1、什么是继承
继承是一种新建类的方式,新建的类称之为子类,被继承的类称之为基类、父类、超类
继承描述的是一种“遗传”的关系:子类可以重用父类的属性
2、为何要用继承
2.1. 减少代码冗余
3、如何用继承
创建类时,象函数一样添加(),并将被继承的类的名字填入括号
4、注意事项
1、支持一个子类继承多个父类
2、python内分为两种类:
新式类:凡事新建类自动继承object的类以及该类的子类,子子类...等等,均为新式类,Python3的均为新式类
经典类:凡事新建类没有继承object的类以及该类的子类,子子类...等等,均为经典类,Python2的默认为经典类,除非手动指定(object)
不同的类在多继承背景下的属性查找是不同的,单继承相同
3、继承的优缺点:
优点:将代码冗余的问题解决
缺点:使代码解耦性降低


##查看类是否继承object class Parent1: ##python3下,想要成为新式类,需要指定为了 pass class Parent1(object): ##python2下,想要成为新式类,需要指定为了 pass # print(Parent1.__bases__) ##查看得到结果 (<class 'object'>,) class Parent2: pass class Subclass1(Parent1,Parent2): ##虽然没有指定object,但是由于父类继承了object,所以自动继承,但是结果不显示 pass print(Subclass1.__bases__) ##查看得到结果 (<class '__main__.Parent1'>, <class '__main__.Parent2'>) ##类及父类的指定 class Peopel: ##定义一个类 x = 1 class Stu1(Peopel): ##定义一个类,并指定父类 pass class Stu2(Peopel): ##定义一个类,并指定父类 pass class Teacher(Peopel): ##定义一个类,并指定父类 pass print(Stu1.x) ##这样stu1就可以使用People的属性了,减少了代码冗余 print(Stu2.x) ##这样stu1就可以使用People的属性了,减少了代码冗余 print(Stu3.x) ##这样stu1就可以使用People的属性了,减少了代码冗余
##通过观察可知通过这种方式,将代码冗余问题降低了,但是解耦性就变差了,其次还会有一个问题就是stu1,stu2要增加一个分数,teacher增加一个打分功能,这又怎么做呢,很明显不能直接在父类people中添加,因为可能其他类不需要里面的功能
解决方法:
##原始方法:代码冗余严重 class OldboyStudent: def __init__(self, name, age, sex, hometown): self.name = name self.age = age self.sex = sex self.hometown = hometown class OldboyTeacher: def __init__(self, name, age, sex, level): self.name = name self.age = age self.sex = sex self.level = level stu1=OldboyStudent('张全蛋','18','famle','山东') teacher=OldboyTeacher('张全蛋','18','famle','8') print(stu1.__dict__) ##可以看到名称空间里的变量名和值对应关系 print(teacher.__dict__) # == == == == == == == == == == == == == == == == == == == == == == == == #方法一:指名道姓的传参 # 在子类派生出的新方法中重用父类功能的方式一: # 指名道姓地访问某一个类的函数 # 注意: # 1. 该方式与继承是没有关系的 # 2. 访问是某一个类的函数,没有自动传值的效果 class OldboyPeople: def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex class OldboyStudent(OldboyPeople): # class OldboyStudent: ##可以不使用继承,但是不用继承在调用方法name, age, sex不会有提示,所以建议上面的方式 def __init__(self, name, age, sex, hometown): OldboyPeople.__init__(self, name, age, sex) self.hometown = hometown class OldboyTeacher(OldboyPeople): #class OldboyTeacher: ##可以不使用继承,但是不用继承在调用方法name, age, sex不会有提示,所以建议上面的方式 def __init__(self, name, age, sex, level): OldboyPeople.__init__(self, name, age, sex) self.level = level stu1=OldboyStudent('张全蛋','18','famle','山东') teacher=OldboyTeacher('张全蛋','18','famle','8') print(stu1.__dict__) ##可以看到名称空间里的变量名和值对应关系 print(teacher.__dict__) # == == == == == == == == == == == == == == == == == == == == == == == == # 在子类派生出的新方法中重用父类功能的方式二:只能在子类中用 # 在python2:super(自己的类名,对象自己) # 在python3:super() # 注意: # 1. 该方式与继承严格依赖于继承的mro列表 # 2. 访问是绑定方法,有自动传值的效果 class OldboyPeople: def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex class OldboyStudent(OldboyPeople): def __init__(self, name, age, sex, hometown): super().__init__(name, age, sex) # 调用super()会得到一个特殊的对象,该特殊的对象是专门用来引用父类中的属性的,!!!完全参照mro列表!!! self.hometown = hometown class OldboyTeacher(OldboyPeople): def __init__(self, name, age, sex, level): super().__init__(name, age, sex) # 调用super()会得到一个特殊的对象,该特殊的对象是专门用来引用父类中的属性的,!!!完全参照mro列表!!! self.level = level stu1=OldboyStudent('张全蛋','18','famle','山东') teacher=OldboyTeacher('张全蛋','18','famle','8') print(stu1.__dict__) ##可以看到名称空间里的变量名和值对应关系 print(teacher.__dict__)
前面说了关于继承的一些注意事项:其中提到了两种类的区别,具体哪种区别呢?
