2007年,计费平台的一帮年轻人为了实现银行级的高可用、零错账的交易系统,加班加点讨论方案,长达几个月的反复头脑风暴与论证,终于提出了“TBOSS 7*24”容灾方案,并用了一年多时间落地推广后,斩获09年公司级技术突破奖,获得了Tony的首肯,从此开启了计费平台打造金融级数据库的探索之路。
一路走来,技术追求永无止境,打造一款更好用的高一致、高可用、高性能分布式数据库产品的初心从未改变,系统架构历经三代优化,2012年立项的第四代产品TDSQL,经过5年打磨与海量业务的实际运营优化,并与腾讯金融云合作产品化,正式以腾讯云金融级数据库对外输出,目前500+金融客户覆盖银行、保险、基金证券、消费金融、第三方支付、计费、物联网、政企等多个领域,尤其在多家银行的核心交易系统落地,标志着TDSQL真正突破成为一款金融级数据库产品,正是这里的突破,使得项目团队今年再次斩获公司级技术突破奖,这也是公司对团队一直专注金融级数据库底层研发耕耘的认可。
当然,道阻且长,随着硬件不断在更新,业务越来越多样且复杂,数据库领域还有许多新的挑战还需我们去攻克。本文尝试着记录下过去十年一路摸爬滚打过程中,团队的一些思考与总结,希望后面的路越走越宽!
从本质上来说,数据库产品要考虑的问题依然还是用户体验的问题!细化来说,数据库产品主要有两类直接用户,分别是开发人员与运维人员,核心就是他们要用得爽。
例如对开发人员来说,他们经常关心的问题有:
1、开发接口是不是标准的?是否提供完善的开发指引?
2、在故障灾难出现时,开发人员需不需要关心数据是否会丢失?需不需要写很复杂的容灾切换逻辑?
3、系统性能好不好,能不能扛住业务浪涌式压力?
4、系统是否足够开放等等?
而对于运维人员DBA来说,他们经常关心的问题如:
1、系统的常规操作是否有标准化的工具或页面直接使用?
2、系统是否足够透明,使得在异常时,能否快速的定位问题?
3、是否提供了完善的系统运营手册?
4、配套设施是否完善,例如监控系统、发布系统、冷备系统、审计系统等等?
当然也还有一类间接用户,那就是这些使用数据库的业务系统的真实用户,他们关心的问题有:
1、他们的支付、转账等操作是不是正常的,会不会不到账,多扣钱?
2、他们是否能够随时随地发起交易等等?
通常来说,在资源和时间有限的情况下,这几类用户的需求是要区分不同优先级的,甚至有时候是冲突的,所以我们一路走来,始终保持这样一个原则:在保障用户的基本诉求(数据不丢,不错账)的情况下,然后不断优化开发人员与运维人员的使用体验。例如我们的第一代产品“TBOSS 7*24”就是优先保证高可用、高一致性,确保用户数据不错不丢,但是极大的损害了开发人员与运维人员的体验,需要业务开发人员开发大量的容灾代码,运维人员需要维护大量的灾难模式等,也就是说很多工作交给了业务开发与运维人员。在后面的几代系统更迭中,我们就是不断的将功能下沉,让业务开发和运维越来越简单,必然的数据库本身会更加复杂一些。尽可能的在数据库层面去解决三类用户的诉求,也就变成了TDSQL的核心挑战。
TDSQL的核心挑战
