
众所周知,Kubernetes 是一个容器编排平台,它有非常丰富的原始的 API 来支持容器编排,但是对于用户来说更加关心的是一个应用的编排,包含多容器和服务的组合,管理它们之间的依赖关系,以及如何管理存储。
在这个领域,Kubernetes 用 Helm 的来管理和打包应用,但是 Helm 并不是十全十美的,在使用过程中我们发现它并不能完全满足我们的需求,所以在 Helm 的基础上,我们自己研发了一套编排组件……
什么是编排?
不知道大家有没仔细思考过编排到底是什么意思? 我查阅了 Wiki 百科,了解到我们常说的编排的英文单词为 “Orchestration”,它常被解释为:
- 本意:为管弦乐中的配器法,主要是研究各种管弦乐器的运用和配合方法,通过各种乐器的不同音色,以便充分表现乐曲的内容和风格。
- 计算机领域:引申为描述复杂计算机系统、中间件 (middleware) 和业务的自动化的安排、协调和管理。
有趣的是 “Orchestration” 的标准翻译应该为“编配”,而“编排”则是另外一个单词 “Choreography”,为了方便大家理解, 符合平时的习惯,我们还是使用编排 (Orchestration) 来描述下面的问题。至于“编配 (Orchestration)” 和 “编排(Choreography)” 之争,这里有一篇文章,有兴趣可以看一下 。
编配和编排的定义之争www.infoq.com
Kubernetes 容器编排技术
当我们在说容器编排的时候,我们在说什么?
在传统的单体式架构的应用中,我们开发、测试、交付、部署等都是针对单个组件,我们很少听到编排这个概念。而在云的时代,微服务和容器大行其道,除了为我们显示出了它们在敏捷性,可移植性等方面的巨大优势以外,也为我们的交付和运维带来了新的挑战:我们将单体式的架构拆分成越来越多细小的服务,运行在各自的容器中,那么该如何解决它们之间的依赖管理,服务发现,资源管理,高可用等问题呢?
在容器环境中,编排通常涉及到三个方面:
- 资源编排 - 负责资源的分配,如限制 namespace 的可用资源,scheduler 针对资源的不同调度策略;
- 工作负载编排 - 负责在资源之间共享工作负载,如 Kubernetes 通过不同的 controller 将 Pod 调度到合适的 node 上,并且负责管理它们的生命周期;
- 服务编排 - 负责服务发现和高可用等,如 Kubernetes 中可用通过 Service 来对内暴露服务,通过 Ingress 来对外暴露服务。
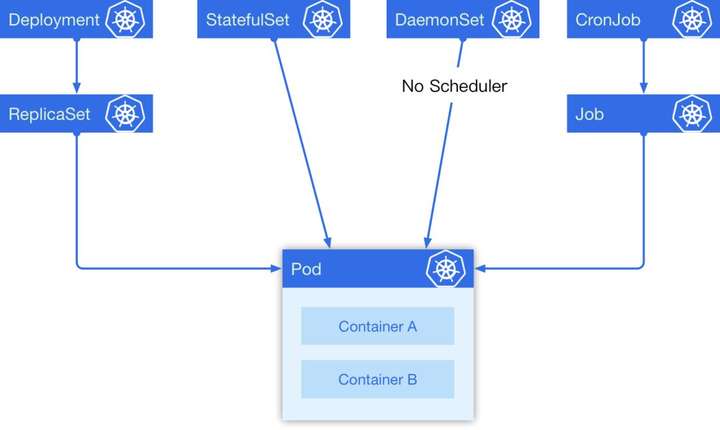
