结合多线程实现服务端并发(不用socketserver模块)
socketserver自带多线程
服务端代码
import socket
from threading import Thread
'''
服务端
1.固定的ip和端口
2.24小时不间断提供服务
3.支持并发
'''
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(conn):
while True:
# 模拟不停交互
try:
data = conn.recv(1024)
if len(data) == 0:
break
print(data.decode('utf-8'))
conn.send(b'Hi')
except ConnectionResetError as e:
print(e)
break
conn.close()
# 链接循环
while True:
conn, addr = server.accept()
print(addr)
t = Thread(target=talk, args=(conn, ))
t.start()
# 通信循环 # 提取这块代码,封装起来
# while True:
# try:
# data = conn.recv(1024)
# if len(data) == 0:
# break
# except ConnectionResetError as e:
# print(e)
# break
# conn.close()
客户端代码
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
# 模拟不停交互
client.send(b'hello')
data = client.recv(1024)
print(data.decode('utf-8'))
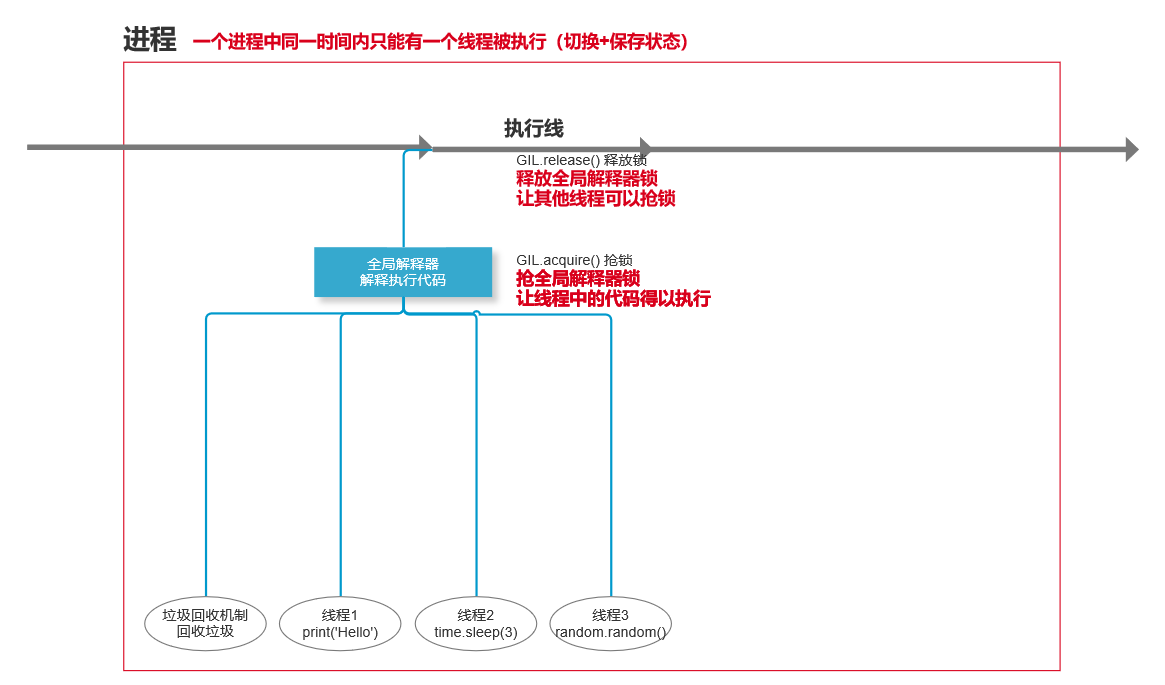
CIL全局解释器锁******
'''
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
'''
ps:python解释器有很多种 最常见的就是Cpython解释器
"""
GIL本质也是一把互斥锁:将并发变成串行,牺牲效率保证数据的安全
用来阻止同一个进程下的多个线程的同时执行(同一个进程内多个线程无法实现并行但是可以实现并发)
python的多线程无法并行就无法利用多核优势 是不是就是没有用了?
GIL的存在是因为CPython解释器的内存管理不是线程安全的
垃圾回收机制本质也是一个线程,进程间是不同的内存空间,线程间数据共享
"""
每一个进程都有一个python解释器,都有一个垃圾回收机制的线程
如果没有GIL,允许多线程同时运行
线程1 执行到 a = 1,刚申请一块内存空间,把1 放进去,正要与a 绑定关系之前突然垃圾回收机制扫描到这个1 没有引用,顺手就给清除掉了,那么这个线程就直接报错了