其实关于经典类域新式类的区别主要体现在:一个子类继承多个父类后的属性查找顺序问题
在这先说一下如何是父类多继承
class Foo1: x=1 class Foo2: y=2 class school(Foo1,Foo2): ##逗号隔开就继承了多个类,若子类本身没有某个属性,便默认从左往右去父类找属性,若找不到则报错 pass print(school.x) print(school.y)
1 继承顺序
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如A(B,C,D)
如果继承关系为非菱形结构,则会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
如果继承关系为菱形结构,那么属性的查找方式有两种,分别是:深度优先和广度优先
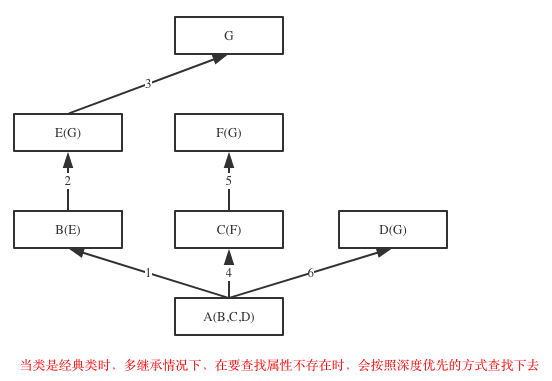
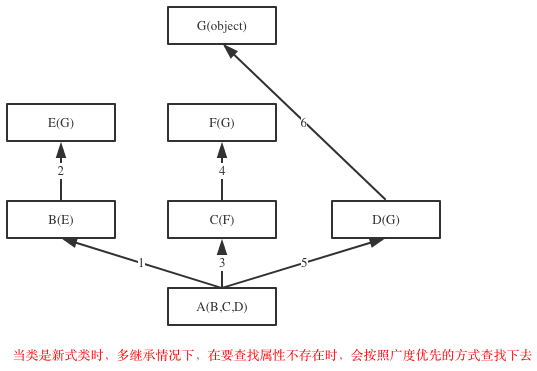
class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C #python3中统一都是新式类 #pyhon2中才分新式类与经典类 继承顺序
2 继承原理(python如何实现的继承)
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
>>> F.mro() #等同于F.__mro__ [<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
利用组合减少代码的冗余
1、什么是组合
组合指的是一个对象拥有某一个属性,该属性的值是另外一个类的对象
2、为何用组合
为了减少类与类之间代码冗余
3、如何用
#通过组盒方式实现学生报名课程,同时老师实现绑定负责的课程 class People: def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex class Student(People): pass ##pass不带表没有属性,因为我已经继承了父类,那么父类的属性他也可以使用 class Teacher(People): pass class Course(): def __init__(self,c_name,c_time,c_price): self.c_name = c_name self.c_price = c_price self.c_time = c_time stu1 = Student('张全蛋','18','female') ##实例化一个学生对象 stu2 = Student('张二蛋','18','male') tea1 = Teacher('egon','18','male') tea2 = Teacher('oldboy','18','male') python_obj = Course('Python全栈开发','120','19800') ##实例化一个Python课程对象 linux_obj = Course('Linux架构师','90','12800') stu1.course = python_obj ##通过组合的方式,给stu1报名一个python课程 print('%s 同学,报名了 %s 课程,学习周期为 %s 天,学费 %s 元' %(stu1.name,stu1.course.c_name,stu1.course.c_time,stu1.course.c_price)) tea2.course = linux_obj ##通过组合的方式,给tea1添加一个课程的属性 print('%s 老师,负责 %s 课程,该课程学习周期为 %s 天' %(tea2.name,tea2.course.c_name,tea2.course.c_time)) # ===================================================== ##报名多个课程 class People: def __init__(self,name,age,sex): self.name = name self.age = age self.sex = sex class Student(People): def __init__(self,name,age,sex): People.__init__(self,name,age,sex) self.course = [] #继承父类的同时派生新的属性 def tell_info(self): ##当用户和课程绑定后,那么用户也有了课程的方法,可以查看绑定过课程的信息 for item in self.course: print('%s 同学,报名了 %s 课程,学习周期为 %s 天,学费 %s 元' % (self.name, item.c_name, item.c_time, item.c_price)) class Teacher(People): pass ##pass不带表没有属性,因为我已经继承了父类,那么父类的属性他也可以使用 class Course(): def __init__(self,c_name,c_time,c_price): self.c_name = c_name self.c_price = c_price self.c_time = c_time stu1 = Student('张全蛋','18','female') ##实例化一个学生对象 stu2 = Student('张二蛋','18','male') tea1 = Teacher('egon','18','male') tea2 = Teacher('oldboy','18','male') python_obj = Course('Python全栈开发','120','19800') ##实例化一个Python课程对象 linux_obj = Course('Linux架构师','90','12800') stu1.course.append(python_obj) ##报名一个python课程 stu1.course.append(linux_obj) ##再报名一个Linux课程 stu1.tell_info()
