该放在哪里?
OK,最后一件事,然后我们将介绍有趣的事。
有2个黄金法则:
1. 引用类型用于位于堆上--够简单的,对吧?
2. 值类型和指针总是置于他们被声明的地方。这个有点复杂,我们需要更多的了解栈是如何工作的,从而解决“东西”是在哪里被声明的。
栈,正如我们前面提到的,它是用来记录代码中每个线程执行到哪里(或者,什么正在被调用)。你可以把它看成是一个线程状态,而且,每个线程都有自己的栈。当我们的代码去执行一个方法时,线程就开始执行被JIT编译过的指令并记录到方法表(When our code makes a call to execute a method the thread starts executing the instructions that have been JIT compiled and live on the method table,这句翻译不过来),同时,它也将方法的参数放到了线程栈上。然后,当我们继续执行代码,执行到方法内部的变量时,他们就被放到了栈顶。通过例子可以更好的理解:
以下面的方法为例:
public int AddFive(int pValue)
{
int result;
result = pValue + 5;
return result;
}
这是栈顶所发生的情况。记住,我们所看到的,是放置在栈的顶部,该栈上已经存在其他很多东西了。
一旦我们开始执行方法,这个方法的参数就已经位于栈上了(我们将稍后讨论传参)。
注意:方法本省并不存在于栈上,只是为了描述作为参考。
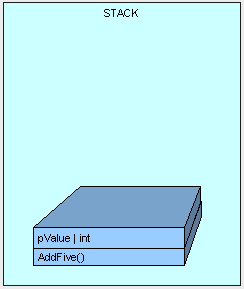
接下来,控制(执行方法的线程)被传递到位于类型的方法表里面的AddFive()方法,如果是第一次调用该方法,JIT编译器会将该方法的IL代码转换成本地CPU指令。
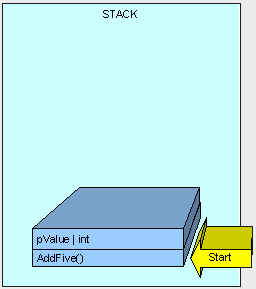
随着方法的执行,我们需要为”result”变量分配内存到堆栈上。
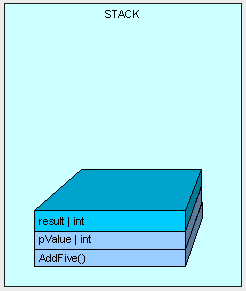
方法执行完毕后,结果将返回。
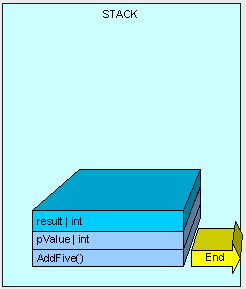
指针移动到AddFive()这个方法开始位置的可用内存,清楚分配在该栈上的内存,然后执行下一个方法。
在这个例子中,我们的”result”变量被放到栈上面。每个声明在方法内部的值类型,都将被放到栈上。
现在,值类型有时也会被放在堆上。记住我们的原则:值类型和指针总是置于他们被声明的地方。如果一个值类型是在方法外被声明的,但是,是声明在引用类型的内部,它将随同该引用类型被放到堆上。
这是另外一个例子:
假设我们有下面这样一个MyInt类(显然这是一个引用类型,因为它是一个类):
public class MyInt
{
public int MyValue;
}
然后执行下面的方法:
public MyInt AddFive(int pValue)
{
MyInt result = new MyInt();
result.MyValue = pValue + 5;
return result;
}
