#include<iostream>表示在最终编译之前使用iostream文件的内容替换该编译指令。
using namespace std;
所谓namespace是指标识符的各种可见范围,c++标准程序库的所有标识符都被定义在std的namespace中。
<iostream>和<iostream.h>本质上是不一样的,在include文件中可以看到,两个是不同的文件。后缀为.h 的文件c++标准已经不支持了,早些时候的实现将标准库功能定义在全局空间里,声明在.h后缀的头文件中,c++标准为了将其与c区分开来,不再支持.h文件
当使用<iostream.h>时相当于在c中调用库函数,使用的是全局命名空间,也就是早期c++实现,当使用<iostream>时,该文件没有定义全局命名空间,必须使用namespace std这样才能正确使用cout。
所谓namespace,是指标识符的各种可见范围。
c++标准库中的所有标识符都被定义于一个名为std的namespace中,由于namespace的概念,使用c++标准库的任何标识符时,可以有以下三种选择:
1、直接指定标识符,例如std::ostream而不是ostream,完整语句如下:
std::cout<<std::hex<<3.4<<std::endl;
2、使用using关键字。
using std::cout;
using std endl;
以上程序可以写成
cout<<std::hex<<3.4<<endl;
3使用最方便的当然是using namespace std;
对于
char ch;
cin>>ch;
cout<<ch;
这么一个简单的程序当输入的字符为M时,打印出的也为M(废话啊)但是在内存中77是存储在变量ch中的值,这种转换来自于cin,在输入的时候cin将M转换为77,输出的时候cout将77转换为,cin和cout的转换是根据数据的类型进行变化的,因为cout检测出ch为char类型,所以输出为M。
运算符的优先级和结合性
对于int n=3+4*5来说,操作数4旁边有两个运算符+和*,当多个操作符作用于一个操作数时,c++使用优先级规则来决定首先使用哪个运算符,因此此处应该是先算乘法再算加法
对于int n=120/4*5来说,以上规则又不适用,当两个运算符优先级相同时,c++将看操作数的结合性是从左往右还是从右往左,此处乘除法是从左往右,这说明应当先除再乘
对于int n=20*5+24*6来说,可以肯定的是必须在做加法之前完成两个乘法,至于两个乘法实现的先后c++把这个问题留给了实现,让他来决定系统中的最佳顺序。此处如果认为结合性表明应先做左侧的乘法是错误的,因为两个操作符并没有作用于同一个操作数。
只有在定义数组的时候才能使用初始化,此后就不能再使用了,也不能将一个数组赋值给另一个数组,但是可以使用下标分别给数组中的元素赋值
如果只对数组的部分元素进行初始化,则其他元素自动被编译器赋值为0,如果想把数组全部赋值为0则可以int arr[100]={0};但是如果int arr[100]={1};则表示第一个元素被赋值为1其他元素被赋值为0
在数组进行初始化的时候‘=’是可以被省略的,如float arr[100] {};
字符串常量不能与字符常量互换,字符串常量(如'S')是字符串编码的简写表示,在ASCll系统上,'S'只是83的另一种写法,但是"S"不是字符常量,它表示的是两个字符(字符S和�)组成的字符串,"S"实际上表示的是字符串所在的内存地址,因此char ch="S"是非法的
get()和getline()的区别:
两者都是读取一整行,他们接受的参数相同,解释参数的方式也相同,但是get并不再读取并丢弃换行符,将换行符留在输入队列中,而getline则在读取换行符之后将它丢弃。但是可以使用以下方式读取两个字符串之间的换行符
cin.get(name,Arrsize);
cin.get();
cin,get(sessert,Arrsize);
这样就可以读取并丢弃两个字符串之间的换行符
结构体
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//同时又声明了结构体变量s1,这个结构体并没有标明其标签
struct {
int a;
char b;
double c;
} s1;