TDSQL经历大大小小无数版本,始终面对的核心挑战是:
1、数据的可靠性。在任何灾难情况下,例如主机故障、网络故障等等,都不能存在数据丢失的情况。
2、系统的可用性。基于数据多副本的情况下,系统如何保证在一些异常情况下,快速恢复可用,把不可用时长降至最低。
3、高性能。首先,单机性能提升,对于海量业务来说,能够极大的降低服务器等成本;其次,性能指标也是用户最能直接感受到的指标之一,所以性能优化一直是我们优先级最高的任务之一。
4、扩展性。也就是通常说的分布式。其实在金融行业,之前对分布式这块的需求并不大,但是随着第三方支付的快速发展,给银行的一些系统造成了很大的冲击,例如双11、春节红包等活动,这类系统使用传统的IOE架构很吃力,所以他们也希望能采用分布式架构来解决这个问题。抛开从思维层面,分布式架构对传统金融IT行业人员的冲击外,其实从技术上来说,这里其实挑战很多,TDSQL也是在逐步的优化与解决,例如最复杂的两个点分布式事务与分布式Join操作。目前我们已经完成了分布式事务功能的发布,而分布式Join还在内测过程中。
5、配套工具。一个数据库软件要体验好,那么就不能仅仅提供几个核心的包,必须要有相应的运营管理工具、问题诊断工具、性能分析工具等,并且是一个开放的、标准的接口,只有这样大家才能更好更无缝的使用。
上面的几个问题,前面2个是基本功能的问题,在第一个版本就已经基本保障了,但是是不是就足够了?远远不够,路走得不够多,遇到的坎太少,碰到新的坑时,依然可能会摔跤。我们只有在足够丰富的场景中,通过大量的实践运营经验,使得自己的系统经历足够的磨练,才能使得系统的可用性和数据可靠性保持足够多的9。后面几个问题,本身也应该是一个持续优化的过程,TDSQL也一直在寻找最优雅的方式去解决,所以下面就从这几个问题,看看TDSQL具体是如何做的。
核心架构
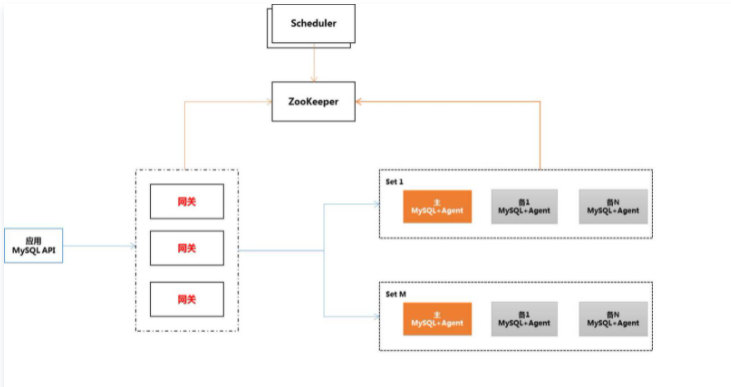
Set机制:TDSQL所有的高可用机制均是在Set之内实现,每个Set之内多个数据节点(1主N备),主备之间可以是基于Raft协议的强同步复制机制,也可以是异步复制机制。在主机出现故障的情况下,在调度模块的协助下,将挑选备机按照规定流程提升为主机,快速恢复业务,全程无需人工干预。在我们常规的使用过程中,通常是建议1主2备,主备之间强同步,这样在主节点故障情况下,能确保自动切换,RTO为40s,RPO为0。
水平扩容。分布式版本对外呈现为一个完整的逻辑实例,后端数据实际上是分布在若干Set上(独立的物理节点)组成。逻辑实例屏蔽了物理层实际存储规则,业务无需关心数据层如何存储,也无需在业务代码中集成拆分方案或再购买中间件,只需要像使用集中式(单机)数据库一样使用即可。同时支持实时在线扩容,扩容过程对业务完全透明,无需业务停机,扩容时仅部分分片存在秒级的只读(只读是实际在做数据校验),整个集群不会受影响。
分布式事务。TDSQL基于MySQL的XA实现了分布式事务机制,对各种异常处理做了充分的鲁棒测试,且相对于单机事务,性能损失仅30%。
