由于电商网站的数据的实时性要求,数据分析时一般直接从网页爬取。因此使用爬虫的方法显得十分重要。R作为数据分析的软件,可以直接对爬取的数据进行后续处理,加上上手快的特点,是电商网站数据爬取和分析的好工具。
下面以?http://cn.shopbop.com/为例 简单分享下使用Rcurl对网站进行数据爬取的过程。
首先需要在Rgui里安装需要的软件包
require("RCurl")
require("rjson")
require(stringr)
require(XML)
#得到网页地址,并将其转换成html源码
url = "http://cn.shopbop.com/"
doc = getURL(url)
txt = htmlParse(doc, asText = TRUE)
print(txt)
#由于获取网页中商品数据需要对html源码结构进行分析,因此可以直接在浏览器中查看后,再到R中进行编辑

在源码中很容易找到网站导航中子网站的网址

#因此可以通过xmlPath语言找到相应子网站的节点
a <- getNodeSet(txt, path = "//a[@class = 'parent topnav-logged-in ']")#找到子网页的xml路径?

如果得到的中文有乱码,则需要对编码进行转换
b <- sapply(a,xmlValue)
c <- iconv(b,"utf-8","gbk")
c
否则 可以通过xmlGetAttr函数 得到所需的attributes
?d <- sapply(a,xmlGetAttr , "href")#获取子网页
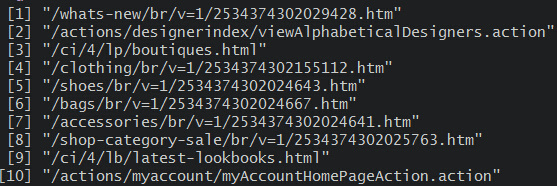
??由于得到的只是子网页的路径,要获取子网页的数据 需要用paste链接网站根目录地址
d1=paste(url,d[1],sep="" )
?#对于批量爬取商品的信息还需要获取商品展示子网页的页数
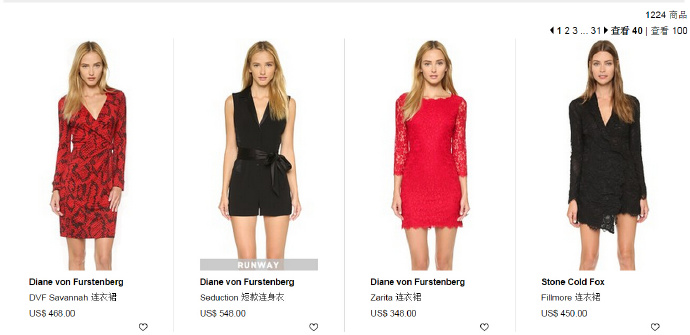
?每页显示40个商品,一共有1200个商品。
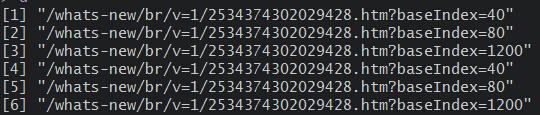
???通过网址,我们很容易了解商品展示页的地址规则。
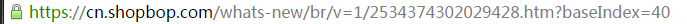
#因此,可以通过一个简单的循环来获取所有网页的地址,从而获取每个网页的所有商品信息。???
a <- getNodeSet(txt, path = "//span[@class = 'page-number']")#找到子网页的xml路径?(部分代码省略)
d <- sapply(a,xmlGetAttr , "data-number-link")#获取子网页中的目录
pagenum=strsplit(d,"=")
maxpagenum=0;
for(i in 1:length(pagenum)){
maxpagenum[i]= pagenum[[i]][3]
}
maxpagenum=max(as.numeric(maxpagenum))
#[1] 1200
#在获得所有网页后,获取所有商品的信息就变得简单了,只要循环对每个网页的信息进行xml关键字的爬取
#名称信息?
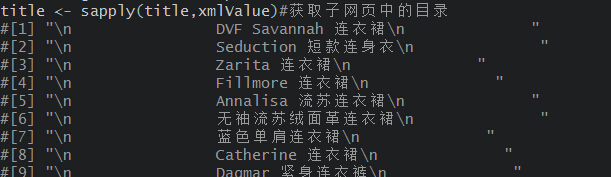

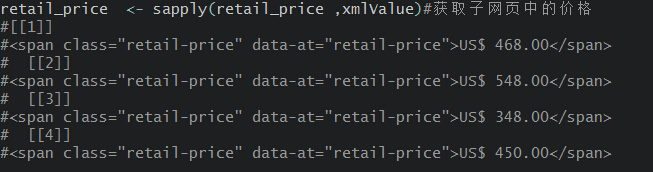
?通过文本处理和输出,就可以将其进行保存和后续的数据分析。