==================================================================
本篇参考:
https://www.cnblogs.com/chenmc/p/9516100.html
==================================================================
1.基础概念
Index 索引---DB数据库
Type 类型---数据表
Document 文档---表中一条记录
Field 字段---记录中的每个列属性
Shard 分片---对索引进行分片,分布于集群各个节点上,降低单个节点的压力
Replica 备份---拷贝分片就完成了备份
2.基本语法
接口均符合Rest风格
API基本格式:
http://<IP>:<PORT>/<Index>/<Type>/<Document的ID>
常用HTTP请求方法:
GET/PUT/POST/DELETE
3.对于Index索引的介绍和使用
3.1索引类型
结构化索引:mappings指定了的。可通过PostMan直接调用接口创建,也可以通过kibana的Dev Tools调用接口创建。【文章下面讲】
非结构化索引:mappings未指定的,是空的{},可以通过elasticSearch-head创建【参考:https://www.cnblogs.com/chenmc/p/9510514.html】
3.2操作索引
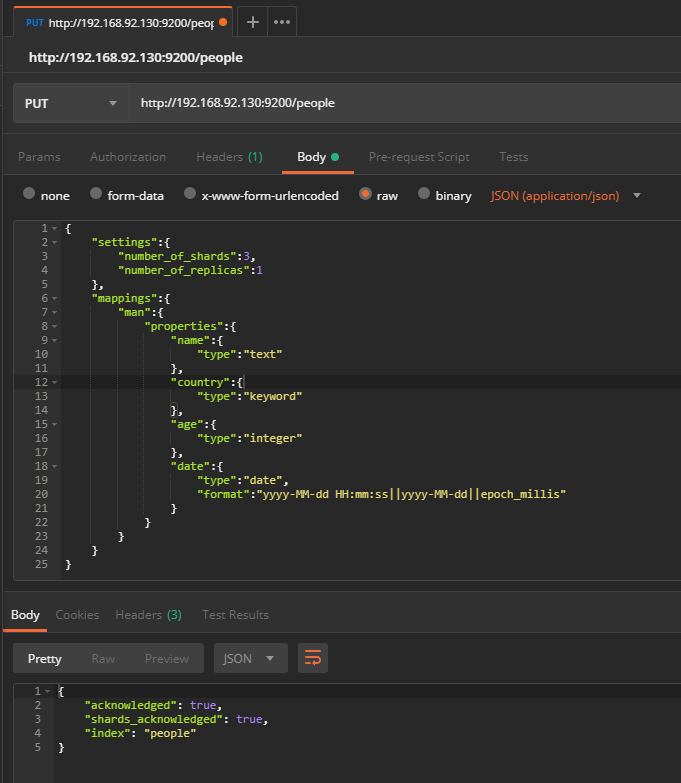
3.2.1 创建名为people的索引[Index],其中指定mappings,包含一个名为man的类型[Type]
url地址:
http://192.168.92.130:9200/people
请求方式:
PUT
请求体格式:
raw
JSON(application/json)
请求体:
{ "settings":{ "number_of_shards":3, "number_of_replicas":1 }, "mappings":{ "man":{ "properties":{ "name":{ "type":"text" }, "country":{ "type":"keyword" }, "age":{ "type":"integer" }, "date":{ "type":"date", "format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } } } }
注意:
1》请求方式必须是PUT,否则会报错:
"error": "Incorrect HTTP method for uri [/people] and method [POST], allowed: [PUT, GET, HEAD, DELETE]"

2》关于请求体的解读:

3》关于text和keyword数据类型的区别
keyword数据类型和text数据类型都是字符串类型
keyword数据类型不会被分词,可用以存储 姓名、邮箱地址、邮政编码等这类型的文本内容,可以用来检索过滤、排序、聚合。keyword字段只能用自身来进行检索!
text数据类型会被分词。text数据类型用来索引长文本,在建立索引之前即根据配置的分词器进行分词,搜索是也会根据配置的分词器进行搜索,没配置则使用默认分词器。text类型不会进行排序和聚合。
4》其他数据类型查看
https://www.cnblogs.com/sxdcgaq8080/p/10207262.html
4.通过Rest接口操作数据
4.1插入数据
4.1.1指定文档id插入数据
PUT http://ip:port/index/type/id