可能被问到的两个判断
1. GIL是python的特点吗?
不是,它只是CPython解释器的特点
2. 单进程下多个线程无法利用多核优势是所有解释型语言的通病
正确,如果解释型语言能够利用多核优势,并行地执行代码,就会出现垃圾回收机制干扰线程数据的情况,CPython中就采用了CIL全局解释器锁来解决这一问题,牺牲多核优势保证线程安全
解释型语言都需要先解释再执行,在CPython中是用GIL全局解释器锁
与普通互斥锁的区别
代码遇到I/O操作就将GIL全局解释器锁给释放了,保证线程安全但不能保证数据安全
GIL是专门保护线程安全的,要想保护数据安全需要单独为数据处理加锁(普通互斥锁通常都是这样的)
针对不同的数据操作应该加不同的锁去处理
验证GIL与普通互斥锁的区别
import time
from threading import Thread
n = 100
def task():
global n
tmp = n
time.sleep(1) # IO ,遇到IO 就把GIL锁释放,给别的线程抢
n = tmp - 1
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t)
for i in t_list:
i.join()
print(n)
# 99 # 写上 time.sleep(1) 时
# 0
验证python的多线程是否有用需要分情况讨论
进程可以充分利用CPU(多核时体现),但消耗资源较(线程)大
线程较(进程)节省内存资源,但无法充分发挥多核CPU优势
计算密集型任务
计算操作很依靠CPU
单核情况下
开线程更省资源
多核情况下
开进程更省时间
from multiprocessing import Process
from threading import Thread
import os
import time
def work():
res = 0
for i in range(100000000):
res *= i
if __name__ == '__main__':
l = []
print(os.cpu_count())
# 4 # 4核CPU,我的CPU比较菜
start = time.time()
for i in range(6):
p = Process(target=work) # 多个进程同时运算
# p = Thread(target=work) # 线程排队切换(并发)执行运算
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print('run time is %s' % (stop - start))
# run time is 21.93324899673462 # p = Process(target=work) 多进程时
# run time is 35.11313056945801 # p = Thread(target=work) 多线程时
IO密集型任务
IO操作不太依靠CPU(IO操作会让CPU空闲,程序进入阻塞态)
单核情况下
开线程更省资源
多核情况下
开线程更省资源(基本用不到多少CPU)
from multiprocessing import Process
from threading import Thread
import os
import time
def work():
time.sleep(2)
if __name__ == '__main__':
l = []
print(os.cpu_count())
# 4
start = time.time()
for i in range(400):
# p = Process(target=work) # 多进程,大部分时间耗费在创建进程上
p = Thread(target=work) # 多线程
l.append(p)
p.start()
for p in l:
p.join()
stop = time.time()
print('run time is %s' % (stop - start))
# run time is 22.937195301055908 # p = Process(target=work) 多进程时
# run time is 2.0452797412872314 # p = Thread(target=work) 多线程时
小结论
python的多线程到底有没有用,需要看情况而定,并且肯定是有用的(GIL全局解释器锁限制了python的多线程不能并行)
绝大数情况下还是多进程+多线程配合使用的
伪代码:编造代码实现效果演示一下
死锁与递归锁
死锁
双方接下来要的锁都在对方手上,并且都不肯释放锁,就都在等待锁被释放再抢
import time
from threading import Thread, Lock
mutexA = Lock()
mutexB = Lock()
"""
只要类加括号实例化对象
无论传入的参数是否一样,生成的对象肯定不一样
(单例模式除外)
"""
class MyThread(Thread):
def run(self): # 创建线程自动触发run 方法, run方法内调用 func1 func2 相当于也是自动触发
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f"{self.name}抢到了A锁") # 执行也是要点时间的(虽然超级超级短)
mutexB.acquire()
print(f"{self.name}抢到了B锁")
mutexB.release()
print(f"{self.name}释放了B锁")
mutexA.release()
print(f"{self.name}释放了A锁")
def func2(self):
mutexB.acquire()
print(f"{self.name}抢到了B锁")
time.sleep(1)
mutexA.acquire()
print(f"{self.name}抢到了A锁")
mutexA.release()
print(f"{self.name}释放了A锁")
mutexB.release()
print(f"{self.name}释放了B锁")
for i in range(10):
t = MyThread()
t.start()
# Thread-1抢到了A锁
# Thread-1抢到了B锁
# Thread-1释放了B锁
# Thread-1释放了A锁
# Thread-1抢到了B锁
# Thread-2抢到了A锁
# 程序卡住.....
'''
结果原因分析:
抢到A锁,再抢B锁没人抢,再释放B锁也没人抢,释放A锁执行func2
大家都去抢A锁,我抢B锁,抢到了休息一秒,别人还在接着往下抢锁,抢到B锁,去抢A锁,我还在休息(执行代码超级快)
等我休息好了要抢B锁,而B锁别人拿着,别人又要抢完了A锁才会释放B锁,而我要抢到了B锁才会释放A锁,所以大家就都这样僵着了...(程序就卡这儿了)
'''
自己千万不要轻易的处理锁的问题(一般也不会涉及到)
递归锁 RLock
递归锁机制:
RLock 可以被第一个抢到锁的人连续acquire和release多次
每acquire一次,锁身上的计数加
每release一次,锁身上的计数减1
只要锁的计数不为0,其他人都不能抢
from threading import Thread, RLock
import time
mutexA = mutexB = RLock() # mutexA 和 mutexB 是同一把锁(不想改下面的代码)
"""
只要类加括号实例化对象
无论传入的参数是否一样,生成的对象肯定不一样
(单例模式除外)
"""
class MyThread(Thread):
def run(self): # 创建线程自动触发run 方法, run方法内调用 func1 func2 相当于也是自动触发
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f"{self.name}抢到了A锁") # 执行也是要点时间的(虽然超级超级短)
mutexB.acquire()
print(f"{self.name}抢到了B锁")
mutexB.release()
print(f"{self.name}释放了B锁")
mutexA.release()
print(f"{self.name}释放了A锁")
def func2(self):
mutexB.acquire()
print(f"{self.name}抢到了B锁")
time.sleep(1)
mutexA.acquire()
print(f"{self.name}抢到了A锁")
mutexA.release()
print(f"{self.name}释放了A锁")
mutexB.release()
print(f"{self.name}释放了B锁")
for i in range(10):
t = MyThread()
t.start()