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//结构体的标签被命名为SIMPLE,没有声明变量
struct SIMPLE {
int a;
char b;
double c;
};
可以同时完成定义结构和创建结构变量的工作
struct perks{
int number;
string name;
}smith,jones
甚至可以
struct perks{
int number;
string name;
}glitz={
7,
"Packard"
}
共用体
共用体是一种数据格式,它能给存储不同类型,但是只能同时存储其中的一种类型,例:
union one4all{
int int_val;
long long_val;
double double_val;
};
one4all pail;
pail.int_val=15;
cout<<pail.int_val;
pail.double_val=1.22;
cout<<pail.double_val;
由于共用体每次只能存储一个值,因此他必须有足够的空间来存储最大的成员,所以共用体的长度为其最大成员的长度。共用体的用途之一是当数据项使用两种或者更多格式(但不会同时使用)时可以节省空间。
枚举
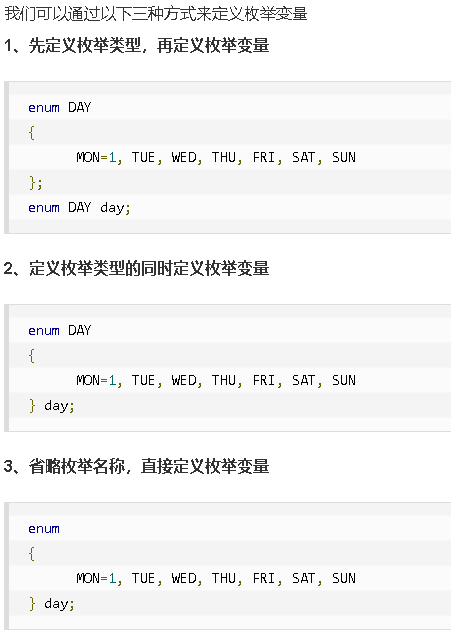
#include<stdio.h>
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
int main()
{
enum DAY day;
day = WED;
printf("%d",day);
return 0;
}
输出:3
在C语言中,枚举类型是被当作int或者unsigned int 类型来处理的,所以按照C语言规范是没办法便利枚举类型的
不过可以这样
#include<stdio.h>
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
} day;
int main()
{
// 遍历枚举元素
for (day = MON; day <= SUN; day++) {
printf("枚举元素:%d
", day);
}
}
在c++中创建指针时,计算机会分配用来存储地址的内存,但是不会分配用来存储指针所指向的数据的内存。
long *fellow;
*fellow=223323;
在这个例子中计算机会为指针fellow分配内存,但是不会fellow指向的数据分配内存,大致意思就是你知道指针fellow的位置,但是不知道fellow的指向,此时223323就会被放在这个不知具体位置的地址上。
使用delete时,后面要加上指向内存块的指针p(这些内存块最初使用new分配的);这将释放p指向的内存,但是不会删除p指针本身,可以将p重新指向另一块新的内存。在使用指针时一定要配对使用delete和new,否则会导致内存泄漏,也就是说被分配的内存再也无法使用了。更不要尝试释放已经释放的内存,这将导致不确定的结果。另外不能使用delete来释放声明变量所获得的内存。然而对于空指针使用delete是安全的。
.和->的区别
如果结构标识符是结构名,则使用句点运算符;如果标识符是指向结构的指针,则使用箭头运算符。
关系运算符的优先级比算术运算符低:
x+3>y-2 其实等价于(x+3)>(y-2)
假设要知道字符数组中的字符串的值是不是mate,如果word是数组名,则word=="mate"并不是想象的判断两个字符串是否相等,要知道数组名表示的额是数组的起始地址,同样用引号阔气的字符串常量也是其地址,所以即使word里面存放的内容是mate,依旧不会相等。此时可以使用strcmp()函数来比较,该函数可以接受两个字符串地址作为参数,这意味着参数可以是指针,字符串常量或者字符数组名,如果两个字符串相同,则返回0,如果第一个字符串字母顺序排在第二个字符串之前则返回一个负数值,相反则是正数。
假设arr是一个数组,ar是指向数组第一个元素的指针则:
arr[i]==*(ar+i);
&arr[i]==ar+i;
将指针(包括数组名)加1,实际上是加上了一个与指针之乡的类型的长度(以字节为单位)相等的值
