【区块链】
它可以被存储为flat file(⼀种包含没有相对关系记录的⽂件),或是存储在⼀个简单数据库中。⽐特币核⼼客⼾端使⽤Google的 LevelDB数据库存储区块链元数据。
对每个区块头进⾏SHA256加密哈希,可⽣成⼀个哈希值。通过这个哈希值,可以识别出区块链中的对应区块。同时,每⼀个区块都可以通过其区块头的“⽗区块哈希值”字段引⽤前⼀区块(⽗区块)。
虽然每个区块只有⼀个⽗区块,但可以暂时拥有多个⼦区块。每个⼦区块都将同⼀区块作为其⽗区块,并且在“⽗区块哈希值”字段中具有相同的(⽗区块)哈希值。⼀个区块出现多个⼦区块的情况被称为“区块链分叉”。
区块链分叉只是暂时状态,只有当多个不同区块⼏乎同时被不同的矿⼯发现时才会发⽣。最终,只有⼀个⼦区块会成为区块链的⼀部分,同时解决了“区块链分叉”的问题。
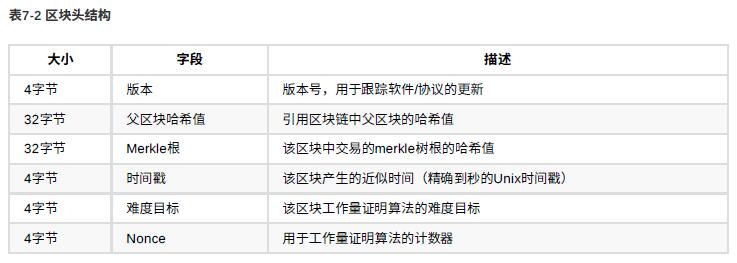
它由⼀个包含元数据的区块头和紧跟其后的构成区块主体的⼀⻓串交易组成。区块头是80字节,⽽平均每个交易⾄少是250字节,⽽且平均每个区块⾄少包含超过500个交易(意即每个区块都在125KB以上)。因此,⼀个包含所有交易的完整区块⽐区块头的1000倍还要⼤。
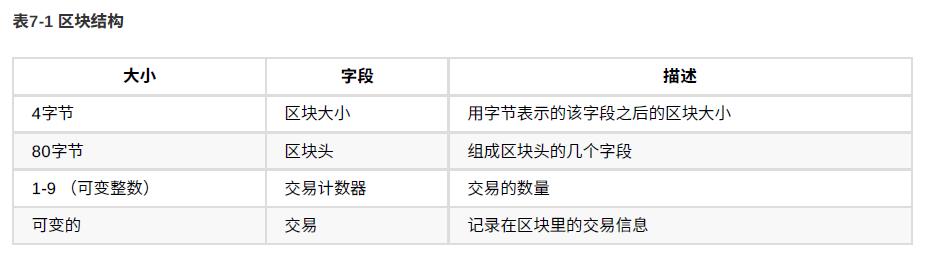
下面是区块头数据结构,其中难度、时间戳和nonce,与挖矿竞争相关。
区块主标识符是它的加密哈希值,⼀个通过SHA256算法对区块头进⾏⼆次哈希计算⽽得到的数字指纹。产⽣的32字节哈希值被称为区块哈希值,但是更准确的名称是:区块头哈希值,因为只有区块头被⽤于计算。
区块哈希值可以唯⼀、明确地标识⼀个区块,并且任何节点通过简单地对区块头进⾏哈希计算都可以独⽴地获取该区块哈希值。
请注意,区块哈希值实际上并不包含在区块的数据结构⾥,不管是该区块在⽹络上传输时,抑或是它作为区块链的⼀部分被存储在某节点的永久性存储设备上时。
相反,区块哈希值是当该区块从⽹络被接收时由每个节点计算出来的。区块的哈希值可能会作为区块元数据的⼀部分被存储在⼀个独⽴的数据库表中,以便于索引和更快地从磁盘检索区块。
2014年1⽉1⽇的区块⾼度⼤约是 278,000(27W),说明已经有278,000个区块被堆叠在2009年1⽉创建的第⼀个区块之上。
【创世区块】
创世区块的哈希值为:

