原文档地址:http://hbase.apache.org/1.2/book.html#cp
ApacheHbase协处理器 Apache HBase Coprocessors
HBase Coprocessors协处理器是在Google BigTable的协处理器实现之后才建模的 (http://research.google.com/people/jeff/SOCC2010-keynote-slides.pdf pages 41-42.)。
协处理器框架提供了在管理你数据的RegionServer上直接运行定制代码的机制 目前正在努力消除HBase的实现和BigTable的架构之间的差距。获取更多信息,参考 HBASE-4047。
本章中的信息主要来源是以下资源,并从以下资源中使用了大量重用:
-
Mingjie Lai’s blog post Coprocessor Introduction.
-
Gaurav Bhardwaj’s blog post The How To Of HBase Coprocessors.
|
Use Coprocessors At Your Own Risk
协处理器是HBase的一个高级特性,并且它只是由系统开发者使用的。因为协处理器代码直接运行在RegionServer上,并且可以直接访问你的数据,所以它们引入了数据损坏的风险、中间人攻击或其他的数据恶意访问。当前,没有机制来防止协处理器造成的数据损坏,虽然这个工作在进行中 HBASE-4047。 此外,没有资源隔离,因此一个善意但行为不当的协处理器会严重降低集群的性能和稳定性。 |
86. Coprocessor Overview
在HBase中,你使用Get或者Scan fetch数据,而在RDBMS中你使用SQL查询。为了只fetch相关的数据,你使用HBase Filter过滤数据,而在RDMBS中你使用 WHERE 谓词。
在fetching数据之后,你在数据上执行运算。这种模式适用于几千行和几列的“小数据”。但是,当您扩展到数十亿行和数百万列时,在您的网络中移动大量的数据将会在网络层造成瓶颈,并且客户端需要足够强大,并且有足够的内存来处理大量的数据和计算。此外,客户端代码可以变得更大、更复杂。
在这样的场景中,协处理器可能是有意义的。您可以将业务计算代码放入一个在RegionServer上运行的coprocessor,在与数据相同的位置,并将结果返回给客户端。
这是使用协处理器能带来好处的唯一情景。下面是一些类比,可以帮助解释协处理器的一些好处。
86.1. 协处理器类比 Coprocessor Analogies
- 触发器和存储过程 Triggers and Stored Procedure
-
一个观察者协处理器类似于一个RDBMS中的触发器,它在一个特定的事件(例如Get或Put)发生之前或之后来执行你的代码。一个终端协处理器类似于RDBMS中的一个存储过程,因为它允许你在当前RegionServer存有的数据上执行自定义运算,而不是在客户端执行运算。
- MapReduce
-
MapReduce以把计算移动到数据所在的位置的原则进行运行。协处理器以相同的原则运行。
- 面向切片的编程设计 AOP
-
如果你熟悉 面向切片的编程设计 Aspect Oriented Programming (AOP), 你可以认为协处理器可以您可以在把请求传递到最终目的地之前(或者甚至改变目的地),通过截取请求,然后运行一些自定义代码,然后将请求传递到最终目的地。
86.2. Coprocessor Implementation Overview
-
你的类应该继承自Coprocessor classes的一种, 如 BaseRegionObserver, 或者你的类要实现 Coprocessor 或者CoprocessorService 接口。
-
加载这个coprocessor, 可以静态加载(通过配置文件)或动态加载(使用HBase Shell命令)。 更多内容参考 Loading Coprocessors.
-
从你的客户端代码中调用coprocessor。HBase对协处理器的处理是透明的。
87.1. 观察者协处理器 Observer Coprocessors
Observer coprocessors 在一个特定的事件发生之前或之后被触发。在一个事件之前发生的观察者使用的方法以一个 pre 前缀开头, 例如 prePut。在一个事件之后发生的观察者覆盖的方法以一个 post 前缀开头, 例如 postPut.