# Thread-1抢到了A锁
# Thread-1抢到了B锁
# Thread-1释放了B锁
# Thread-1释放了A锁
# Thread-1抢到了B锁
# ....省略大量打印结果.....
# Thread-1释放了B锁
# Thread-9抢到了B锁
# Thread-9抢到了A锁
# Thread-9释放了A锁
# Thread-9释放了B锁
# ---> 谁抢到了下面一大段都是谁在操作
信号量 Semaphore
这里的信号量不是通用概念,在不同的地方有不同的意义,对应不同的知识点
比喻
互斥锁--> 厕所(一把锁)
信号量--> 公共厕所(多把锁)
import random
import time
from threading import Thread, Semaphore
semaphore = Semaphore(2) # 造了一个含有五个坑位的公共厕所
def task(name):
semaphore.acquire()
print(f"{name}占了一个坑位")
time.sleep(random.randint(1, 3))
semaphore.release()
print(f"{name}拉完了")
for i in range(5):
t = Thread(target=task, args=(i,))
t.start()
# 0占了一个坑位
# 1占了一个坑位
# 1拉完了
# 2占了一个坑位
# 0拉完了
# 3占了一个坑位
# 3拉完了
# 4占了一个坑位
# 2拉完了
# 4拉完了
Event事件
可利用event实现子线程等待某个子线程的结束再接着执行
import time
from threading import Thread, Event
event = Event()
def light():
print("红灯正亮着...")
time.sleep(2)
# --------------------------------------
# event.set() 发出信号
# 同一 Event对象.wait()处将收到信号
# 不再等待,接着往下执行
# --------------------------------------
event.set()
# 测试GIL全局解释器锁 start
# a = 1 + 6 * 4 * 4 / 12 * 1*151*158*235*122*21*45/121 # CPU运算不会释放GIL锁
# msg = input('>>>:').strip() # I/O 操作会释放GIL锁
# 测试GIL全局解释器锁 end
print("绿灯亮了")
def car(name):
print(f"{name} 正在等红灯...")
# --------------------------------------
# event.wait() 等待信号
# 未收到信号就在这里等待信号
# 类似队列的 .get() .put()等待
# --------------------------------------
event.wait()
print(f"{name}加油门飙车了...")
_light = Thread(target=light)
_light.start()
for i in range(5):
t = Thread(target=car, args=(f'car{i}',))
t.start()
# 红灯正亮着...
# car0 正在等红灯...
# car1 正在等红灯...
# car2 正在等红灯...
# car3 正在等红灯...
# car4 正在等红灯...
# 绿灯亮了
# car0加油门飙车了...
# car2加油门飙车了...
# car4加油门飙车了...
# car1加油门飙车了...
# car3加油门飙车了...
# # 测试GIL全局解释器锁返回结果
# 红灯正亮着...
# car0 正在等红灯...
# car1 正在等红灯...
# car2 正在等红灯...
# car3 正在等红灯...
# car4 正在等红灯...
# >>>:car1加油门飙车了... # I/O 操作释放了全局解释器锁,其他地方抢到了,就执行,等你输入了进入就绪态,抢锁
# car2加油门飙车了...
# car3加油门飙车了...
# car0加油门飙车了...
# car4加油门飙车了...
# 151 # 手动输入的值,然后才打印下一行
# 绿灯亮了
线程结合队列
疑问:同一个进程下的多个线程本来就是数据共享的,为什么还要用队列?
因为队列是管道+锁,使用队列就不需要自己手动操作锁的问题,如果锁操作不当极容易产生死锁现象
三种队列 Queue LifoQueue PriorityQueue 基本操作
from threading import Thread
import queue
q = queue.Queue()
q.put(1)
print(q.get())
# 1
q = queue.LifoQueue() # Last in First Out
q.put(1)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
print(q.get())
# 3
# 2
# 1
q = queue.PriorityQueue() # 优先级 Q
# 因为重名了,点put进去,看到的是Queue的方法
q.put((10, 'haha')) # (priority number, data) 是一个元组,第一个是优先级数字(数据越小,优先级越高),第二是数据
q.put((100, 'hhe'))
q.put((0, 'hihi'))
q.put((-10, 'yyy'))
print(q.get())
print(q.get())
print(q.get())
print(q.get())
# (-10, 'yyy')
# (0, 'hihi')
# (10, 'haha')
# (100, 'hhe')