Hadoop MapReduce
这样我们就可以把MapReduce理解为,把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。这就回到了最初,终于知道MapReduce为何要这样设计。
将一个任务分成小任务,并且完成子任务的计算,这个过程叫map;而将中间结果合并成最终结果,这个过程叫走reduce。
Hadoop - MapReduce
简介
一种分布式的计算方式指定一个Map(映#x5C04;)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
Pattern
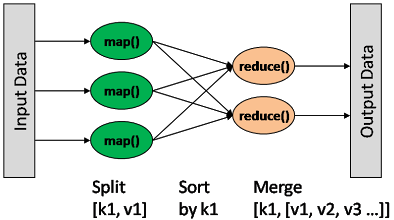
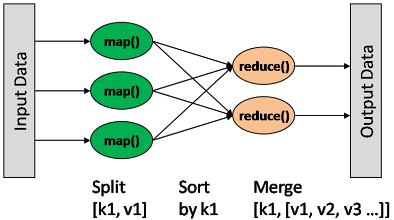
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
Map输出格式和Reduce输入格式一定是相同的
基本流程
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中
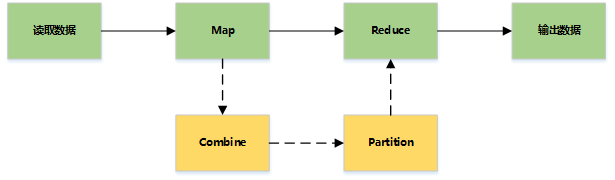
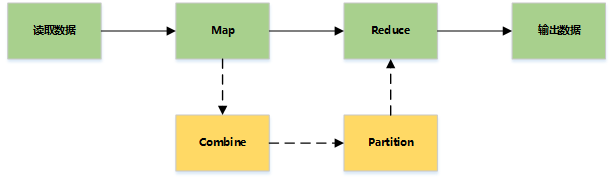
详细流程
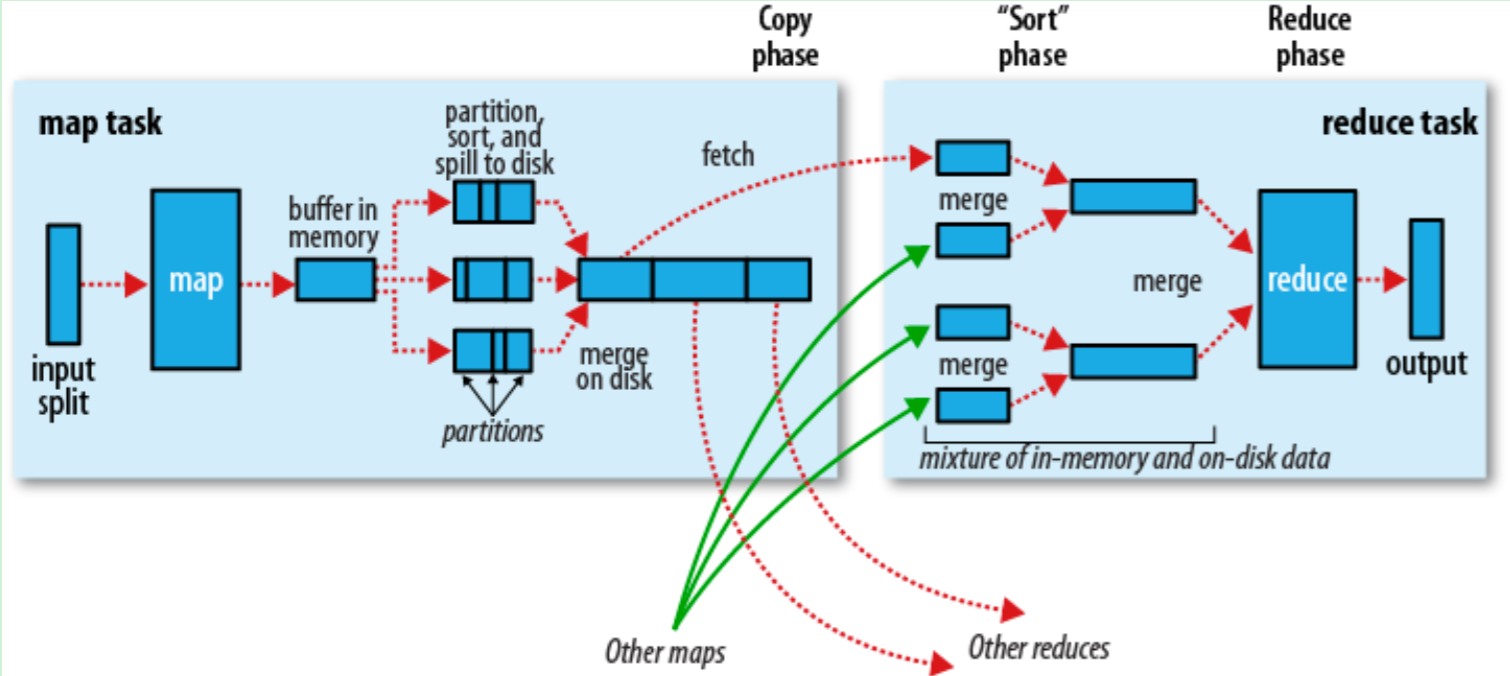
多节点下的流程

主要过程


Map Side
Record reader
记录阅读器会翻译由输入格式生成的记录,记录阅读器用于将数据解析给记录,并不分析记录自身。记录读取器的目的是将数据解析成记录,但不分析记录本身。它将数据以键值对的形式传输给mapper。通常键是位置信息,值是构成记录的数据存储块.自定义记录不在本文讨论范围之内.
Map
在映射器中用户提供的代码称为中间对。对于键值的具体定义是慎重的,因为定义对于分布式任务的完成具有重要意义.键决定了数据分类的依据,而值决定了处理器中的分析信息.本书的设计模式将会展示大量细节来解释特定键值如何选择.
Shuffle and Sort
ruduce任务以随机和排序步骤开始。此步骤写入输出文件并下载到本地计算机。这些数据采用键进行排序以把等价密钥组合到一起。
Reduce
reducer采用分组数据作为输入。该功能传递键和此键相关值的迭代器。可以采用多种方式来汇总、过滤或者合并数据。当ruduce功能完成,就会发送0个或多个键值对。
输出格式
输出格式会转换最终的键值对并写入文件。默认情况下键和值以tab分割,各记录以换行符分割。因此可以自定义更多输出格式,最终数据会写入HDFS。类似记录读取,自定义输出格式不在本书范围。
博客出处W3c: https://www.w3cschool.cn/hadoop/flxy1hdd.html 。