正则表达式
是一种小型的、高度专业化的编程语言,它内嵌在python中,并通过re模块实现。
a、可以为想要匹配的相应字符串集指定规则
b、该字符串集可能包含英文语句、e-mail地址、命令或任何你先搞定的东西
c、可以问诸如“这个字符串匹配该模式吗?”
d、也可以使用re以各种方式来修改或分割字符串
e、正则表达式模式被编译成一系列的字节码,然后由C编写的匹配引擎执行
f、正则表达式语言相对小型和受限(并非所有的字符串处理都能用正则表达式完成)
1、元字符
- []
常用来指定一个字符集:[abc]、[a-z]
元字符在字符集中不起作用:[akm$]
补集匹配不在区间范围内的字符:[^5]
- ^:
匹配首行。除非设置MULTILINE标志,它只是匹配字符串的开始。在MULTILINE模式 里,它也可以直接匹配字符串中的每个换行。
如果^在行首,表示匹配以什么开头的,如果^在[]中,则表示取反
- $
匹配行尾,行尾被定义为要么是字符串尾,要么是一个换行字符后面的任何位置。
- :转义字符:
用于将元字符转化成普通的符号
反斜杠后面可以加不同的字符以表示不同特殊意义
d:匹配十进制数,相当于[0-9]
D:匹配任何非数字字符,相当于[^0-9]
s:匹配任何空白字符,相当于[ fv]
S:匹配任何非空白字符,相当于[^ fv]
w:匹配任何字母数字字符,相当于[0-9a-zA-Z]
W:匹配任何非字母数字字符,相当于[^0-9a-zA-Z]
- 重复
正则表达式第一个功能是能够匹配不定长的字符集,另一个功能就是可以指定正则表达式 的一部分的重复次数
d{8}:表示将前面的规则重复8次
{m,n}:表示至少有m个重复,至多有n个重复。{0,}相当于*,{1,}相当于+,{0,1}相当于?。一般尽量使用*,+或?。
- *
指定前一个字符可以被匹配零次或更多次,而不是只有一次。匹配引擎会试着重复尽可能 多的次数。a[abc]*b
- +
表示匹配一次或更多次
- ?
匹配一次或零次,可用于标识某事物是可选的
实例:
import re
#解释型正则表达式
s = r"^d{3,4}-?d{8}$"
string = "010-12345678"
print(re.findall(s, string))
#编译型正则表达式(速度快)
s1 = re.compile(s)
print(s1.findall(string))
2、执行匹配
a、‘RegexObject’实例有一些方法和属性,主要列举如下:
match():决定re是否在字符串刚开始的位置匹配,如果没有匹配返回None,否则返回一个‘Matchobject’对象
search():扫描字符串,找到re匹配的位置,如果没有匹配返回None,否则返回一个‘Matchobject’对象
findall():找到re匹配的所有子串,并把它们作为一个列表返回
finditer():找到re匹配的所有子串,并把它们作为一个迭代器返回
b、‘MatchObject’
group():返回被re匹配的字符串
start():返回匹配开始的位置
end():返回匹配结束的位置
span():返回一个元组包含匹配(开始,结束)的位置
ps:实际程序中,最常见的做法是将'MatchObject'保存在一个变量里,然后检查它是否为None,再调用其内部方法
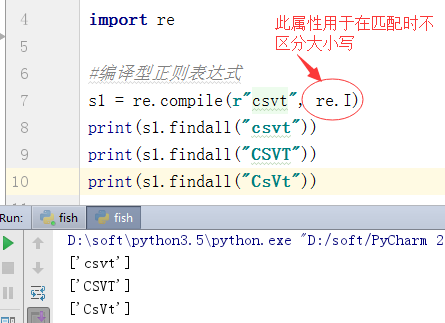
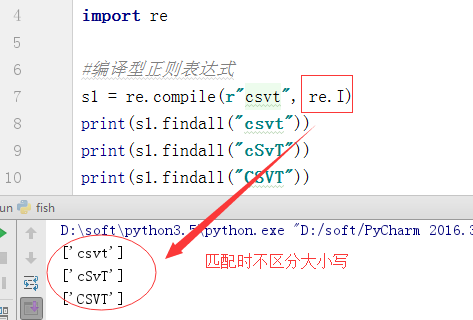
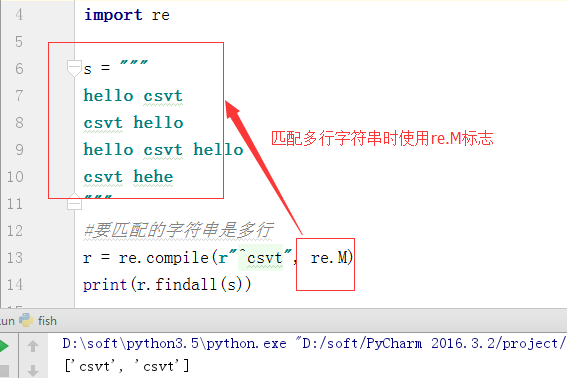
3、编译标志-flag
a、DOTALL,S:使.匹配包括换行在内的所有字符
b、IGNORECASE,I:使匹配对大小写不敏感
c、LOCAL,L:做本地化识别(local-aware)匹配
d、MULTILINE,M:多行匹配,影响^和$(匹配多行字符串)
e、VERBOSE,X:能够使用REs的verbose状态,使之被组织得更清晰易懂(匹配多行正则表达式)
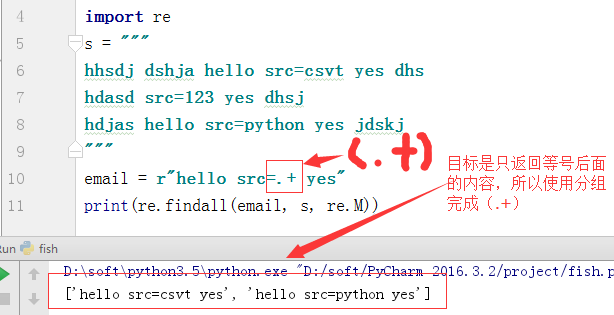
4、分组
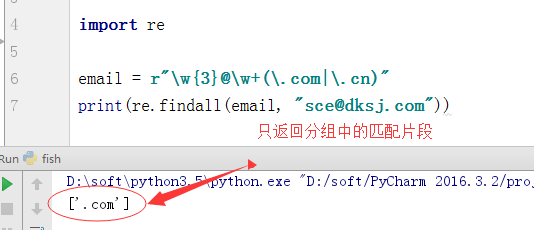
a、进行邮箱匹配时:email = r"w{3}@w+(.com|.cn)"
b、分组会优先返回分组中的匹配片段
5、使用正则表达式实现一个小爬虫
注:.*?:实现最小贪婪匹配
import re
import urllib.request
#通过网页地址获取网页源码
def getHtml(url):
page = urllib.request.urlopen(url) #打开网页,返回一个页面对象
html = page.read() #从page对象中获取所有数据
return html
#利用正则表达式从源码中找到所有图片的地址
def getImgUrl(html):
#定义正则老匹配页面,使用元组只获得地址。.*?:最小贪婪匹配
reg = r'src="(https://imgsa.baidu.com/forum/.*?/sign=.*?.jpg)"'
imgre = re.compile(reg)
imgList = re.findall(imgre, html.decode())
x = 0
for imgurl in imgList:
urllib.request.urlretrieve(imgurl, 'F:/%s.jpg' % x) #下载指定地址的内容
x += 1
html = getHtml("https://tieba.baidu.com/p/4704719514")
getImgUrl(html)