87.1.1. Use Cases for Observer Coprocessors
- 安全 Security
-
在执行一个
Get或Put操作之前,你可以使用preGet或prePut方法检查权限。 - 参照完整性 Referential Integrity
-
HBase不直接支持参照完整性(外键)这一RDBMS中的概念。你可以使用一个协处理器以强制这样的完整性。例如,如果你有一个业务规则是每一次向users表里插入的数据必须参照user_daily_attendance表中相应的条目,你可以实现一个协处理器,使用在user表上的prePut方法向user_daily_attendance表插入一条记录。
- 二级索引 Secondary Indexes
-
你可以使用一个协处理器维护多个二级索引。获取更多信息,参考 SecondaryIndexing。
87.1.2. Types of Observer Coprocessor
- RegionObserver
-
一个RegionObserver coprocessor 允许你观察一个Region上的事件,如
Get和Put操作。参考 RegionObserver。可以考虑覆盖类 BaseRegionObserver, 这个类实现了RegionObserver接口。 - RegionServerObserver
-
一个 RegionServerObserver 允许你观察与RegionServer的操作相关的事件, 如 启动、停止 或 执行合并、提交或者回滚。参考RegionServerObserver。考虑覆盖类 BaseMasterAndRegionObserver,这个类实现了
MasterObserver和RegionServerObserver接口。 - MasterOvserver
-
一个 MasterObserver 允许你观察和HBase Master相关的事件, 如表创建、表删除或者表结构修改。参考 MasterObserver。考虑覆盖类 BaseMasterAndRegionObserver, 这个类实现了
MasterObserver和RegionServerObserver接口。 - WalObserver
-
一个WalObserver 允许你观察和向 Write-Ahead Log (WAL)写入相关的事件。参考 WALObserver。考虑覆盖类 BaseWALObserver, 这个类实现了
WalObserver接口。
Examples provides working examples of observer coprocessors.
87.2. 终端协处理器 Endpoint Coprocessor
终端协处理器允许你在数据存放的位置执行运算。参考 Coprocessor Analogy。例如,需要计算一个横跨数百个Region的完整表的运行平均值或总和。
与自定义代码透明地执行的观察者协处理器相比,终端协处理器必须用Table, HTableInterface, 或 HTable 的CoprocessorService() 方法显示调用。
从HBase 0.96开始,终端协处理器用Google Protocol Buffers (protobuf)实现。获取更多关于 protobuf的细节,参考Google’s Protocol Buffer Guide. HBase 0.94中编写的Endpoints Coprocessor 和 0.96 及以后的版本并不兼容。参考 HBASE-5448。要把你的HBase集群从0.94或更早的版本升级到0.96及以后的版本,你需要重新实现你的协处理器。
要使你的协处理器在HBase可用,它必须被加载loaded,可以使静态加载 (通过配置HBase) 或者 动态加载 (使用 HBase Shell 或 Java API).
88.1. 静态加载 Static Loading
下列步骤用来静态加载你的协处理器。请记住,必须重新启动HBase以卸载一个已被静态加载的coprocessor。
-
在 hbase-site.xml 定义一个协处理器,使用 <property> 元素和 <name> <value> 子元素。<name> 应该是下列之一:
-
hbase.coprocessor.region.classesfor RegionObservers and Endpoints. -
hbase.coprocessor.wal.classesfor WALObservers. -
hbase.coprocessor.master.classesfor MasterObservers.<value> 必须包含你的协处理器实现类的完整类名。
例如,要加载一个 Coprocessor (实现类是 SumEndPoint.java) 你必须在 RegionServer’s 'hbase-site.xml' 文件中 (一般在 'conf' 目录下)创建以下条目:
<property> <name>hbase.coprocessor.region.classes</name> <value>org.myname.hbase.coprocessor.endpoint.SumEndPoint</value> </property>
如果多个类被指定要加载,类名间要用逗号分隔。框架会试图使用默认类加载器加载所有配置的类。因此,这个jar文件必须位于server端的HBase classpath中。
通过这种方式加载的Coprocessors将对所有表的所有Region都是激活状态的。这些也被称作 系统Coprocessor。首先列出的Coprocessors 将被赋予
Coprocessor.Priority.SYSTEM这样的优先级。列表中每一个后续的coprocessor 将会把它的优先级加一(这是在减小它的优先级,因为优先级是按照整数的自然顺序排列的)。当调用注册的观察者时,框架会按照它们的优先级顺序执行它们的回调方法。
关系被打破。
-
-
把你的代码放在HBase的 classpath。做这件事的一个简单的方法是把 jar (包含你的代码和所有依赖)放到HBase安装路径的
lib/目录下。 -
重启 HBase。
88.2. 静态卸载 Static Unloading
-
在hbase-site.xml中删除协处理器的 <property> 元素,包括子元素。
-
重启 HBase.