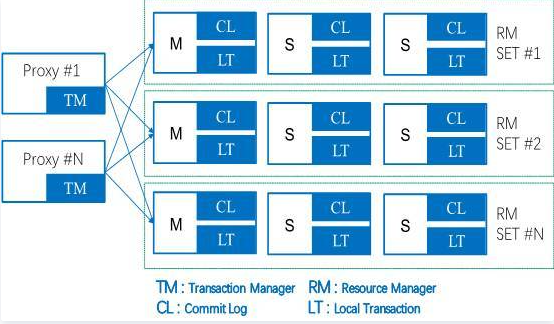
高级特性
二级分区。第一级即我们常说的水平拆分,原理是使用HASH算法,使得数据能均匀的分散到后端的所有节点;第二级分区使用RANGE算法,使得相关的数据能够落在一个逻辑分区,例如可以按时间分区(类似每天每周每月一个分区等),亦可以按业务特性分区(类似每个省市一个分区等)等等。二级分片可以均衡数据分布和访问,为快速一键扩容提供基础支撑,也可以满足快速删除数据等场景。
读写分离。基于数据库访问账号的读写分离方案,DBA能基于业务需求对账号设定相关参数,以确保既不会读取到过旧的数据,也不会影响写业务,且业务无需改动代码即可实现读写分离。这可以极大的降低业务运营成本。
此外,TDSQL还有全局唯一数字序列、统一参数管理、兼容MySQL函数,热点更新等众多高级特性,可满足各类业务需求。
内核优化
TDSQL在数据库内核这块的优化,主要集中在数据复制、性能、安全性等方面。
强同步机制。TDSQL针对金融场景的强同步机制,有效解决了MySQL原生半同步机制的问题:性能降低以及超时退化为异步。目前TDSQL在强同步模式下,系统的并发量(TPS/QPS)与异步模式已无差别,基本能做到性能无损失。
性能优化。
1)我们对MariaDB/Percona的线程池调度算法进行了优化,改进当系统处于重负载时,查询和更新请求在线程组间分布不均衡等极端情况。并且能够更好地利用计算资源,减少无谓的线程切换,减少请求在队列中的等待时间,及时处理请求。
2)组提交(Group Commit)的异步化。工作线程在其会话状态进入组提交队列后,不再阻塞等待组提交的Leader线程完成提交,而是直接返回处理下一个请求。
3) InnoDB Buffer Pool使用优化。例如全表扫描时,避免占满InnoDBBuffer Pool,而是只取一块来使用。
4) InnoDB 在MySQL组提交期间避免与组提交有mutex冲突的活动,例如InnoDB Purge,降低冲突,以提升性能。
类似的性能优化的点,还有不少,可能在某些场景下,单个点效果不明显,但是集合起来看,目前性能指标整体是不错的。基于SysbenchOLTP测试结果,相同的硬件及测试环境下,TDSQL性能相比原生版本提升85%。
安全增强。在安全方面做了大量优化及增强,包括数据文件加密、SQL防火墙、SSL接入、安全审计等。
此外,我们长期关注MySQL的三个分支版本:MariaDB、Percona、MySQL community,对于社区的新特性,也会定期的合入。
部署方案
TDSQL的强同步机制,本身是可以做到全球化部署的,但其实我们绝大部分客户无论是成本看,还是从业务场景看,都不需要做全球部署,常见的两地多中心基本都能满足需求。客户可以基于成本、自身业务数据的容灾要求,以及数据中心分布情况,选择不同的部署方案。TDSQL有针对性的在数据可靠性与可用性上做出权衡,做到灵活部署。目前常见的两种部署方案包括:
两地三中心
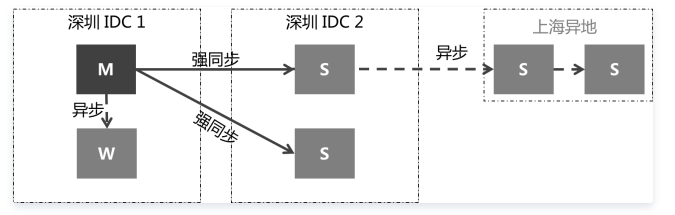
ZK分布在两地的三个中心内。