创世区块包含⼀个隐藏的信息。在其Coinbase交易的输⼊中包含这样⼀句话“The Times 03/Jan/2009 Chancellor on brinkof second bailout forbanks.”这句话是泰晤⼠报当天的头版⽂章标题,引⽤这句话,既是对该区块产⽣时间的说明,也可视为半开玩笑地提醒⼈们⼀个独⽴的货币制度的重要性,同时告诉⼈们随着⽐特币的发展,⼀场前所未有的世界性货币⾰命将要
发⽣。该消息是由⽐特币的创⽴者中本聪嵌⼊创世区块中。
【区块的连接】
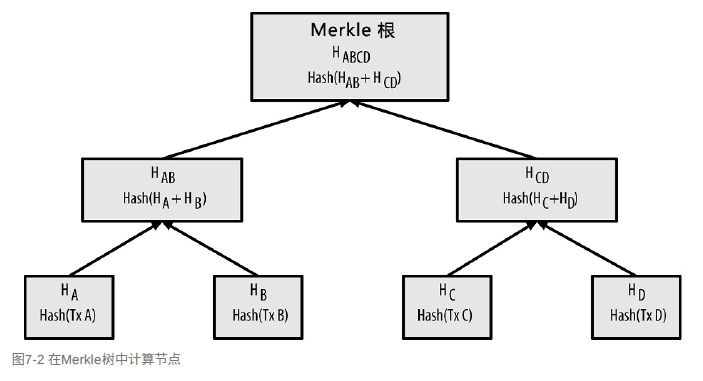
区块链中的每个区块都包含了产⽣于该区块的所有交易,且以Merkle树表⽰。
例如,交易 A 的哈希通过可以像下面这样计算:

而A、B的父结点可以这样计算:

如何检索某区块是否在 Merkle树中?当N个数据元素经过加密后插⼊Merkle树时,你⾄多计算2*log2(N)次就能检查出任意某数据元素是否在该树中。
构建 Merkle 树的代码:


#include <bitcoin/bitcoin.hpp> bc::hash_digest create_merkle(bc::hash_digest_list& merkle) { // Stop if hash list is empty. if (merkle.empty()) return bc::null_hash; else if (merkle.size() == 1) return merkle[0]; // While there is more than 1 hash in the list, keep looping… while (merkle.size() > 1) { // If number of hashes is odd, duplicate last hash in the list. if (merkle.size() % 2 != 0) merkle.push_back(merkle.back()); // List size is now even. assert(merkle.size() % 2 == 0); // New hash list. bc::hash_digest_list new_merkle; // Loop through hashes 2 at a time. for (auto it = merkle.begin(); it != merkle.end(); it += 2) { // Join both current hashes together (concatenate). bc::data_chunk concat_data(bc::hash_size * 2); auto concat = bc::make_serializer(concat_data.begin()); concat.write_hash(*it); concat.write_hash(*(it + 1)); assert(concat.iterator() == concat_data.end()); // Hash both of the hashes. bc::hash_digest new_root = bc::bitcoin_hash(concat_data); // Add this to the new list. new_merkle.push_back(new_root); } // This is the new list. merkle = new_merkle; // DEBUG output ------------------------------------- std::cout << "Current merkle hash list:" << std::endl; for (const auto& hash: merkle) std::cout << " " << bc::encode_hex(hash) << std::endl; std::cout << std::endl; // -------------------------------------------------- } // Finally we end up with a single item. return merkle[0]; } int main() { // Replace these hashes with ones from a block to reproduce the same merkle root. bc::hash_digest_list tx_hashes{ { bc::decode_hash("0000000000000000000000000000000000000000000000000000000000000000"), bc::decode_hash("0000000000000000000000000000000000000000000000000000000000000011"), bc::decode_hash("0000000000000000000000000000000000000000000000000000000000000022"), } }; const bc::hash_digest merkle_root = create_merkle(tx_hashes); std::cout << "Result: " << bc::encode_hex(merkle_root) << std::endl; return 0; }
下图展示了Merkle树的效率。因为上文提到每个交易不小于250Byte,所以下图中:
1)区块近似大小=交易数量*250Byte。
2)路径数量 = log2(交易数量)。
3)路径字节 = 路径数量 * 32Byte。因为每个路径为32Byte。