-
可选的操作是,从HBase的 lib/ 目录下或者从classpath中移除这个协处理器的 JAR 文件。
88.3. 动态加载 Dynamic Loading
你可以在不重启HBase的情况下,动态加载协处理器。这看起来比静态加载更好,但是动态加载协处理器的是被加载到一张表上,并且只在加载它们的表上可用。由此,动态加载的协处理器有时被称为表协处理器Table Coprocessor。
另外,动态加载一个协处理器相当于改变表的结构,表必须下线以加载协处理器。
有三种动态加载 Coprocessor 的方法。
|
假定
下面的说明有以下的假设:
|
88.3.1. Using HBase Shell
-
在HBase Shell中禁用表:
hbase> disable 'users'
-
使用如下命令加载这个 Coprocessor:
hbase> alter 'users', METHOD => 'table_att', 'Coprocessor'=>'hdfs://<namenode>:<port>/ user/<hadoop-user>/coprocessor.jar| org.myname.hbase.Coprocessor.RegionObserverExample|1073741823| arg1=1,arg2=2'
协处理器框架将试着从协处理器表的属性值中读取类的信息。这个值包含由管道符号(|)分割成的4片信息。
-
文件路径: 包含 Coprocessor 定义的这个jar文件必须在所有的RegionServer可以读取到的位置上。
你可以拷贝这个文件到每一个RegionServer的本地磁盘上,但是推荐把它存放在HDFS上。 -
类名: Coprocessor的完整类名.
-
优先级: 一个整数。该框架将确定在同一个钩子上使用优先级注册的所有配置的观察器的执行顺序,并使用优先级。这片信息可以留空不填,这样的话,框架将会赋予一个默认的优先级值。
-
参数 (可选): 这片信息会传入协处理器的实现类中。这片信息是可选的。
-
-
启用这个表.
hbase(main):003:0> enable 'users'
-
验证协处理器是否被加载:
hbase(main):04:0> describe 'users'
协处理器应该在
TABLE_ATTRIBUTES列出。
88.3.2. Using the Java API (all HBase versions)
以下Java代码展示了如何使用 HTableDescriptor的setValue() 方法在users表上加载一个协处理器。
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.setValue("COPROCESSOR$1", path + "|" + RegionObserverExample.class.getCanonicalName() + "|" + Coprocessor.PRIORITY_USER);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
88.3.3. Using the Java API (HBase 0.96+ only)
在 HBase 0.96及其后的版本, HTableDescriptor的addCoprocessor() 方法提供了一个简单的方式去动态加载一个coprocessor 。
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf);
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
hTableDescriptor.addCoprocessor(RegionObserverExample.class.getCanonicalName(), path,
Coprocessor.PRIORITY_USER, null);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
| 框架不保证将给定的Coprocessor成功加载。例如,shell命令不保证一个jar文件存在于某个位置,也不验证给定的类是否实际存在于这个Jar文件中。 |
88.4. Dynamic Unloading
88.4.1. Using HBase Shell
-
禁用表
hbase> disable 'users'
-
修改表以移除coprocessor.