1、主IDC故障不会丢数据,自动切换到备IDC,此时蜕化成单个IDC的强同步,存在风险。
2、仅仅主机故障,在对比两个同城备节点及一个同城Watcher节点后,切换到数据最新的节点,优先选择同IDC的Watcher节点,尽可能减少跨IDC切换。
3、备IDC故障,通过另外一个城市的ZK能自动做出选举:
a) 备IDC确实故障,自动提升主IDC的Watcher节点为Slave,由主提供服务
b) 主备网络不通,与a)一样的处理方式
两地四中心
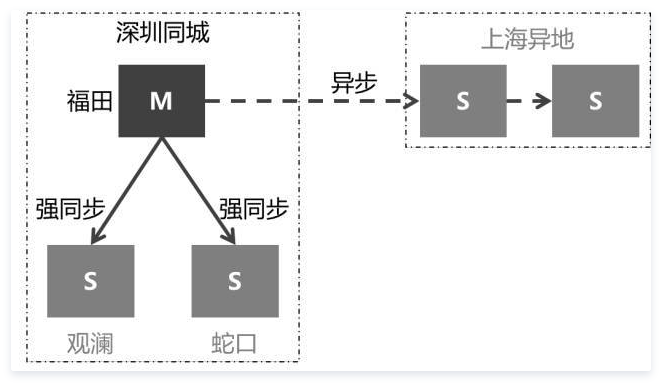
该方案适应性最强,但是对机房数量要求也高一些。
1、同城三中心集群化部署,简化同步策略,运营简单,数据可用性、一致性高
2、单中心故障不影响数据服务
3、深圳生产集群三中心多活
4、整个城市故障可以人工切换
周边配套
对于TDSQL的开发者和运维DBA来说,其配套设施、可维护性、透明性等至关重要,因为这决定了他们能否及时发现问题,针对问题能快速的做出变更及应对。所以TDSQL经过这两年的产品化工作,提供完善的周边配套体系,例如:
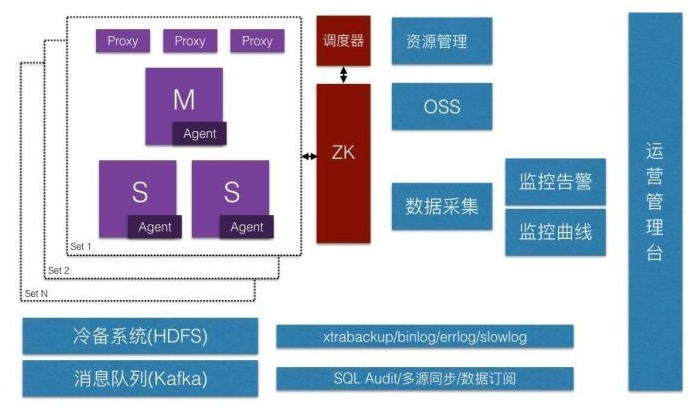
1)冷备系统。基于HDFS或其他分布式文件系统,可以做到自动备份,一键恢复。
2)消息队列。基于Kafka定制的Binlog订阅服务。基于该消息队列,TDSQL还提供了SQL审计、多源同步(相同表结构的数据合并到一张表)等服务。
3)资源管理。基于cgroup的对TDSQL实例进行编排,提高机器资源利用率。
4)OSS。对TDSQL的所有操作,例如扩容、备份、恢复、手动切换、申请(修改/删除)实例等操作,均提供统一的HTTP接口,可以有效自动化,降低人肉运维的风险。
5)数据采集。TDSQL所有的内部运营状态或数据,都能实时采集到,业务可以基于这些数据做定制分析或者构建运营监控平台。
6)监控平台。业务可以基于数据采集模块采集到的所有数据,对接自建的监控系统,亦可直接使用TDSQL自带的监控系统(需单独部署)。
7)管理平台。基于以上模块,TDSQL自带运营管理平台(内部平台代号赤兔),DBA基本上可以通过该管理台进行所有常规的运营操作,不再需要登录后台。
8)审计模块。审计模块通过对用户访问数据库行为的日志采集及分析,用来帮助客户事后生成合规报告、事故追根溯源,同时加强内外部数据库网络行为记录,提高数据资产安全。
以上这些模块可以自由组合,没有强依赖关系,运维人员也可以通过TDSQL的提供的接口自行对接自己现有的平台(如监控、告警、审计等)。
写在最后
TDSQL一路走来,在可靠性、可用性、性能、扩展性、配套设施等方面取得了一些里程碑式的成果,但是远没有到极致的用户体验。例如我们定位是OLTP数据库,适合高并发短事务的场景,但客户有时候需要在数据库上跑一些的OLAP操作,那这块我们能不能做?如何做?目前的分布式还无法真正做到一个单机数据库使用,那么在未来硬件发展情况下,能否做到呢?类似这些挑战还很多,数据库研发这块道阻且长,与大家共勉。