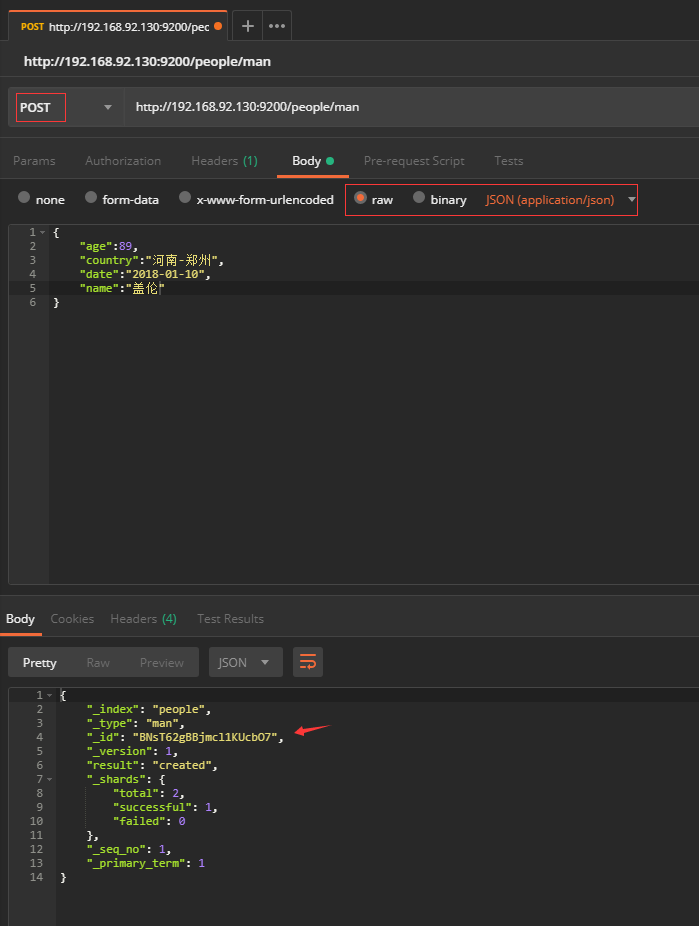
4.1.2不指定文档id,则自动产生文档id插入数据
POST http://ip:port/index/type
4.2修改数据
POST http://ip:port/index/type/id/_update

4.3删除数据
4.4删除索引
5.通过Rest接口查询数据
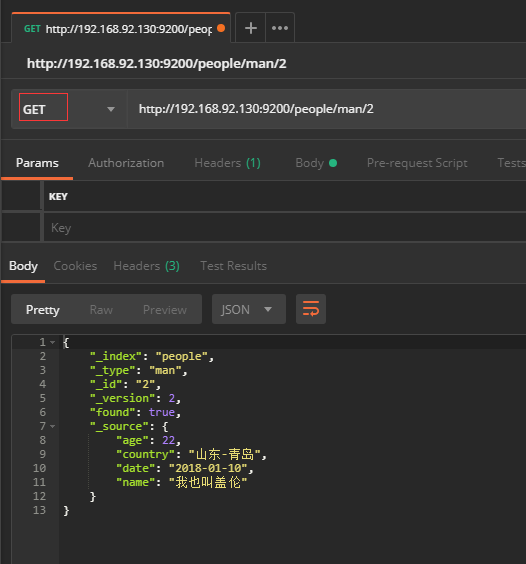
5.1根据ID查询
GET http://ip:port/index/type/id
5.2指定条件查询,分页,排序
POST http://ip:port/index/_search
注意请求体


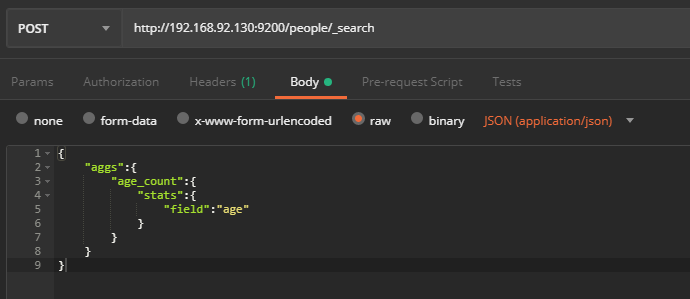
5.3分组查询
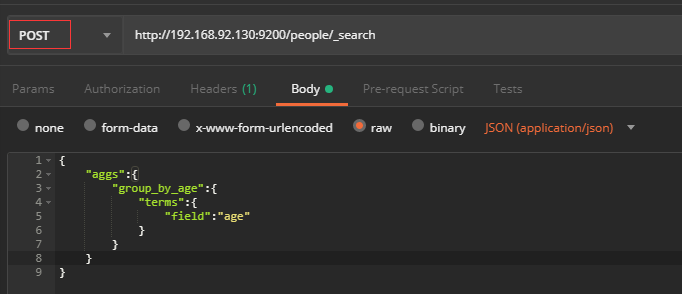

5.4 聚合计算