hbase> alter 'users', METHOD => 'table_att_unset', NAME => 'coprocessor$1'
-
启用表
hbase> enable 'users'
88.4.2. Using the Java API
通过使用 setValue() 或 addCoprocessor() 方法在不设置coprocessor的情况下重新加载表定义。这将移除任意的附在这个表上的coprocessor。
TableName tableName = TableName.valueOf("users");
String path = "hdfs://<namenode>:<port>/user/<hadoop-user>/coprocessor.jar";
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
admin.disableTable(tableName);
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
HColumnDescriptor columnFamily1 = new HColumnDescriptor("personalDet");
columnFamily1.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily1);
HColumnDescriptor columnFamily2 = new HColumnDescriptor("salaryDet");
columnFamily2.setMaxVersions(3);
hTableDescriptor.addFamily(columnFamily2);
admin.modifyTable(tableName, hTableDescriptor);
admin.enableTable(tableName);
在 HBase 0.96 及以后的版本中,你可以使用 HTableDescriptor类的removeCoprocessor() 方法。
89. Examples
HBase 带有Observer Coprocessor的例子,在 ZooKeeperScanPolicyObserver 中,也带有Endpoint Coprocessor的例子,在RowCountEndpoint
一个更详细的例子如下。
这些例子假定一个表名为 users, 有两个列族 personalDet 和 salaryDet, 包含个人和收入的详细信息。下面是 users 表的图形化展示。
| personalDet | salaryDet | |||||
|---|---|---|---|---|---|---|
|
jverne |
Jules |
Verne |
02/08/1828 |
12000 |
9000 |
3000 |
|
rowkey |
name |
lastname |
dob |
gross |
net |
allowances |
|
admin |
Admin |
Admin |
||||
|
cdickens |
Charles |
Dickens |
02/07/1812 |
10000 |
8000 |
2000 |
89.1. Observer Example
下面的 Observer coprocessor 防止 user admin 的详细信息在对 users 表的Get和Scan操作中返回。
-
写一个继承 BaseRegionObserver 的类。
-
覆盖
preGetOp()方法 (preGet()方法已被弃用了) 用以检查客户端是否已查询了rowkey为admin的内容。如果是,返回一个空的结果。否则,正常处理这个请求。 -
把你的代码和依赖放到一个JAR 文件中。
-
把这个JAR放到 HBase可以找到它的HDFS中。
-
加载这个 Coprocessor.
-
写一个简单的程序测试它。
以下是上面步骤的实现:
public class RegionObserverExample extends BaseRegionObserver { private static final byte[] ADMIN = Bytes.toBytes("admin"); private static final byte[] COLUMN_FAMILY = Bytes.toBytes("details"); private static final byte[] COLUMN = Bytes.toBytes("Admin_det"); private static final byte[] VALUE = Bytes.toBytes("You can't see Admin details"); @Override public void preGetOp(final ObserverContext e, final Get get, final List results) throws IOException { if (Bytes.equals(get.getRow(),ADMIN)) { Cell c = CellUtil.createCell(get.getRow(),COLUMN _FAMILY, COLUMN, System.currentTimeMillis(), (byte)4, VALUE); results.add(c); e.bypass(); } List kvs = new ArrayList(results.size()); for (Cell c : results) { kvs.add(KeyValueUtil.ensureKeyValue(c)); } preGet(e, get, kvs); results.clear(); results.addAll(kvs); } }
覆盖preGetOp() 将只针对Get操作有效。你还需要覆盖 preScannerOpen() 方法从scan的结果中过滤 admin 行。
@Override public RegionScanner preScannerOpen(final ObserverContext e, final Scan scan, final RegionScanner s) throws IOException { Filter filter = new RowFilter(CompareOp.NOT_EQUAL, new BinaryComparator(ADMIN)); scan.setFilter(filter); return s; }
这个方法会有副作用。如果客户端在它的scan中使用了一个过滤器,则客户端的过滤器会被 preScannerOpen()方法中的过滤器替代。这种情况下,覆盖preScannerOpen()的替代方法是,显示地从扫描结果中移除任何 admin 的结果:
@Override public boolean postScannerNext(final ObserverContext e, final InternalScanner s, final List results, final int limit, final boolean hasMore) throws IOException { Result result = null; Iterator iterator = results.iterator(); while (iterator.hasNext()) { result = iterator.next(); if (Bytes.equals(result.getRow(), ROWKEY)) { iterator.remove(); break; } } return hasMore; }
89.2. Endpoint Example
仍然使用 users 表, 这个例子实现了一个协处理器去计算所有员工收入的总和,使用了一个Endpoint Coprocessor.