与数据相似,函数也有其地址,函数地址是存储其机器语言代码的内存的开始地址,比如对于函数think(),think即使该函数的地址。声明指向函数的指针时,必须指定指针指向的函数类型。这意味着声明应指定函数的返回类型以及函数的参数列表,例如一个函数声明为double pam(int);则正确的指针类型声明如下:double (*pf)(int);这与pam()声明类似,浙江pam替换为了(*pf)由于pam是函数,因此(*pf)也是函数,如果(*pf)是函数,则pf就是函数指针。通常要声明指向特定类型的函数的指针,可以首先编写这种函数的原型,然后用(*pf)(考虑到优先级务必使用())替换函数名,这样pf就是这类函数的指针。
程序运行时,操作系统将指令载入到计算机内存中,计算机按照顺序执行指令,常规函数调用时会使程序跳到另一个地址,并在函数结束时返回。(在调用函数时,已经将当前地址存储在栈中,返回就是直接去栈中找地址)。但是对于内联函数来说就不存在地址跳跃,而是直接将相应的函数存放在相应的内存。好处是这种调用会节约时间,但是坏处是会很浪费内存。因此在使用的时候应该考虑函数调用的时间是否比函数执行的时间长很多。
使用这种特性就要在函数的声明或定义之前加上inline。但是需要注意的是当程序员把函数声明为内联函数的时候,编译器并不一定会答应,他可能认为函数过大或者函数调用了自己(内联函数是不能递归调用的)
对于
int rats=101;
int & rodents=rats;
可以把rat当作rodents的别称,即两个是同一变量的不同称呼。但是引用不同于指针,虽然他可以:
int rats=101;
int & rodents=rats;
int * prats=&rats;
此处rodents和*prats都可以和rats互换,而表达式&rodents和prats都可以同&rats互换。但是引用必须在声明引用的时候将其初始化,
默认参数指的是当函数调用中省略了实参时自动使用的一个值,例如void wow(int n=3);则在直接调用wow()时,就是等于调用wow(3),如果传递的有其他值,则将3覆盖。
对于带参数列表的函数, 必须从右往左调价默认值,也就是说要为某个参数设置默认值,必须为他右边的所有参数提供默认值。
int harpo(int n,int m=4,int j=5)//valid
int harpo(int n,int m=4,int j)//invlid
beeps=harpo(2)//harpo(2,4,5)
beeps=harpo(1,8)//harpo(1,8,5)
实参按从左到右的顺序一次被赋值给相应的形参,而不能跳过任何参数所以beeps=harpo(3, ,8)是非法的
函数多态(函数重载)能够使用多个同名的函数
void print(const char *str,int width); // *1
void print(double d,int width); // *2
void print(long l,int width); // *3
void print(int i,int width); // *4
void print(const char *str); // *5
当print(3210L,6)时,它不会和任何原型匹配,因为c++会尝试将变量强制转换,但是强制转化之后有三个可以进行匹配的原型,这种情况下c++将拒绝这种函数调用。
还有就是double cube(double x);
double cube(double & x);从编译器的角度来看是无发确认究竟应该使用哪个原型,
注:将非const值赋值给const是合法的,但是反之则是非法的。
同时 long gronk(int n,float m);
double gronk(int n,float m)这样是不允许的,返回值可以不同,但是参数列表也必须不同,重载的识别对象是参数列表而不是返回值。
模板函数是通用函数描述,它们使用泛型来定义函数,其中的泛型可用具体的类型替换,这样避免在实现两个int交换和两个double交换时重载,减少了工作量。
template <typename AnyType>
void Swap(AnyType &a,AnyType &b){
AnyType temp;
temp=a;
a=b;
b=temp;
}
第一行指出演建立一个模板,并将类型命名为AnyType。关键字template和typename是必须的,除非可以使用关键字class代替typename,
