早上起来刷博客, 看到了一个很有意思的东西---Github Actions, 作者利用Github Actions制作了一个定时发送天气邮件的玩意儿, 一下子来了兴趣, 想了一会决定先写个小爬虫试试水~

然后一下午过去了, 目前做成了这个 :
https://github.com/Lincest/newsexpress
效果长这样 :

好啦, 接下来大概介绍下过程吧 :
Github Actions
首先简单介绍下Github Actions这玩意
GitHub Actions 是一个 CI/CD(持续集成/持续部署)工具,但也可用作代码运行环境
官方文档 : https://help.github.com/en/actions
功能非常强大, 文档我也只看了一些最基本的配置方面的内容, 我只用到了其中一点点
我把它理解为一个可以自动执行你放在仓库里项目的东西
配置方法
首先在github下建个仓库, 然后只要你建立这么一条路径以及一个action.yml文件就可以自动触发github actions

关于workflow文件 ( .yml文件 ) 的配置, 这里大概介绍一下 :
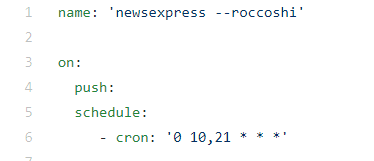
这里的on表示执行的时间, 比如我这里是每次push之后和每天的10,21点( 国际事件, 换成北京时间是早上5点和晚上6点 )执行, schedule的设置遵循POSIX cron 语法, 这里 是它的使用方法
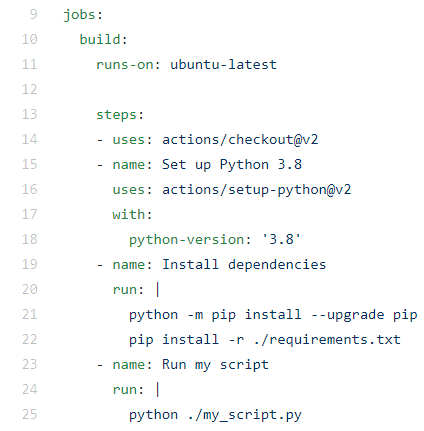
这里表示运行的系统为ubuntu最新版, python版本是3.8, 然后安装根目录下的依赖 ( 比如爬虫中的requests和beautifulsoup, 自己是不带的, 需要在运行机里pip安装 )
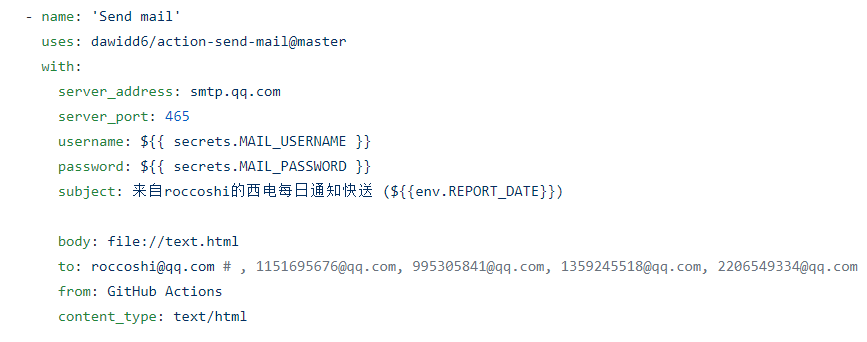
这里是发送邮件的机制, 我本来用的是163的smtp服务器, 然后下午push了五十多次后IP被封了(((

(我....)
这里的username和password要在setting里自己设置, 具体可以参考官方文档
然后在我写完脚本之后发现一个问题, 就是我的脚本需要依赖于update.txt文件判断信息是否更新, 而每次在处理机上运行的时候它不会帮我更新我的仓库, 所以还得自己写github的update方案:
百度了好大一圈, 最后这么实现了 :
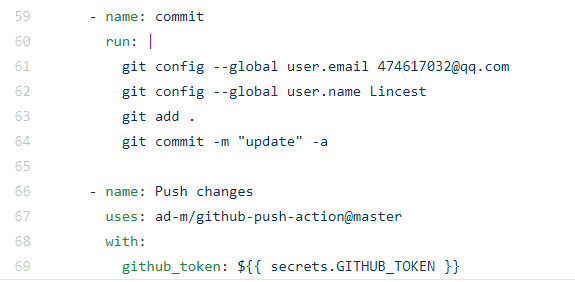
注意这里的uses和上面的uses大概可以理解为别人写的actions, 你只需要按他所说的设定规则就好.
这里 是github的官方市场, 里面都是别人写好的actions
爬虫
其实到上面基本就结束了, 毕竟github actions的使用才是重点, 至于我这个爬虫... 我只能说达到了目的, 但是代码写的稀烂, 毕竟只是写个demo, 重点在于了解actions的使用以后如果还想干别的肯定还会写其他脚本的.
# coding=utf-8
import requests
import re
from bs4 import BeautifulSoup as bs
def geturl(url):
try:
requ = requests.get(url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'})
requ.encoding = requ.apparent_encoding
req = requ.text
return req
except:
print("wrong")
if __name__ == '__main__':
x = 0
flag = 0
cnt = 0
retry=0
body = []
while(x <= 50) :
try:
url = 'https://jwc.xidian.edu.cn/'
text = geturl(url)
regex = re.compile(r'<a href="(.*?)" class="c49782"')
body = regex.findall(text)
print("successful")
x=100
except:
x+=1
continue
print(body)
with open("./update.txt", "r", encoding="utf-8") as f:
date = f.read()
newbody = []
if(date == body[0]):
flag = 1
for i in body:
if(date == i):
break # 到此为止, 之后的为之前内容
else:
newbody.append(i)
date = body[0]
body = newbody
with open("./update.txt", "w", encoding="utf-8") as f:
f.write(date)
if(flag==0):
with open("./text.html", "w", encoding="utf-8") as f:
f.write(r"<h1>今日更新内容 :<br><br><br> </h1>")
for i in body:
retry = 0
while(retry < 100):
try:
url = 'https://jwc.xidian.edu.cn/' + i
html = geturl(url)
soup = bs(html, 'html.parser')
title = soup.find(name="td", attrs={"class" : "titlestyle49757"})
text = soup.find(name="div", attrs={"class" :"v_news_content"})
#print(str(title))
# print(str(text))
f.write(r"<h1>"+str(title)+r"</h1>"+r"  url : <a href="+url+r">" + url + r"</a>")
f.write(str(text))
f.write(r"<br><br><br><br><br><br><br>")
retry = 1000
except:
retry+=1 # 重复尝试
else:
with open("./text.html", "w", encoding="utf-8") as f:
f.write(r"<h1>今天没有更新哦~~~</h1>")
f.close()
print("successful")
关于爬虫网上参考资料一堆
本来想直接用正则表达式提取字段展示就完了, 奈何re不给力半天没写好匹配, 就查了查beautifulsoup的使用方法然后用beautifulsoup十分钟解决了两小时没解决的问题
----好工具是十分重要的
然后在网页的请求上, 为了防止请求出错, 我设置了一个retry和一个x字段都是为了在出错时循环尝试的
然后就是update.txt了, 这里存的是网站最后一个通知的url链接, 下次一调用脚本时先打开update.txt, 判断当前最新的url是否与其是否相等, 如果相等就是没更新, 不相等的话就继续遍历当前的url集合, 直到找到更新的最后一条消息为止, 然后再把update更新一波就完了, 这俺想到的比较简单的解决方案
大概就扯这么多吧