在 Kubernetes 中有 5 种我们经常会用到的控制器来帮助我们进行容器编排,它们分别是 Deployment, StatefulSet, DaemonSet, CronJob, Job。
在这 5 种常见资源中,Deployment 经常被作为无状态实例控制器使用; StatefulSet 是一个有状态实例控制器; DaemonSet 可以指定在选定的 Node 上跑,每个 Node 上会跑一个副本,它有一个特点是它的 Pod 的调度不经过调度器,在 Pod 创建的时候就直接绑定 NodeName;最后一个是定时任务,它是一个上级控制器,和 Deployment 有些类似,当一个定时任务触发的时候,它会去创建一个 Job ,具体的任务实际上是由 Job 来负责执行的。他们之间的关系如下图:
一个简单的例子
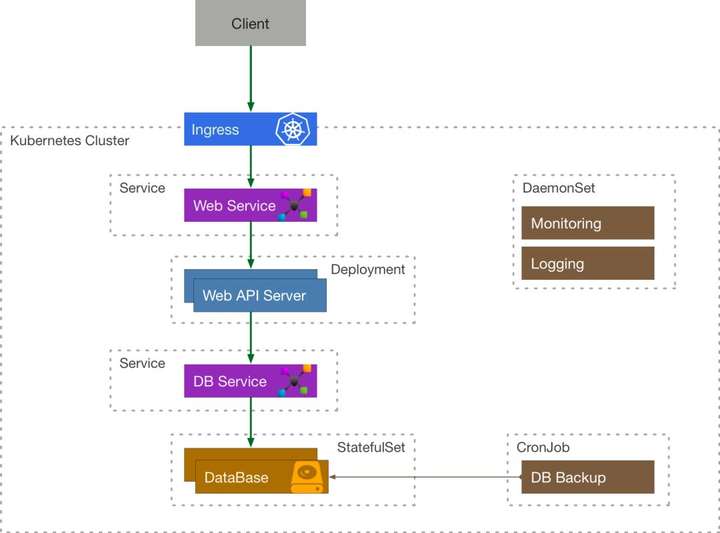
我们来考虑这么一个简单的例子,一个需要使用到数据库的 API 服务在 Kubernetes 中应该如何表示:
客户端程序通过 Ingress 来访问到内部的 API Service, API Service 将流量导流到 API Server Deployment 管理的其中一个 Pod 中,这个 Server 还需要访问数据库服务,它通过 DB Service 来访问 DataBase StatefulSet 的有状态副本。由定时任务 CronJob 来定期备份数据库,通过 DaemonSet 的 Logging 来采集日志,Monitoring 来负责收集监控指标。
容器编排的困境
Kubernetes 为我们带来了什么?
通过上面的例子,我们发现 Kubernetes 已经为我们对大量常用的基础资源进行了抽象和封装,我们可以非常灵活地组合、使用这些资源来解决问题,同时它还提供了一系列自动化运维的机制:如 HPA, VPA, Rollback, Rolling Update 等帮助我们进行弹性伸缩和滚动更新,而且上述所有的功能都可以用 YAML 声明式进行部署。
困境
但是这些抽象还是在容器层面的,对于一个大型的应用而言,需要组合大量的 Kubernetes 原生资源,需要非常多的 Services, Deployments, StatefulSets 等,这里面用起来就会比较繁琐,而且其中服务之间的依赖关系需要用户自己解决,缺乏统一的依赖管理机制。
应用编排
什么是应用?
一个对外提供服务的应用,首先它需要一个能够与外部通讯的网络,其次还需要能运行这个服务的载体 (Pods),如果这个应用需要存储数据,这还需要配套的存储,所以我们可以认为:
应用单元 = 网络 + 服务载体 +存储
