第二章
main()函数:
- 通常main()被启动码调用,而启动码是由编译器添加到程序中的,是程序和操作系统之间的桥梁。
- main()函数在返回时没有遇到返回语句,则默认以
return 0
结尾。
C和C++有一项不同寻常的特征——可以连续使用赋值运算符。(Python也可以)
第三章
整形:
- short 至少16位
- int 至少比short长
- long 至少32位
- long long 至少64位
sizeof (int)返回类型的长度,sizeof VAR返回变量的长度,可选括号。
climits定义了符号常量来表示类型的限制。
C++允许初始化语句:
int wrens(432)
申明的变量不赋值,将会指向一个不确定的值。
整形字面值:
- 第一位为1~9,十进制
- 第一位为0,8进制
- 第一位为0x/0X,十六进制
cout对象默认输出转为十进制。
头文件iostream提供了控制符endl(换行)、dec(十进制)、hex(十六进制)、oct(八进制)。
int A = 0x42; cout << hex; cout << A;
int被设置为目标计算机的自然长度。
C++默认将整型常量(不是太大)存储为int类型(除非有后缀:l/L, u/U(无符号整形), LU, C++11(LL,ULL)(注:不区分大小写))。
十进制与十六进制/八进制默认存储不同:
对于不带后缀的十进制整数,用能够存储该整数的最小类型存储(int, long, long long)
对于不带后缀的十六进制或八进制整数使用(int, unsigned int, long, unsigned long, long long, unsigned long long)
char 类型:
避免控制台输出后秒退:
1. cin.get()
2. system("pause")
一个历史遗留问题:
为什么会有cout.put()函数?
在C++ Release 2.0之前cout将字符变量显示为字符,而字符常量显示为数字(存储为int类型)。
char ch = 'M';
常量‘M’中复制8位(左边8位)到ch中。
可以基于字符的8进制或16进制ASCII编码来使用转义序列。
cin和cout将输入和输出看作是char流,因此不适合处理wchar_t类型,iostream头文件的最新版本提供了wcin和wcout,可用于处理wchar_t流(L作为前缀)。
浮点数:
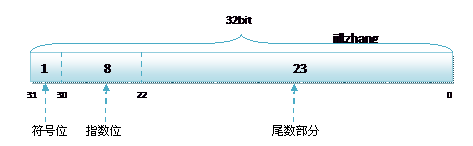
单精度或双精度在存储中,都分为三个部分:
符号位 (Sign):0代表正数,1代表为负数;
指数位 (Exponent):用于存储科学计数法中的指数数据;
尾数部分 (Mantissa):采用移位存储尾数部分;
浮点常量默认为double类型,后缀F表示单精度,后缀L表示long double。
【以下内容取自网络】
单精度 float 的存储方式如下:
8.5,用二进制的科学计数法表示为:1.0001*![]()
按照上面的存储方式,符号位为:0,表示为正,指数位(移码)为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示(IEEE754浮点数编码):
双精度 double 的存储方式如下:
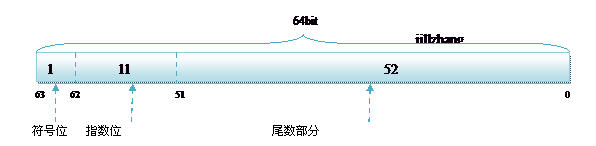
阶码的移码的偏移量为127,一般的移码为符号位取反的补码(即偏移量为128)。
为什么要用移码?
方便计算机浮点数大小的比较。
阶码的移码的偏移量为127?
因为阶码的0000 0000和1111 1111都有特殊用途,因此阶码的移码取值范围限定为1~254,偏移量为128的话,原码0111 1111(127)溢出。
阶码原码的取值范围?
原码为1111 1111(-127)时,偏移量为127时移码明显会产生下溢;补码1000 0000为-128的补码,加127的偏移时依然会产生下溢。因此阶码原码的取值范围为-126~127。
IEEE754浮点数的取值范围?
1*(2)^(-126) ~ 2*(2)^127(1.111 1111 11111 1111 1111 1111 = 1+1/2*(1-(1/2)23)/(1/2)近似于2)。
十进制浮点数的精度(有效位数)?
-log(10)(2^-23) = 6.924。
double的有效位为16位。
C++算术运算符
整型提升:
C++在计算时,自动将int以下的整型转换为int类型进行计算,之后再赋值到各自的类型。
两种不同整型操作时,自动归一到大整型(两种不同类型之间操作时同样遵守这一规则)。
强制类型转换:
(long) thorn (C语言风格)
long (thorn)