-
创建一个 '.proto' 文件定义你的服务。
option java_package = "org.myname.hbase.coprocessor.autogenerated"; option java_outer_classname = "Sum"; option java_generic_services = true; option java_generate_equals_and_hash = true; option optimize_for = SPEED; message SumRequest { required string family = 1; required string column = 2; } message SumResponse { required int64 sum = 1 [default = 0]; } service SumService { rpc getSum(SumRequest) returns (SumResponse); }
-
执行
protoc命令从以上的.proto中生成Java代码。$ mkdir src $ protoc --java_out=src ./sum.proto
这将生成一个java类
Sum.java. -
写一个类去继承这个生成的service类,实现
Coprocessor和CoprocessorService类, 并且覆盖service()方法。
如果你从 hbase-site.xml加载一个协处理器,然后使用HBase Shell加载一个同名的协处理器,它会被第二次加载。相同的类会存在两次,第二个实例将会有一个更高的ID (因此优先级更低). 其结果是,复制的coprocessor实际上被忽略了。public class SumEndPoint extends SumService implements Coprocessor, CoprocessorService { private RegionCoprocessorEnvironment env; @Override public Service getService() { return this; } @Override public void start(CoprocessorEnvironment env) throws IOException { if (env instanceof RegionCoprocessorEnvironment) { this.env = (RegionCoprocessorEnvironment)env; } else { throw new CoprocessorException("Must be loaded on a table region!"); } } @Override public void stop(CoprocessorEnvironment env) throws IOException { // do mothing } @Override public void getSum(RpcController controller, SumRequest request, RpcCallback done) { Scan scan = new Scan(); scan.addFamily(Bytes.toBytes(request.getFamily())); scan.addColumn(Bytes.toBytes(request.getFamily()), Bytes.toBytes(request.getColumn())); SumResponse response = null; InternalScanner scanner = null; try { scanner = env.getRegion().getScanner(scan); List results = new ArrayList(); boolean hasMore = false; long sum = 0L; do { hasMore = scanner.next(results); for (Cell cell : results) { sum = sum + Bytes.toLong(CellUtil.cloneValue(cell)); } results.clear(); } while (hasMore); response = SumResponse.newBuilder().setSum(sum).build(); } catch (IOException ioe) { ResponseConverter.setControllerException(controller, ioe); } finally { if (scanner != null) { try { scanner.close(); } catch (IOException ignored) {} } } done.run(response); } } Configuration conf = HBaseConfiguration.create(); // Use below code for HBase version 1.x.x or above. Connection connection = ConnectionFactory.createConnection(conf); TableName tableName = TableName.valueOf("users"); Table table = connection.getTable(tableName); //Use below code HBase version 0.98.xx or below. //HConnection connection = HConnectionManager.createConnection(conf); //HTableInterface table = connection.getTable("users"); final SumRequest request = SumRequest.newBuilder().setFamily("salaryDet").setColumn("gross") .build(); try { Map<byte[], Long> results = table.CoprocessorService (SumService.class, null, null, new Batch.Call<SumService, Long>() { @Override public Long call(SumService aggregate) throws IOException { BlockingRpcCallback rpcCallback = new BlockingRpcCallback(); aggregate.getSum(null, request, rpcCallback); SumResponse response = rpcCallback.get(); return response.hasSum() ? response.getSum() : 0L; } }); for (Long sum : results.values()) { System.out.println("Sum = " + sum); } } catch (ServiceException e) { e.printStackTrace(); } catch (Throwable e) { e.printStackTrace(); }
-
加载这个 Coprocessor.