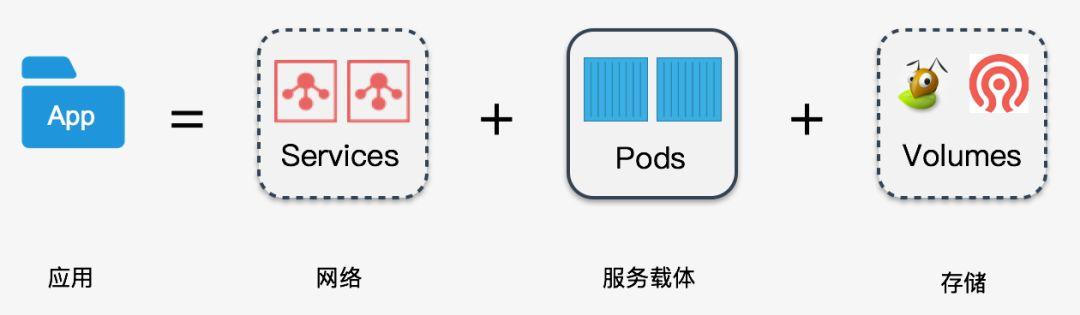
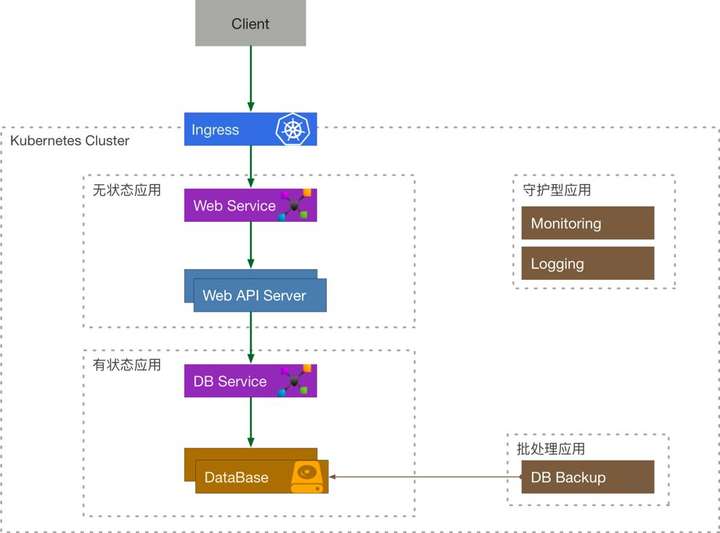
那么我们很容易地可以将 Kubernetes 的资源联系起来,然后将他们划分为 4 种类型的应用:
- 无状态应用 = Services + Volumes + Deployment
- 有状态应用 = Services + Volumes + StatefulSet
- 守护型应用 = Services + Volumes + DaemonSet
- 批处理应用 = Services + Volumes + CronJob/Job
我们来重新审视一下之前的例子:
应用层面的四个问题
通过前面的探索,我们可以引出应用层面的四个问题:
- 应用包的定义
- 应用依赖管理
- 包存储
- 运行时管理
在社区中,这四个方面的问题分别由三个组件或者项目来解决:
- Helm Charts: 定义了应用包的结构以及依赖关系;
- Helm Registry: 解决了包存储;
- HelmTiller: 负责将包运行在 Kubernetes 集群中。
Helm Charts
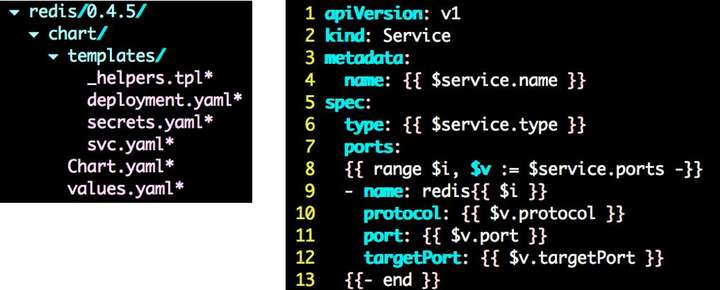
Charts 在本质上是一个 tar 包,包含了一些 yaml 的 template 以及解析 template 需要的 values, 如下图:templates 是 Golang 的 template 模板,values.yaml 里面包含了这个 Charts 需要的值。
Helm Registry
用来负责存储和管理用户的 Charts, 并提供简单的版本管理,与容器领域的镜像仓库类似这个项目是开源的。( https://github.com/caicloud/helm-registry)
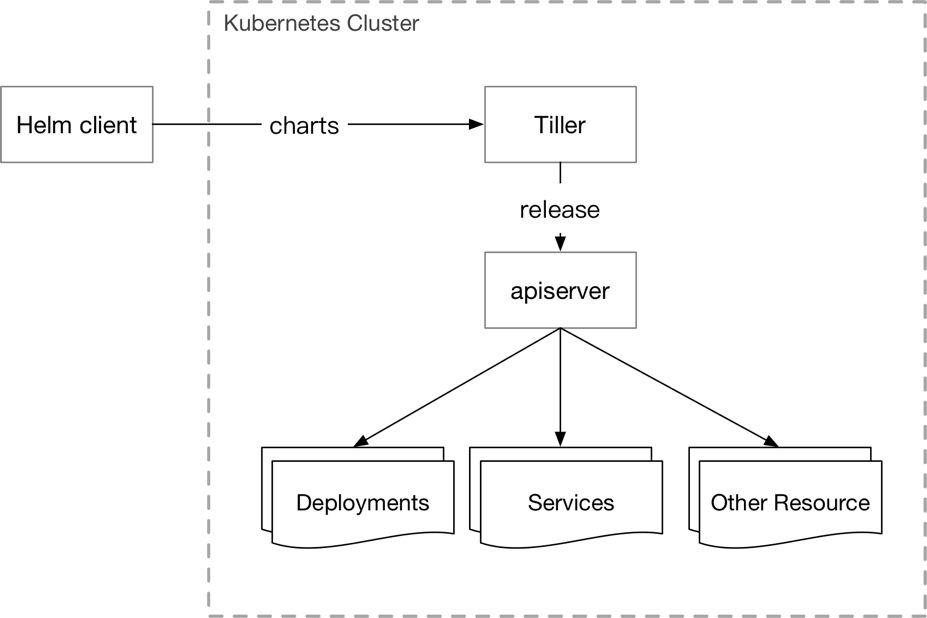
Tiller
- 负责将 Chart 部署到指定的集群当中,并管理生成的 Release (应用);
- 支持对 Release 的更新,删除,回滚操作;
- 支持对 Release 的资源进行增量更新;
- Release 的状态管理;
- Kubernetes下属子项目(https://github.com/kubernetes/helm) 。
Tiller 的缺陷
- 没有内建的认知授权机制,Tiller 跑在 kube-system 分区下,拥有整个集群的权限;
- Tiller 将 Release 安装到 Kubernetes 集群中后并不会继续追踪他们的状态;