多态和多态性
1、什么是多态
多态指的是同一种事物的多种形态
2、为何用多态
可以在不用考虑对象具体类型的情况下而直接使用对象
3、如何用多态
更多的表达的是一种归一化的理念
具体如何理解多态先看一组例子吧
import abc #借用的模块名 class Animal(metaclass=abc.ABCMeta): #父类调用metaclass=abc.ABCMeta @abc.abstractmethod #定义抽象基类,旨在要求子类必须满足具备此方法,无需完善其中功能 def speak(self): pass @abc.abstractmethod def run(self): pass #抽象基类:是用来指定规范,但凡继承该类的子都必须实现speak和run,而名字必须叫speak和run #注意:不能实例化抽象基类 class People(Animal): def speak(self): print('say hello') def run(self): pass obj = People() obj.speak() class Dog(Animal): def speak(self): print('汪汪汪') dog1 = Dog() ##由于没有定义run的方法,实例化便会报错 dog1.speak() ''' 其实多态性想要表达的并非上述的调用方法实现强制要求满足条件,而是说一种归一化的思想,就像Linux一切皆文件的思想一样 一切皆文件思想规范定义后,大家开源开发的程序就主要围绕读和写来开发,慢慢的约定俗成,不加思考的开发规范,就像上面的例子一样, 使用者不必知道dog和people是什么类型的东西,既然都是动物那么肯定都会speak和run,而abc模块只是一直让开发人员遵守规范 的手段,而Python也并不希望能够使用该模块,而是大家后续的开发规范更多的不通过语法而实现能归一化,像Linux的一切皆文件 ''' ''' python崇尚鸭子类 什么是鸭子类型,“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。” 综合上面的示例理解就是指我不管这个类是什么类型,但是他既然会叫会跑,那么我就认为他是动物 ''' #Python推荐方法,无需语法要求,进行实现 class People: def speak(self): print('say hello') def run(self): pass class Dog: def speak(self): print('汪汪汪') def run(self): pass obj = People() obj.speak()
封装
1 什么是封装
装就是将数据属性或者函数属性存放到一个名称空间里
封指的是隐藏,该隐藏是为了明确地区分内外,即该隐藏是对外不对内(在类外部无法直接访问隐藏的属性,而在类内部是可以访问)
2 为何要封装
封装可以实现让使用者无法直接调用原接口,而被迫使用由开发人员做过安全加固规范预留的接口
3 如何封装???
在类内定义的属性前加__开头
注意项:
封装的本质是将接口名在定义阶段进行扭曲变形,而扭曲变形是有规律的“_类名__接口名”的形式存在,并非真正的所有人都不能访问
#数据属性的封装 class Foo: one = 123 __two = 456 ##对two进行封装加两个下划线"_" Foo.__m1 = 789 ##定义阶段以外定义的,通过定义名可以直接访问,不会发生变形 print(Foo.__dict__) print(Foo.__m1) # {'__module__': '__main__', 'one': 123, '_Foo__two': 456, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__doc__': None} # 得到结果,发现two封装后,形态已经发生了变形,变成了"_Foo__two",而变形只发生在定义阶段 print(Foo.one) ##得到结果123 print(Foo.__two) ##报错 print(Foo._Foo__two) ##得到结果456 # 函数属性的封装 class ATM: def __card(self): ##此时的__card执行时变形为_ATM__card被执行 print('插卡') def withdraw(self): ##withdraw方法没有被伪装,所以用户可以通过withdraw调用被伪装的接口 self.__card() ##因为是定义阶段,所以此时的__card执行时变形为_ATM__card被执行 a=ATM() a.withdraw()
看明白了真正的封装机制,那么为什么要这么做呢,这样不很麻烦吗?