-
写一个客户端代码去调用这个 Coprocessor.
90. 部署协处理器的指导方针 Guidelines For Deploying A Coprocessor
- 捆绑协处理器 Bundling Coprocessors
-
你可以将一个coprocessor的所有类捆绑到RegionServer的classpath中的单个JAR中,以便进行简单的部署。否则,将所有依赖项放在RegionServer的classpath中,以便在RegionServer启动时加载它们。一个RegionServer的classpath在RegionServer的
hbase-env.sh文件中被设置。 - 自动部署 Automating Deployment
-
你可以使用工具如 Puppet, Chef, 或 Ansible 把协处理器的JAR传到你的RegionServer的文件系统中所需的位置,重启每一个RegionServer,以使协处理器自动部署。此类设置的细节超出了本文的范围。
- 更新一个协处理器 Updating a Coprocessor
-
部署一个给定的coprocessor的新版本并不像禁用它、替换JAR并重新启用协处理器那样简单。这是因为你不能在JVM中重新加载一个类,除非你删除了所有的对它当前的引用。既然当前JVM引用了这个已经存在的协处理器,你必须通过重启RegionServer来重启这个JVM,以替代这个协处理器。这种行为是不可能改变的。
- 协处理器日志 Coprocessor Logging
-
Coprocessor框架不提供超出标准Java日志记录的API。
- 协处理器配置 Coprocessor Configuration
-
如果你不想从HBase Shell里加载 coprocessors,你可以把它们的配置属性加到
hbase-site.xml中。在 Using HBase Shell中,两个参数被设置为:arg1=1,arg2=2. 这些参数按照以下方式添加到hbase-site.xml中:<property> <name>arg1</name> <value>1</value> </property> <property> <name>arg2</name> <value>2</value> </property>
然后你可以使用如下代码读取这个配置信息:
Configuration conf = HBaseConfiguration.create(); // Use below code for HBase version 1.x.x or above. Connection connection = ConnectionFactory.createConnection(conf); TableName tableName = TableName.valueOf("users"); Table table = connection.getTable(tableName); //Use