- Helm+Tiller的架构并不符合 Kubernetes 的设计模式,这就导致它的拓展性比较差;
- Tiller 创建的 Release 是全局的并不是在某一个分区下,这就导致多用户/租户下,不能进行隔离;
- Tiller 的回滚机制是基于更新的,每次回滚会使版本号增加,这不符合用户的直觉。
Release Controller
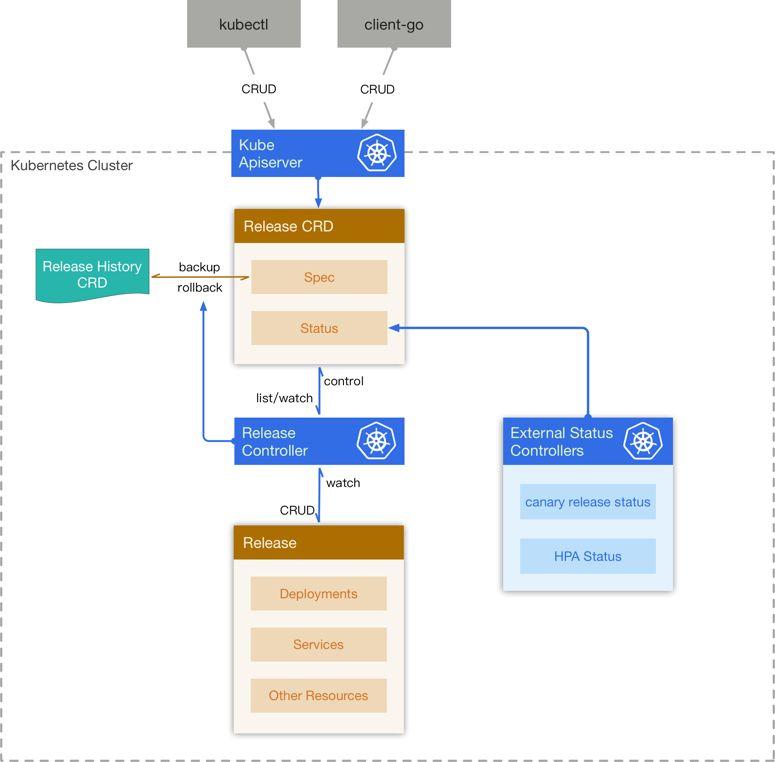
为了解决上述的问题,我们基于 Kubernetes 的 Custom Resource Definition 设计并实现了我们自己的运行时管理系统 – Release Controller, 为此我们设计了两个新的 CRD – Release 和 Release History。
Release 创建
当 Release CRD 被创建出来,controller 为它创建一个新的 Release History, 然后将 Release 中的 Chart 和 Configuration 解析成 Kubernetes 的资源,然后将这些资源在集群中创建出来,同时会监听这些资源的变化,将它们的状态反映在 Release CRD 的 status 中。
Release 更新
当用户更新 Release 的时候,controller 计算出更新后的资源与集群中现有资源的 diff, 然后删除一部分,更新一部分,创建一部分,来使得集群中的资源与 Release 描述的一致,同时为旧的 Release 创建一份 Release History。
Release 回滚和删除
用户希望回滚到某一个版本的 Release, controller 从 Release History 中找到对应的版本,然后将 Release 的 Spec 覆盖,同时去更新集群中对应的资源。当 Release 被删除后,controller 将它关联的 Release History 删除,同时将集群中的其他资源一并删除。
架构图
这样的设计有什么好处?
- 隔离性:资源使用 Namespace 隔离,适应多用户/租户;
- 可读性:Release Controller 会追踪每个 Release 的子资源的状态;
- 版本控制:你可以很容易地会退到某一个版本;
- 拓展性:整个架构是遵循 Kubernetes 的 controller pattern,具有良好的可扩展性,可以在上面进行二次开发;
- 安全性:因为所有的操作都是基于 Kubernetes 的 Resource,可以充分利用 Kubernetes 内建的认证鉴权模块,如 ABAC, RBAC 。
总而言之,编排不仅仅是一门技术也是一门艺术!谢谢!