template<typename T>
void Swap(T &a,T &b);//这是函数的声明
void Swap(T &a,T &b){
temp=a;
a=b;
b=temp;
}//这是函数的定义
当函数接收两个int参数的时候编译器自动将函数变为:
void Swap(int &a,int &b){
temp=a;
a=b;
b=temp;
}
同样模板函数一样可以重载。函数模板本身并不生成函数,他只是从c++编译具体函数的模子,不是编译一份满足多重需要,而是为每一种替换他的函数编译一份。
关键字private和public描述了对类成员的访问控制,使用类对象的程序都可以直接访问公有部分,但是只能通过公有成员函数或友元函数来访问对象的私有成员,类对象的默认访问控制是private。
成员函数的函数头使用作用域运算符解析(::)来指定函数所属的类,同样类方法也可以使用private进行修饰。当我们使用void Stock::update(double price)意味着我们定义的update()函数是Stock类的成员还意味着我们可以将另一个类的成员函数也命名为update。作用域解析运算符确定了方法定义对应的类的身份。Stock类的其他成员可以不使用作用域解析运算符就可以使用update()函数。
定义位于类声明中的函数都将自动成为内联函数,类声明将短小的成员函数作为内联函数,如果愿意也可以在类声明之外定义成员函数并使之成为内联函数。
class Stock{
private:
void set_tot();//在此次定义
....
}
inline void Stock::set_tot(){
statements...
}
内联函数的使用规则要求在每个使用它们的文件中都对其进行定义,确保内联定义对多文件程序中的所有文件都可用最简便的方法是将内敛定义放在定义类的头文件中。
创建的每个对象都有自己的存储空间,用于存放其内部变量和类成员,但是同一个类的所有对象共享同一组类方法。即每个方法只有一个副本。比如kata.shares将占据一个内存块,joe.shares也要占用一块内存,但是kate.show()和joe.show()都调用同一个方法,也就是说他们将执行同一个代码块,只是这些代码用于不同的数据。
构造函数:
当且仅当没有定义任何构造函数时,编译器才会提供默认构造函数,为类定义了构造函数后程序员就必须为它提供默认构造函数。如果提供了非默认构造函数但是没有提供默认构造函数将会出错。
析构函数的调用是由编译器来决定的,通常不应该在代码中显示的调用析构函数。如果创建的是静态存储类对象,则其析构函数将在程序结束时自动被调用。如果创建的是自动存储类对象,则其析构函数将在程序执行完代码块时自动被调用,如果对象是通过new创建的,则它将驻留在栈内存或者自由内存区,当使用delete来释放内存是,其析构函数将自动被调用,最后程序可以创建临时对象来完成特定操作,在这种情况下程序将在结束对该对象的使用时自动调用其析构函数。
this表示的是对象的地址而不是对象本身,*this才是对象本身
在对运算符进行重载的时候:
Time Time::operate+(const Time &t) const{
statement....
return TimeType;
}
此时可以使用运算符表示法:total=coding+fixing;//fixing和coding都是Time类型
运算符左侧的对象(coding)是调用对象,运算符右边的对象是作为参数被传递的对象。
如果t1,t2,t3,t4都是Time类的对象,则t4=t1+t2+t3;是合法的
定价于t4=t1.operator +(t2.operator+(3));
运算符重载的限制:
1、重载后的运算符必须至少有一个操作数是用户定义类型,这是为了防止用户为标准类型重载运算符。比如不能将-重载为两个double类型的和。
2、使用运算符时不能违反运算符原来的语句规则。例如不能将求模运算符重载成四用一个操作数:%x;同样不能修改运算符优先级。
3、不能创建新的运算符,比如将**定义为求幂
4、=(赋值运算符)、()(函数调用运算符)、[](下标运算符)、->(指针运算符)只能通过成员函数进行重载而不能使用非成员函数进行重载。
