
最近发现很多人还是不能真正分清机器学习的学习方法,我以个人的愚见结合书本简单说一下这个
机器学习中,可以根据学习任务的不同,分为监督学习(Supervised Learning),无监督学习(Unsupervised Learning)、半监督学习(Semi-Supervised Learning)和强化学习(Reinforcement Learning).
监督学习和无监督学习是使用较多的两种学习方法,我们下面主要解释这两种学习方法
监督学习
监督学习中的数据中是提前做好了分类的信息的,如垃圾邮件检测中,他的训练样本是提前存在分类的信息,也就是对垃圾邮件和非垃圾邮件的标记信息

监督学习中,他的训练样本中是同时包含有特征和标签信息的,
监督学习中,比较典型的问题就是像上面说的分类问题(Classfication)和回归问题(Regression)
它们两者最主要的特点就是分类算法中的标签是离散的值,就像上面说的邮件分类问题中的标签为{1, -1},分别表示了垃圾邮件和非垃圾邮件
而回归算法中的标签值一般是连续的值,如预测一个人的年龄,一般要根据身高、性别、体重等标签,这是因为年龄是连续的正整数
在这个上面比较典型的算法有哦LR(Logistic Regression)、BP神经网络算法以及常见的线性回归算法
无监督学习
无监督学习是另一种常用的机器学习算法,与监督学习不同的是,无监督学习的样本是不包含标签信息的,只有一定的特征,所以由于没有标签信息,学习过程中并不知道分类结果是否正确
比较典型的是一些聚合新闻网站,利用爬虫爬取新闻后对新闻进行分类的问题
例如 百度新闻
它们都是没有新闻工作者的,只是聚合全网的新闻
例如我们搜索5G试点城市
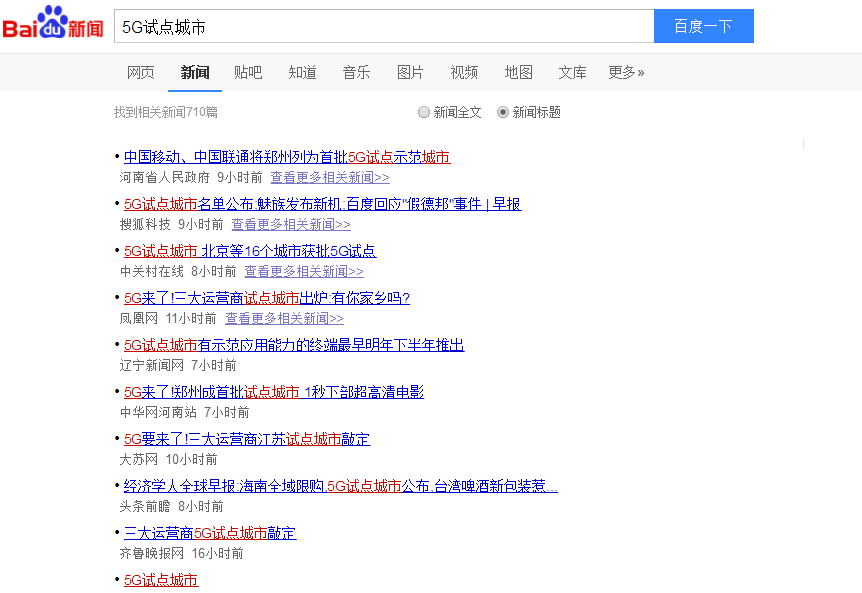
所有有关这个关键字的新闻都会出现,它们被作为一个集合,在这里我们称它为聚合(Clustering)问题
无监督学习的典型问题就是上面说的聚类问题,比较有代表性的算法有K-Means算法(K均值算法)、DBSCAN算法等
聚类算法是无监督学习算法中最典型的一种学习算法,它是利用样本的特征,将具有相似特征的样本划分到同一个类别中,而不会去关心这个类别是什么
除了聚类算法外,无监督学习中还有一类重要的算法就是降维的算法,原理是将样本点从输入空间通过线性或非线性变换映射到一个低维空间,从而获得一个关于原数据集的低维表示
比较常用的就是聚类算法
如果没有弄明白,你可以去听Andrew Ng在Coursera上面的有关这一部分的视频
源链接 https://www.coursera.org/learn/machine-learning
b站上的链接
https://www.bilibili.com/video/av9912938/?p=4
我的个人博客:www.susmote.com