原文链接:http://tecdat.cn/?p=25376
原文出处:拓端数据部落公众号
Metropolis-Hastings 算法对概率分布进行采样以产生一组与原始分布成比例的轨迹。
首先,目标是什么?MCMC的目标是从某个概率分布中抽取样本,而不需要知道它在任何一点的确切概率。MCMC实现这一目标的方式是在该分布上 "徘徊",使在每个地点花费的时间与分布的概率成正比。如果 "徘徊 "过程设置正确,你可以确保这种比例关系(花费的时间和分布的概率之间)得以实现
为了可视化算法的工作原理,我们在二维中实现它
-
-
plt.style.use('ggplot')
首先,让我们创建并绘制任意目标分布
tart = np.append-
plt.hist
-
plt.text
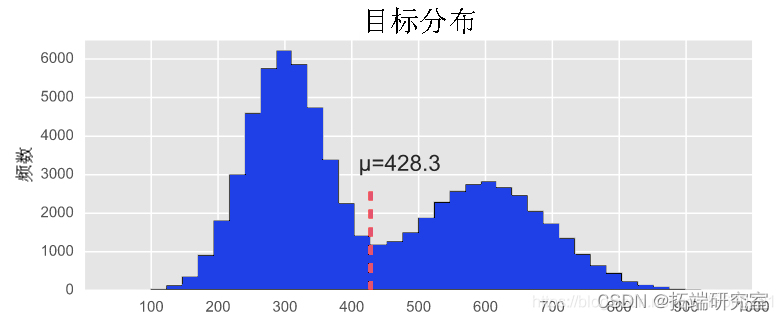
现在让我们写出算法。请注意,我们将原始数据分箱计算给定点的概率。这是算法如何工作的粗略概念
- 选择分布上的一个随机位置
- 提议分布上的一个新位置
- 如果提议的位置比当前的位置有更高的相对概率,就跳到这个位置(即把当前位置设置为新位置)
- 如果不是,也许还是跳。仍然跳的概率与新位置的概率低多少成正比
- 返回算法所到过的所有位置
-
def gees:
-
-
daa = d.astype
-
np.bincount # 产生一个范围为(i,i+1)的计数数组
-
np.array([])
-
-
crnt = int
-
for i in xrange(n_ms):
-
trs = np.append
-
# 最终创建一个函数,选择一个好的跳跃距离
-
# 如果当前位置的p很低,就把跳转的距离变大
-
poo = int
-
# 确保我们不离开边界
-
while rood data.max or ppsd < data.min:
-
pood = int
-
-
-
if a > 1:
-
cuent = prosed
-
else:
-
if np.random.random<= a:
-
curnt = ppse
traces = get_traces(target, 5000)-
# 绘制目标分布图和轨迹分布图
-
-
plt.hist
-
plt.subplot(2,1,2)
-
plt.hist
-
plt.tight_layout
-
plt.show
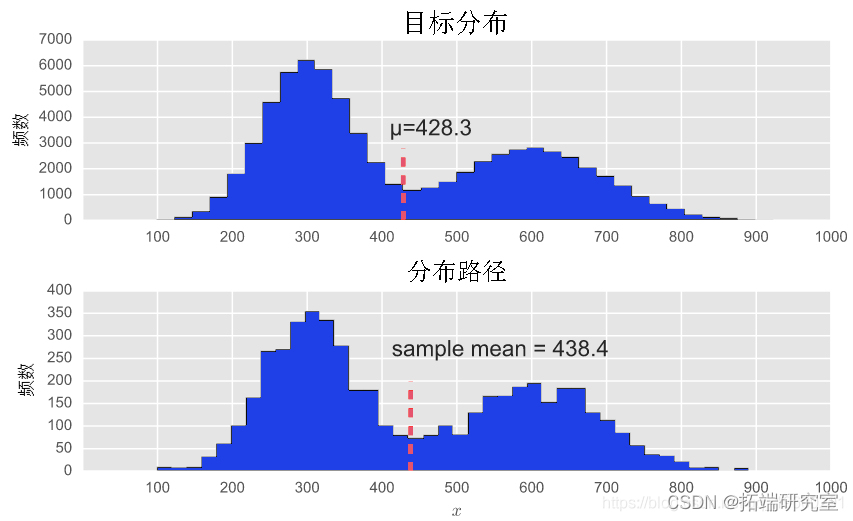
不仅轨迹的分布非常接近实际分布,样本均值也非常接近。绘制的样本点少于 5000 个,我们非常接近于近似目标分布的形状。

最受欢迎的见解
4.R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归