在对Time类进行重载的时候,可以将Time对象乘以实数,对于两个Time类A、B。A=B*2.75是可以的,对于编译器来说它将转换为A=B.operator*(2.75)但是A=2.75*B就没法通过编译,此时可以通过非成员函数进行操作,非成员函数不是由对象调用的,他使用的所有值都是显示参数。这样编译器就可以将A=2.75*B;和A=operator*(2.75,B);调用匹配。该函数的原型如下
Time operator*(double m,const Time &t)(此处我不是太明白的是如果参数顺序不一致还能否进行调用)
但是这种情况的弊端是不能访问私有数据,因此引入了友元函数。
friend Time operator *(double m,const Time &t)
该声明意味着两点:
1、虽然operator*()函数是在类声明中声明的,但是它不是成员函数,因此不能使用成员函数运算符来调用;
2、虽然operator*()函数不是成员函数,但是他与成员函数的访问权限相同
因为友元函数允许非成员函数访问私有变量,咋一看似乎违反了OOP数据隐藏的规则,其实不然,应该将友元函数看作类的扩展接口的组成部分。从概念上看,double乘以Time和Time乘以double是完全相同的。也就是说前一个要求友元函数和后一个使用成员函数是C++语法的结果而不是概念上的差别。
另外只有类声明可以决定哪个函数是友元函数,因此类声明仍控制了哪些函数可以访问私有数据,总之类方法和友元函数只是表达类接口的两种不同机制。
构造函数实现了从某种类型到类类型的转换,要进行相反转换必须使用特殊的c++运算符函数---转换函数
转换函数是用户定义的强制类型转换,可以像使用强制类型转换那样使用它们
比如实例化对象Person p(2.26);
double tall=double(p);
double tall=(double)p;
当编译器发现左边是Person类型,右边是double类型,它将查看是否定义了与此匹配的转换函数
转换函数必须注意以下几点
1、转换函数必须是类方法
2、转换函数不能指定返回类型
3、转换函数不能有参数
其命名为operator typeName();
例如以上转换函数应该命名为operator double();
不能在类声明中初始化静态成员变量,这是因为声明描述了如何分配内存,但不分配内存。可以使用这种格式来创建对象,从而分配和初始化内存。对于静态类成员,可以在类声明之外使用单独的语句来进行初始化,这是因为静态类成员是单独存储的,而不是对象的组成部分。另外,初始化语句指出了类型,并使用了作用域运算符
,但是没有使用关键字static。
但是如果静态成员是整形或枚举型const,则可以在类声明中初始化。
static int num;//这是在类Person中定义
int Person::num=0;//在类声明之外使用单独的语句来进行初始化
在构造函数中使用new来分配内存时,必须在相应的析构函数中使用delete来释放内存,如果使用new[]来分配内存,则应使用delete[]来释放内存。
派生类在继承基类之后需要在自身添加:
1、派生类自己的构造函数
2、派生类可以根据自己的需要额外添加数据成员和成员函数
派生类不能直接访问积累的私有成员,而必须通过基类方法进行访问,具体来说,派生类的构造函数必须使用基类的构造函数。创建派生类对象的时候,程序首先创建基类对象,这意味着基类对象应当在程序进入派生类构造函数之前被创建。释放对象的顺序与创建对象的顺序相反,即首先执行派生类的析构函数,然后自动调用积累的析构函数。
派生类与基类之间有一些特殊关系,其中之一是派生类对象可以使用基类的方法,条件是方法不是私有的,另外两个是:基类指针可以在不进行显式类型转换的情况下指向派生类对象;基类引用可以在不进行显式类型转换的情况下引用派生类对象。然而基类指针只能用于调用基类方法。
c++允许将派生类对象和地址赋值给基类引用和指针,但是不允许将基类对象和地址赋值给派生类对象个指针。
c++有3种继承方式:公有继承、保护继承和私有继承。公有继承是最常见的一种方式,即派生类对象执行的任何操作也可以对派生类对象执行。
经常在基类中将派生类会重新定义的方法声明为虚函数,方法在基类中被声明为虚之后,它在派生类中将自动成为虚方法,然而在派生类声明中使用关键字virtual来指明哪些是虚函数不失为一个好方法。程序将根据对象类型而不是引用或者指针的类型来选择方法版本。为基类声明一个虚析构函数也是一种惯例。
