随着网络和信息技术的飞速发展,网络中的信息量也呈现爆炸式的增长,那么快速并且正确从这些海量的数据中获取正确的信息成为了现在搜索引擎技术的核心问题。用户的输入通常呈现很大的差异性,这是因为不同的人接受不同的教育、不同的文化,导致在表述同一个问题上面差异很大,那么对用户输入的搜索词进行词条权重的打分是非常有必要的,这对于从用户输入的搜索词中提取核心词,或是对搜索词返回的文档排序等都是一个非常重要的课题。词权重特征是衡量查询中词的重要度程度,主要应用于相关性排序。
一、TF-IDF
词频-逆文档频率(term frequency-inverse document frequency,TF-IDF) 的概念被公认为信息检索中最重要的发明。在搜索、文献分类和其他相关领域有广泛的应用。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。公式:

以上式子中 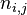 是该词
是该词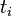 在文件
在文件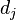 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。

其中
- |D|:语料库中的文件总数
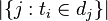 :包含词语的文件数目(即
:包含词语的文件数目(即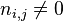 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用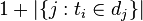
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。 因此
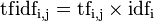
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。TF-IDF是一种简单有效词权重统计方法。
二、基于多模型融合的词权重计算
TF-IDF计算词权重方法简单可靠,但真正应用到系统中其准确度还是远远达不到要求,基于搜索用户的点击数据,提出一种离线数据挖掘结合机器学习计算词权重的方法,并在实际的应用中获得不错的效果,其实现框图如下:
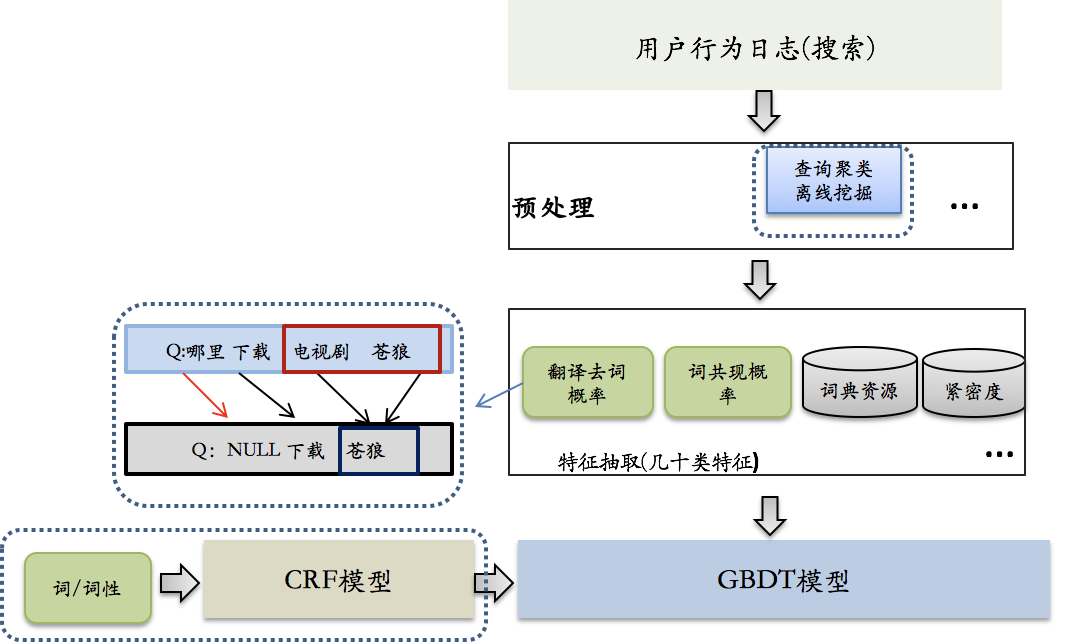
词权重的计算主要包括两方面的特征:1、统计特征,2、语言特征。其中统计特征是利用用户搜索日志和点击日志,统计词的基本特征,包括tf-idf,term在上下文中删除概率等,利用点击日志,根据共同点击doc,构成相似的query集合,在相似的query集合中,基于词共现某term出现的次数越多,相关的query相似度越高,则该term越重要。语言特征是词本身的属性,主要包括词性和词类信息,这些特征类别多而且针对词来说是唯一的,并且跟上下文有很强的关联性,对特征进行穷举会非常稀疏,因此在使用语言特征之前,利用CRF模型粗估词权重特征,对语言特征进行融合,并把CRF模型结果作为最终词权重模型的输入特征,预测词权重。
三、利用深度学习模型生成词权重
近年来,深度学习在自然语言处理中应用越来越广泛,并且在大多数任务中效果上远远要优于传统方法,特别是以LSTM模型为代表的具有序列记忆功能的深度学习,推动了自然语言处理领域的发展。我们也一直在尝试利用LSTM解决词权重计算问题,深度学习不同传统的模型,需要大规模训练数据。首先遇到的难题是需要自动构建大规模训练数据,利用点击日志,构建相似query集,通过计算词共现概率来表示查询中每个term的重要程度,构建词权重训练数据,训练LSTM模型。根据模型输出和标准答案之间的差异调节LSTM模型参数,训练结束后lstm模型可以对任意query逐词生成词权重,具体如下图所示:

传统模型面对统计特征不充分的查询,存在信息损失,而LSTM模型能在大规模训练数据集中,融合更多、更长的上下文信息,提升泛化和理解能力,并在生成query词权重中充分考虑上下文信息。目前利用深度学习模型在词权重生成项目上仅尝试过单层LSTM模型,之后可以考虑在embedding层加入更多的特征,如词性、句法分析、实体等词级别特征,另外可以考虑优化LSTM,如加入self-attention,双向LSTM、甚至多层模型。对深度学习来说,最重要的优化还是训练数据的质量提高,如何自动构建高质量的训练数据一直是深度学习模型应用的重要课题。