below code HBase version 0.98.xx or below. //HConnection connection = HConnectionManager.createConnection(conf); //HTableInterface table = connection.getTable("users"); Get get = new Get(Bytes.toBytes("admin")); Result result = table.get(get); for (Cell c : result.rawCells()) { System.out.println(Bytes.toString(CellUtil.cloneRow(c)) + "==> " + Bytes.toString(CellUtil.cloneFamily(c)) + "{" + Bytes.toString(CellUtil.cloneQualifier(c)) + ":" + Bytes.toLong(CellUtil.cloneValue(c)) + "}"); } Scan scan = new Scan(); ResultScanner scanner = table.getScanner(scan); for (Result res : scanner) { for (Cell c : res.rawCells()) { System.out.println(Bytes.toString(CellUtil.cloneRow(c)) + " ==> " + Bytes.toString(CellUtil.cloneFamily(c)) + " {" + Bytes.toString(CellUtil.cloneQualifier(c)) + ":" + Bytes.toLong(CellUtil.cloneValue(c)) + "}"); } }
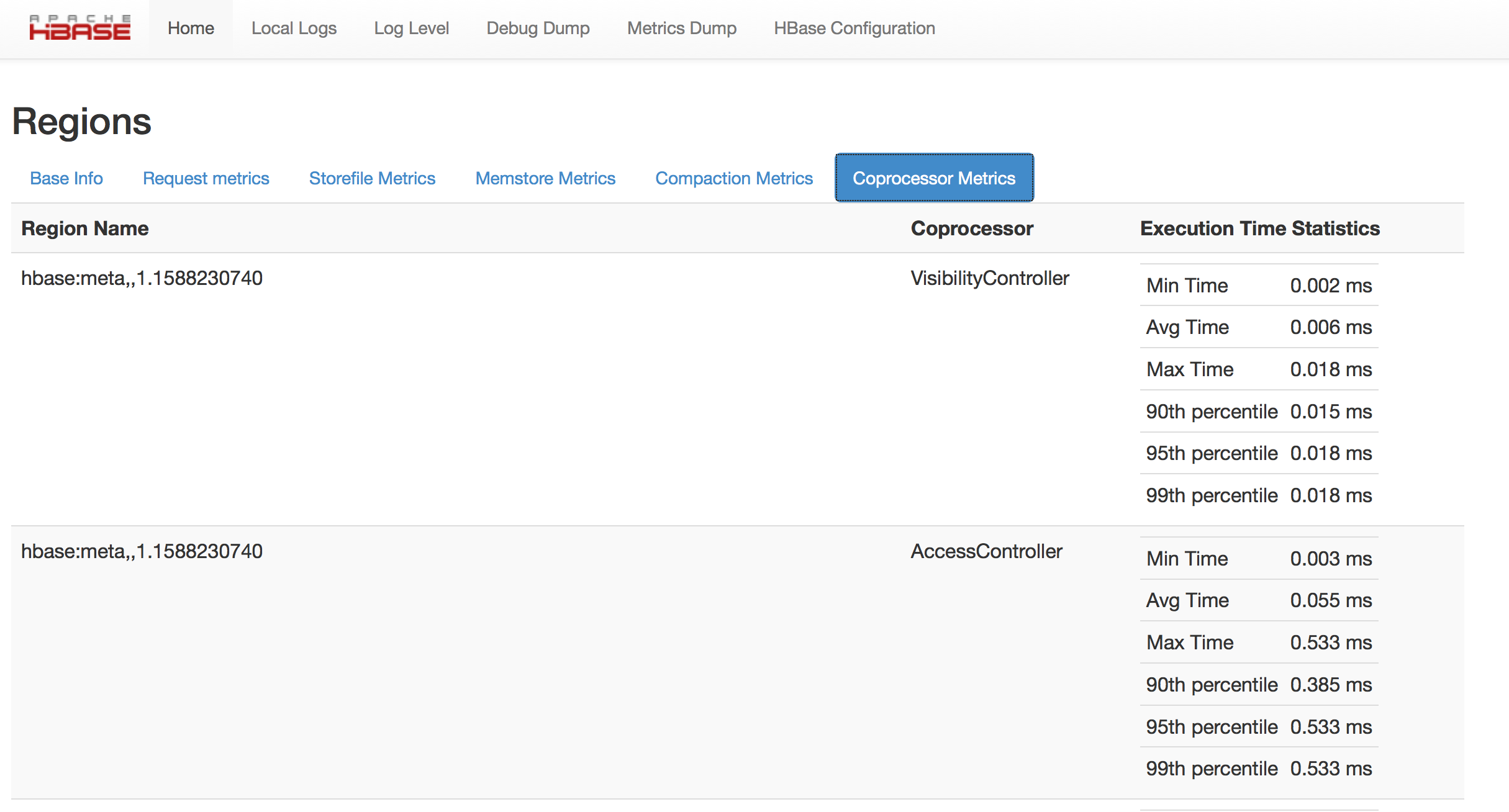
91. 监控在协处理器中花费的时间 Monitor Time Spent in Coprocessors
HBase 0.98.5 可以监控一些和执行一个给定的Coprocessor所花费时间量有关的统计数据。你可以在HBase Metrics框架(参考HBase Metrics)或者 Web UI中给定的RegionServer的Coprocessor Metrics tab中看到这些统计数据。这些统计数据对于在集群中对给定的Coprocessor的性能影响进行调试和基准测试是很有价值的。跟踪的统计数据包括min、max、average(平均)、第90、第95、第99百分位。所有的时间以毫秒显示。统计数据是根据 在报告间隔期间记录的Coprocessor执行样本 进行计算的,这个报告间隔期间默认情况下是10秒。度量采样率在HBase Metrics中描述。