如前所述,一个线程开始执行这个方法,而该方法的参数也将被放到该线程的栈上。
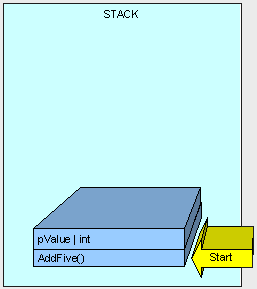
现在,事情变得有趣了。。。
由于MyInt是引用类型,它被放在了堆上,然后被栈上的一个指针所引用。
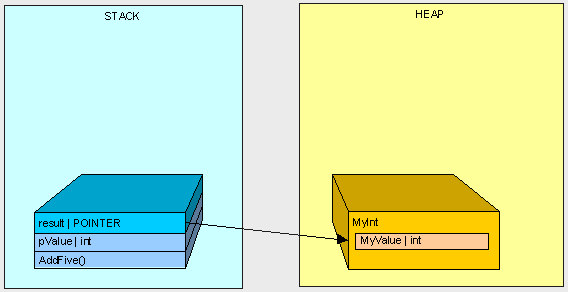
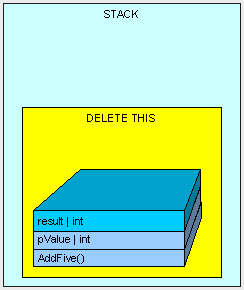
当AddFive()执行完成后,就会开始执行清除……
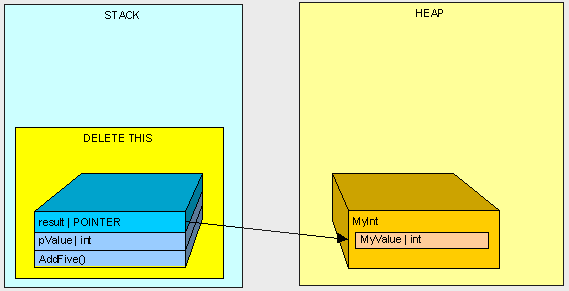
我们留下了孤零零的MyInt在堆里面(栈上已经没有指向MyInt的东西了)
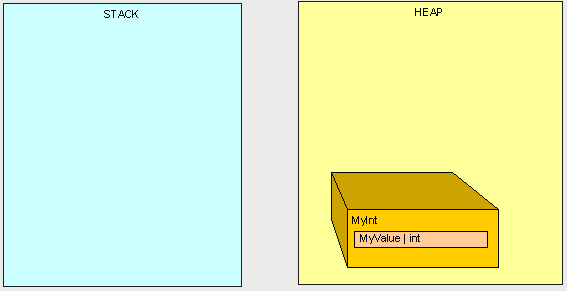
这时候,就该GC出马了。当托管堆中的内存空间达到一定的临界值时,GC就会启动。GC将会停止掉所有的线程,找出堆中所有不能再被主程序访问的对象然后删除掉。GC将会重新组织留在堆上的对象同时调整堆和栈上指向这些对象的指针。你可以想象的得到的,这个是相当的耗性能的,因此,当我们为了写出高性能的代码的时候,去关注哪些是在堆和栈上就显得尤为重要了。
OK… 很好,但是它们是如何影响我的呢?
问得好。
当我们使用引用类型的时候,我们实际上是处理指向该类型的指针;但我们使用值类型的时候,我们是在处理它本身,很清楚吧?
用例子来描述最清楚了。
如果我们执行下面的方法:
public int ReturnValue()
{
int x = new int();
x = 3;
int y = new int();
y = x;
y = 4;
return x;
}
返回值是3,很简单,对吧?
然而,如果我们用前面的MyInt类:
public class MyInt
{
public int MyValue;
}
然后执行下面的方法:
public int ReturnValue2()
{
MyInt x = new MyInt();
x.MyValue = 3;
MyInt y = new MyInt();
y = x;
y.MyValue = 4;
return x.MyValue;
}
返回值是?。。。4!
为什么呢?。。。为什么x.MyValue是4?看看我们在作什么然后看看是否合理:
在第一个例子中,一切如我们预期的:
public int ReturnValue()
{
int x = 3;
int y = x;
y = 4;
return x;
}
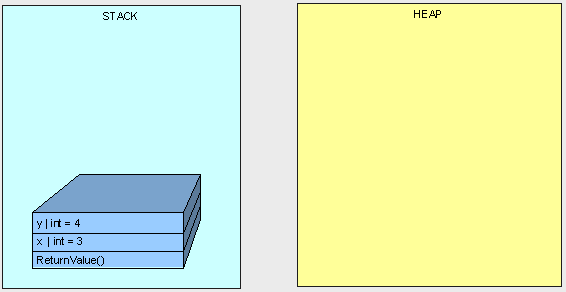
第二个例子中我们没有得到”3”,因为对象x和y都指向了堆上的同一个对象。
public int ReturnValue2()
{
MyInt x;
x.MyValue = 3;
MyInt y;
y = x;
y.MyValue = 4;
return x.MyValue;
}
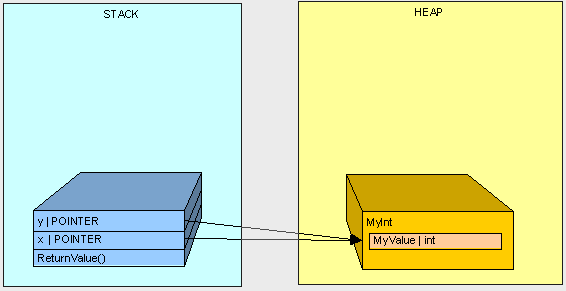
希望这有助于你理解值类型和引用类型之间的基本区别。同时也基本了解什么是指针以及什么时候使用它。在这个系列的下一部分,我们将进一步探讨内存管理,尤其是方法参数。
待续…