# 封装的真实意图:把数据属性或函数属性装起来就是为了以后使用的,封起来即藏起来是为不让外部直接使用 # 1.封数据属性:把数据属性藏起来,是为了不让外部直接操作隐藏的属性,而通过类内开辟的接口来间接地操作属性, # 我们可以在接口之上附加任意的控制逻辑来严格控制使用者对属性的操作 # ============================================================ # 伪装前: class People: def __init__(self, name, age): self.name = name self.age = age def tell_info(self): #查看姓名和年龄 print('[ 姓名:%s 年龄:%s ]' % (self.name, self.age)) stu1 = People('aaa','123') stu1.tell_info() #查看姓名和年龄 stu1.name = 'bbb' ##修改方式用户名 stu1.age = 'ddd' ##修改年龄 stu1.tell_info() ''' 这种修改方式有个弊端就是可以直接篡改数据,而这不是我们需要的我们需要规范接口,以后数据修改必须走我们规范的接口, 所以我们需要吧这个接口进行伪装 ''' # ============================================================ # 伪装后: class People: def __init__(self, name, age): self.__name = name self.__age = age def tell_info(self): #查看姓名和年龄 print('[ 姓名:%s 年龄:%s ]' % (self.__name, self.__age)) def set_info(self, name, age): if type(name) is not str: print('名字必须是str类型') return if type(age) is not int: print('年龄必须是int类型') return self.__name = name self.__age = age obj = People('egon', 18) #实例化一个对象 obj.set_info('EGOn','19') #修改失败,因为不满足我们的数据修改格式 obj.set_info('EGOn',19) #修改成功 obj.tell_info() #查看姓名和年龄 ''' 伪装后用户就必须使用我们做过规范限制的set_info方法修改用户数据,因为用户无法直接People.name修改了,因为伪装后 的名字是根据类名来访问的,对于外部人员一般是不知道我们的内部代码实现的 '''
property方法
property是什么?
property是属性的意思,在Python的类中可以将函数属性伪装成数据属性,达到直接调用的效果
为什么用property?
对于一些直接反馈结果的接口在使用时需要以函数方式使用,使用@property后无需以函数方式使用,方便快捷
property怎么用?
''' 成人的BMI数值: 过轻:低于18.5 正常:18.5-23.9 过重:24-27 肥胖:28-32 非常肥胖, 高于32 体质指数(BMI)=体重(kg)÷身高^2(m) EX:70kg÷(1.75×1.75)=22.86 ''' # property装饰器就是将一个函数属性伪装成一个数据属性 #使用前: class People: def __init__(self,name,weight,height): self.name=name self.weight=weight self.height=height def bmi(self): return self.weight / (self.height ** 2) obj=People('egon',80,1.83) print(obj.bmi()) ##当使用了@property后bmi就可以直接当做数据属性访问了,而尽管bmi是函数仍无需加() print(obj.bmi) ##没有@property情况下,只会得到内存地址,并不能直接返回结果使用,使用需要print(obj.bmi()) # =================================================== # 使用后: class People: def __init__(self,name,weight,height): self.name=name self.weight=weight self.height=height @property def bmi(self): return self.weight / (self.height ** 2) obj=People('egon',80,1.83) # print(obj.bmi()) #执行会报错,因为现在bmi是数据属性,不支持加() print(obj.bmi) ##直接反馈结果 ## 需要注意的是该操作仅仅在类class时使用,全局模式下没有任何作用
注意:该方式仅仅在class定义时使用
@classmethod与@staticmethod的应用
1、@classmethod与@staticmethod是什么?
定义类时,类的内部分为绑定方法和非绑定方法,绑定方法是什么呢?你还记得定义类内部的函数属性吗?总是会被自动写一个self,那个就是自动绑定的self属性,只不过自动传入的是对象本身
1、绑定方法
自动传入self 传入的是对象本身
自动传入cls 传入的是类本身
2、非绑定方法
非绑定方法是指我在类中定义函数属性时,并不需要传入cls和self,只想定义成一个普通函数
2、为什么用@classmethod与@staticmethod?
根据我们的需求来看我们并不是一直需要传入self,所以要根据我们需要看如果需要
1、定义成普通函数时我们用@staticmethod
2、定义成自动传入类本身时我们用@classmethod
3、如何用@classmethod与@staticmethod?
# 类中定义的函数有两大类(3小种)用途,一类是绑定方法,另外一类是非绑定方法 # 1. 绑定方法: # 特点:绑定给谁就应该由谁来调用,谁来调用就会将谁当作第一个参数自动传入 # 1.1 绑定给对象的:类中定义的函数默认就是绑定对象的 # 1.2 绑定给类的:在类中定义的函数上加一个装饰器classmethod # 2. 非绑定方法 # 特点: 既不与类绑定也不与对象绑定,意味着对象或者类都可以调用,但无论谁来调用都是一个普通函数,根本没有自动传值一说 ## 写一个程序读取IP和Port配置信息的方法 #第一种 在程序中指定 class MySQL: def __init__(self,ip,port): self.id = self.create_id() #自动获取一个uuid并赋值给self.id self.ip = ip self.port = port def select_info(self): #打印当前对象的uuid,ip和port 组合信息 print('%s:%s:%s' %(self.id,self.ip,self.port)) @staticmethod ##设置为非绑定方法,因为不依赖外部传参 def create_id(): import uuid #导入模块 return uuid.uuid4() #产生一个随机的UUID obj1=MySQL('172.18.0.191',3306) obj1.select_info() # # ================================================== #第二种 既能程序中指定又能在配置文件中读取 ''' # 配置文件setting.py的内容 HOST = '127.0.0.1' PORT = 3306 ''' class MySQL: def __init__(self,ip,port): self.id = self.create_id() #自动获取一个uuid并赋值给self.id self.ip = ip self.port = port def select_info(self): #打印当前对象的uuid,ip和port 组合信息 print('%s:%s:%s' %(self.id,self.ip,self.port)) @classmethod ##设置为自动传入类名(cls) def from_conf(cls): ##添加第二种传IP和Port的方式途径 import setting ##导入配置文件 return cls(setting.HOST,setting.PORT) # 实例化操作时MySQL('xxxx',3306),但是为了增加程序的茁长性我将MySQL当成参数自动传入,这样就不会因为类名万一哪天被修改而意外报错了 @staticmethod ##设置为非绑定方法,因为不依赖外部传参 def create_id(): import uuid return uuid.uuid4() #产生一个随机的UUID obj1=MySQL('172.18.0.191',3306) obj1.select_info() obj2=MySQL.from_conf() obj2.select_info()
反射
什么是反射?
指的是通过字符串来操作属性
为什么用反射?
一种更加优雅的操作属性的方式
class Ftp: def get(self): print('get') def put(self): print('put') def run(self): while True: choice=input('>>>: ').strip() if choice in Ftp.__dict__: ##判断用户输入的方法是不是存在于类的字典中 Ftp.__dict__[choice](self) ##存在则拿到方法的地址 "方法(self)" 调用 else: print('命令不存在') obj=Ftp() obj.run() # ================================================== # class Ftp: def get(self): print('get') def put(self): print('put') def run(self): while True: choice=input('>>>: ').strip() if hasattr(self,choice): ##判断用户输入的方法是否存在于类的对象中 getattr(self,choice)() ##getattr直接拿到内存地址加"()"调用 else: print('命令不存在') obj=Ftp() obj.run()
如何用反射?
# hasattr() 判断方法是否存在于对象 print(hasattr(obj,'name')) #'name' in obj.__dict__ print(hasattr(obj,'max2')) #'max2' in obj.__dict__ # getattr() 获取对象中某个属性方法的内存地址 print(getattr(obj,'name')) #obj.__dict__['name'] print(getattr(obj,'age')) #obj.__dict__['age'] ##当age不存在时则报错 print(getattr(obj,'age',None)) #obj.__dict__['age'] ##当age不存在时返回默认值不报错 # setattr() 向对象添加一个属性方法 setattr(obj,'age',18) #obj.age=18 setattr(obj,'name','EGON') #obj.name='EGON' print(obj.__dict__) # delattr() 删除对象中的某个方法 delattr(obj,'name')# del obj.name print(obj.__dict__)